Long-form Articles
I try to save up thoughts for days or weeks to build into one of these Piles of Related Thoughts (poreths?), somewhat dressed up. Some of these also describe a project underway.


Long-form Articles
I try to save up thoughts for days or weeks to build into one of these Piles of Related Thoughts (poreths?), somewhat dressed up. Some of these also describe a project underway.


The new extension by @tobyshorin and @tomcritchlow is textbook. Hypertextbook.
You might think that the Quotebacks extension - for being a piece of rather simple tech - is being talked about enough already. But I think we need to slow down and look at this closer. (Are we few? Those remaining Web devotees…)
And, yes, the website says that Quotebacks does three things. But I’m just going to talk about it as if it did one thing: gives people a common format for embedding quoted stuff.
Looks like this:
Fuck that. I'm more of an editor than a developer any day, but I'll be damned if I'm going to cede that territory. I dont want to pour my words into a box, the parameters of which someone else decides (and obscures). I want to make the box, too. And remake it. And, hell, break it from time to time. It's mine to break.
Select the text. Copy it into the extension. And it’ll give you embed tags. (Much like YouTube does for embedding videos or Twitter does for embedding tweets.)
So. This is a cool extension - but also very sneaky and strategic. Something like this can actually draw people back to the Web. A bit of stylistic appeal paired with some subconscious luring.
The primary advocacy strategy on the Web for the last ten years seems to have been to write a blog post saying, “Hey, stop what you’re doing and write blog posts!” Unfortunately that offers nothing appealing to offset the risk of blogging on a seemingly empty Web. Especially for people who tried blogging already. (“Come on - I swear - people are still out here!!”)
Think of the appeal of ‘likes’ on social media. There was a lot of excitement around this kind of participation. Hey, likes - I could do that! I could get some likes! At the very least, I could give out a few - and I might get some back. Great!
A quoteback is a like, too, actually. It’s just a full paragraph one.
Likes are the most atomic way - the most basic way - of participating in social media. And perhaps the quoteback is the most atomic form of participation on the Web.
This suggests that people are quoting each other a lot on the Web.[1] This suggests that you will be quoting others and they will be quoting you.[2] There is an automatic action implied - a subconscious luring - that one should begin by reading. By finding quotes to quote.
And I think this is an excellent mindset to be in.[3]
Furthermore, this positions the Web as a container. The Web has already become a place to embed other network content. You don’t embed social networks into each other - you embed into HTML. This makes the Web a wrapper for every other kind of network. And the glue between networks.
Quotebacks can fabricate an image for social networks. Check it out.
An acute reminder of hypertext sterilization on those Webs.
So, sure, go to the social networks to do detail work and messaging. But come back out to the Web to assemble it all into more encompassing creations. Essays, guides, journals and such.
The novel styling of quotebacks is not immaterial. The elegant formatting - and even the slight hover effect - creates desire to be quoted. Just as reading a book with gorgeous typesetting and paper aroma alone fills one with desire to write. (“This book sucks - but I can almost picture the book that might live up to a binding of this quality…”) The styling gives the Web texture and physical appeal that it is distinctly lacking.
If the Web is going to be treated as a place to drop embeds, this extension embraces that. Here are some more good-lookin’ embeds for ya.
And I actually hope that quotebacks become a more general thing. Imagine if you could snip video or podcast segments and spit out a block that is also recognizable as a quoteback. The Web contains and wraps those fragments, seeds in its garden.
Now, of course, I’m raving about something that is truly quite simple.
Am I dense? I'm still at such a loss on the https://quotebacks.net thing that I feel like I must be missing something. I don't feel like "blockquotes don't have a fancy, common-design embed like tweets and grams do" is some sort of pressing obstacle for blogging?
Isn’t this just a quotation or citation? Haven’t these been around for centuries? Can’t I just use the blockquote?
Absolutely. I, personally, am sticking to the blockquote - because I already have a convention going for myself.
But it’s still appealing. This is inviting me to do something that I’m already doing. In a way, the fact that this is such a slight change - so simple and familiar - just tweak your copy-and-paste to get some slight advantage - almost guarantees that it will do well.
Anyway - I applaud this strategy. Creating new protocols for the Web is cool - but it implies more work for everyone. If you can help modernize the existing Web by adding tools that enhance it as a container, that encourage reading and which perhaps offer a way of understanding what it means to participate here - seems exquisite, right?
Or, specifically, in blogging or expert wiki-ing or ‘networked writing’ as Critchlow puts it. ↩︎
Which is already somewhat the format of e-mails, though it’s unnatural to quote different sources there. ↩︎
With so many networks focused on tool for creation - here are the ways you can use videos, use stickers, filter yourself, sprinkle yourself with three-dimensional face dust, lower your pitch, tag yourself - I think it’s a smart counter-strategy to swing the other direction - here is something you can do with what someome else has said. Begin by reading, not by pressing REC. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
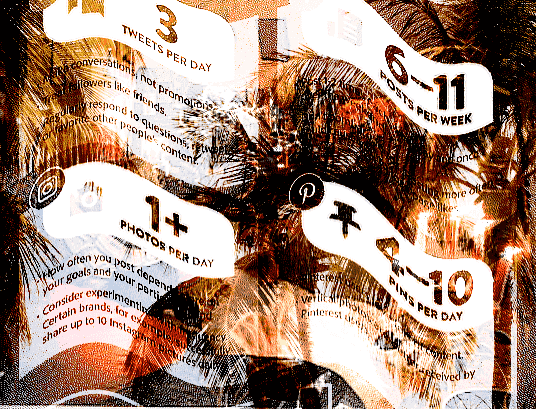
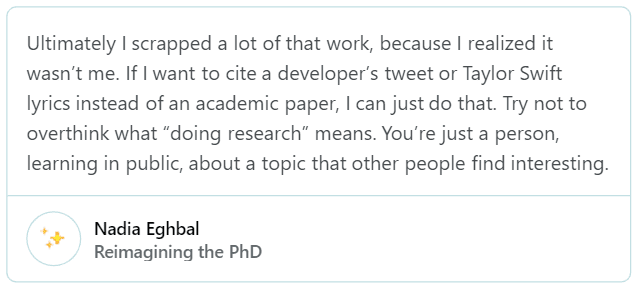
How frequently should you post to keep pace with the next decade?
Posting every day — multiple times a day — is indispensable. This is one of the main factors the Instagram algorithm uses to determine how much they are going to expose you to the public (via the “explore page”). Posting every day, especially at “rush hour” times, is much harder and more monotonous than you might think. Most people give up on this task after a few weeks, and even missing a day or two can be detrimental. So, I automated the content collecting and sharing process.
— Chris Buetti, “How I Eat For Free in NYC Using Python, Automation, Artificial Intelligence, and Instagram”
Facebook posts reach their half-life at the 90-minute mark, nearly four times longer than Twitter.
— Buffer’s “Social Media Frequency Guide”
Consistency. Asking friends who work in social media and marketing, this is the current dominant advice - for both ‘influencer’ types and DIY creators. This word seems to be everything right now.
The implication is that you should post frequently, with as much quality as you can muster, to stay relevant. Otherwise, you’ll drop off the end as new ‘content’ crowds it out. And this is happening all day.
The fact that they only post twice a week sheds light on their poor performance. While Nike is a cool brand, their social media content’s infrequencies are taking a toll.
— Dash Hudson, “The Truth About How Often You Should Be Posting on Instagram”
This is an artifact of how social media platforms are constructed. It doesn’t benefit the writer to need to focus on consistency over quality, does it? So does it benefit the reader?
It benefits the platform. And, at this point, there are many different platforms, all demanding your ‘consistency’.
Post to Twitter at least 5 times a day. If you can swing up to 20 posts, you might be even better off.
Post to Facebook five to 10 times per week.
Post to LinkedIn once per day. (20 times per month)
— Buffer’s “Social Media Frequency Guide”
So, minimum 47 posts per week on these three networks. Recommended: 157.
Last year I decided to begin posting only on Tuesday Friday. (Since changed to Monday and Thursday.) I might post a couple times on each of those days. Even worse: I’m posting on a blog in the middle of nowhere, not on a platform that has the benefit of an existing network of users. (Unless you consider the Web itself an existing network of users.)
Convention dictates that I should now show a bunch of statistics demonstrating that posting biweekly had a great statistical benefit and led to ‘success’. However, I believe that would be a cold comfort.[1] I don’t keep traffic statistics - my favorite novels don’t have tracking devices inside, do they? And articles that statistically show ‘success’ are what have led us to ‘consistency’. I don’t think my social media friends are wrong about what is working in 2019.
Most weblogs are unfunded, spare-time ventures, yet most webloggers update their sites five days a week, and some even work on weekends!
— p. 127, Rebecca Blood, The Weblog Handbook (2002)
Does anyone really want ‘likes’? Or do they want ‘followers’? Or ‘visits’ or ‘impressions’? These are numerical decoys for something else.
When I think about writing online - I really just want to add something to someone’s life. To introduce them to a link, in the same way that Andy Baio introduced me to HIGH END CUSTOMIZABLE SAUNA EXPERIENCE. Or to write something they enjoy, just as Nadia Eghbal did with “The Tyranny of Ideas” - an essay I keep coming back to. Or maybe I meet them and can’t even sum it up with a single link, as with h0p3 (at philosopher.life) who I just like to converse with and keep up with throughout my week.
In this way, I feel successful. I might get a nice e-mail from someone. Or I might hear from someone I linked to, saying, “Hey, I had a few people find me through you.” Or I might just not know at all - most people just read and move on, which is totally understandable. And it might be several years later that they say thanks in some blog post that I stumble across.
I think that, even if you do play the ‘consistency’ game, you have to come to terms with not knowing. Why not start there then?
There are lots of strategies out there for gaming the system: posting at optimal times on a regular schedule, using hashtags and keywords, etc, but algorithms change and update as quickly as users adapt, and a battle where you can only react to your opponents moves isn’t one that can be won.
— Y. Kiri Yu, “The Only Way to Beat Algorithms is to Retrain Your Audience”
If I could statistically show you the good memories - the ones I will hold on to - from the past two years, I would show that graph here. I think that would be a useful statistic!
I can list some advantages to working on the Monday Thursday schedule:
There are some difficulties:
Aside from my own experiences, though, I can point to many other blogs that are following sleepy schedules: Nadia Eghbal, who posts every month or two with great effect. Subpixel.space, similar schedule, also high quality. Ribbonfarm seems to be twice-a-week, but has a strong base of readers. things magazine, once or twice per week. Phil Gyford posts maybe a bit more frequently than that. And Andy Baio, who blogs infrequently, but does so when he really has something that you don’t want to miss, is possibly the most important blog to me of all-time.
I don’t want to come off as too negative about frequent posting. There are many people that I enjoy following who post constantly, at all hours of the day. And it suits their personality. It’s cool that they have a lot to say.
For anyone else who may want to pull off a low-key blog (or TiddlyWiki[2]), I wrote this to encourage you! It has worked well for me - and I’m satisfied that all is not lost.
And I will gladly link to you if you make an attempt at this. Come on - let me link to you. I do a monthly hrefhunt, listing blogs and websites that I discover. It’s well worth it, to discover obscure or neglected blogs that haven’t fit into social media’s rapid pacing.
Perhaps we can get away from that in 2020.
I don’t think ‘likes’ and ‘followers’ are useful metrics — see, for instance, Instagram star with 3 million followers can’t sell 36 t-shirts. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

A most pathetic surveillance tool.
I have been dumping time into Fraidycat—the tool I use to monitor the Web (blogs, Twitter, YouTube, Soundcloud, what have you)—in an effort to really increase my ability to stay up on reading you all. I’m going to be releasing Fraidycat on Nov 4th—but you shouldn’t feel any obligation to use it, because it’s geared toward my own purposes, but I hope it might inspire someone out there to design even better ‘post-feed’[1] tools for reading the Web.
Just a heads up, though. It sucks. Here’s why:

The reason it sucks is because I am trying to make it an independent tool—it shouldn’t rely on a central website at all. (It also sucks because I suck, duh!)
The fortunate thing, though, about right now—is that everything else sucks, too! We traded all these glorious personal websites in for a handful of shitty networks that everyone hates. So using Fraidycat is actually a nice breath of somewhat non-shitty air, because you can follow people on all of those networks without needing to immerse yourself in their awfulness.
Here is what it looks like today:
So, yes, it does reward recency. But not as much as most platforms do. No one can just spam your feed. Yeah, they can bump themselves up to the top of the list, but that’s it. And, if I need to bump someone down manually, I can move them to the ‘daily’ or ‘weekly’ areas.
Imagine not needing to open all of these different networks. I tire of needing to open all of these separate apps: Marco Polo, Twitter, Instagram. My dream is that people can use the platforms they want and I don’t have to have accounts for them all—I can just follow from afar. Gah, one day.
And, actually, the worst part is that all of these sites are tough to crack into. For most blogs, I use RSS. No problem—works great. Wish I didn’t have to poll periodically—wish I could use Websockets (or Dat’s ‘live’ feature)—but not bad at all.
For Soundcloud and Twitter, I have to scrape the HTML. I’m even trying to get Facebook (m.facebook.com) scraping working for public pages. But this is going to be a tough road—keeping these scrapers functional. It sucks!
I wish there was more pressure on these sites to offer some kind of API or syndication. But it’s just abyssmal—it’s a kind of Dark Ages out there for this kind of thing. But I think that tools like this can help apply pressure on sites. I mean imagine if everyone started using ‘reader-like’ tools—this would further development down the RSS road.
I should say that I think we can do better than RSS. Or maybe just—we need more extensions. A few I’d like to see:
I will get back to my other projects (indieweb.xyz, my href hunts) once this is released. I really appreciate Jason McIntosh’s recent post about Bumpyskies, partly because I just like to read about personal projects—and it’s difficult to write about them because self-promotion has become quite shameful—however, I don’t know how we get out of the current era of corpypastas without personal software that makes an attempt at progress.
As in ‘news feed’ not ‘RSS feed’. Part of the idea here is to move past the cluttered news feed (which is itself just a permutation of the e-mail inbox) where you have to look through ALL the posts for EVERYONE one-by-one. As if they were all personal messages to you requiring your immediate attention. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

My teardown of Beaker and the Dat network.
We’re probably all scrambling to figure out a future for ourselves—either by hunting around for some shred of promising technology or by throwing up our hands—shouting and retreating and dreading the shadow of the next corporate titan descending from the sky. The prolonged lifespans of distributed protocols like Bitcoin and torrents means we’re maybe skeptical or jaded about any new protocols—these types of protocols are becoming old news. Maybe we’re just hunkered down in some current online bucket.
And I’ve felt this too—ActivityPub and Secure Scuttlebutt are too complicated. Tim Berner-Lee’s Solid is—well, I can’t even tell what it is. I don’t want to hear about blockchain: do we really need a GPU mining war at the center of our new Web? These are all someone’s idea of a distributed Web, but not mine. IPFS is really cool—but how do I surf it?
After discovering the Beaker Browser, a Web browser for the distributed Dat network, I felt that there was some real promise here. It was simple—load up the browser, create a website, pass your link around. There’s not much new to learn. And the underlying technology is solid: a binary protocol very similar to Git.[1] (As opposed to Secure Scuttlebutt, which is tons of encrypted JSON.)
I spent four months using Beaker actively: running this website on the network, messing with the different libraries, trying out the different apps—and then I hit a wall. Had a good time, for sure. And I kept seeding my Dats—kept my sites on the network. The technology was just lovely.
But: you can’t yet edit a website from a different browser (like on a different computer). This is called multi-writer support—and there is some talk about this landing by the end of the year. But this is, from what I can see, the single major omission in Beaker. (It’s not a problem with Dat itself—you can use a Hyperdb for that—but Beaker hasn’t settled the details.)
So I left Dat alone. I figured: they need time to work this problem out. Beaker has remained remarkably effortless to use—I’d hate for multi-writer to be tacked on, complicating the whole thing.
Recently, it occured to me that maybe I don’t need multi-writer. And maybe I should really be sure that the rest of Dat is as perfect as I think it is. So I started working on a limited (but full-featured) app for Beaker, with the intention of writing up a full ‘review’/‘teardown’ of everything I discover in the process.
This is my review—and the app is Duxtape.
It occured to me that a Muxtape clone would be a perfect tracer bullet for me to push Beaker. (Muxtape was a 2008 website for sharing mixtapes—minimal design, suddenly became very prominent, and then was promptly DEMOLISHED by the music industry.)
Muxtape was shut down because it was centralized. If Muxtape had been distributed[2], it would be much more difficult (perhaps impossible) to shutter.
Muxtape did some file processing. Reading music file metadata (title, artist’s name) and loading music into the browser’s music player. Could the app handle this?
The Muxtape home page listed recent mixtapes. This would give me a chance to use datPeers—a way of talking to others that are using the same site.
Storing song information and order. I don’t have a database, so where do I put this stuff?
A more general question: What if I upgrade the code? How do I handle upgrading the mixtapes too?
I also didn’t want to think in terms of social networks. Many of Beaker’s most advanced apps (like Fritter and Rotonde) are ‘messaging’/‘social’ apps. I specifically wanted a creation tool that spit out something that was easy to share.
How would Beaker do with that kind of tool?
Ok, so how does Dat work exactly? It is simply a unique address attached to a folder of files (kind of like a ZIP file.) You then share that folder on the network and others can sync it to their system when they visit the unique address.
In the case of Duxtape, the address is dat://df1cc…40.

The full folder contents can be viewed here at datBase.
So when you visit Duxtape, all that stuff is downloaded. Beaker will show you the index.html, which simply lets you create a new mixtape and lists any that you’ve encountered.
Now, you can’t edit my Dat—so how do you create a mixtape?? And how does it keep track of other mixtapes?? Teardown time!
This creates a new Dat (new folder on your computer) with just index.html inside. I actually copy the tape.html from my Dat into that folder, your mixtape. That HTML file will load its images and Javascript and such from MY Duxtape dat! (This means I can upgrade my original Dat—and upgrade YOUR Dat automatically—cool, but… dangerous.)
When you hit someone else’s mixtape link, the Javascript loads the Duxtape home page in an HTML iframe—passing the link to that page. The link is then stored in ‘localStorage’ for that page. So, those are kept in a kind of a cookie. Nothing very server-like about any of that.
But furthermore: when you are on the Duxtape homepage, your browser will connect to other browsers (using datPeers) that are viewing the homepage. And you will trade mixtapes there. Think about this: you can only discover those who happen to be around when you are! It truly acts like a street corner for a random encounter.
Where are song titles and song ordering kept? Well, heh—this is just kept in the HTML—in your index.html. Many Beaker apps keep stuff like this in a JSON file. But I felt that there was no need for duplication. (I think the IndieWeb has fully corrupted me.) When I want to read the mixtape title, I load the index.html and find the proper tags in the page. (Like: span.tape-title, for instance.)
Beaker has a special technique you can use for batching up edits before you publish them. (See the checkout method.) Basically, you can create a temporary Dat, make your changes to it, then either delete it or publish it.
However, I didn’t go this route. It turned out that I could batch up all my changes in the browser before saving them. This includes uploaded files! I can play files in the browser and read their data without copying them to the Dat. So no need to do this. It’s a neat feature—for a different app.
So this allows you to work on your mixtape, add and delete songs, get it perfect—then upload things to the network.[3]
This all worked very well—though I doubt it would work as well if you had 1,000 songs on your mixtape. In that case, I’d probably recommend using a database to store stuff rather than HTML. But it still might work well for 1,000 songs—and maybe even 1,000,000. This is another advantage to not having a server as a bottleneck. There is only so much that a single person can do to overload their browser.
For reading song metadata, I used the music-metadata-browser library—yes, I actually parse the MP3 and OGG files right in the browser! This can only happen in modern times: Javascript has become a competent technology on the server, now all of that good stuff can move into the browser and the whole app doesn’t need a server—in fact, WebAssembly makes Dat even more compelling.
Lastly, here are some calls that I used which are specific to the Beaker Browser—these are the only differences between running Duxtape in plain Chrome and running it distributed:
stat: I use this to check if a song file has already been uploaded.
readFile: To read the index.html when I need to get song information.
writeFile: To save changes to songs—to publish the index.html for your mixtape.
unlink: To delete songs—NOTE: that songs are still in the Dat’s history and may be downloaded.
getInfo and configure: Just to update the name of the mixtape’s Dat if the name of the mixtape is changed by you. A small touch.
isOwner: The getInfo() above also tells me if you are the owner of this mixtape. This is crucial! I wanted to highlight this—I use this to enable mixtape editing automatically. If you don’t own the mixtape, you don’t see this. (All editor controls are removed when the index.html is saved back to disk.)
So this should give you a good idea of what Dat adds. And I just want to say: I have been wondering for awhile why Dat has its own special format rather than just using something like Git. But now I see: that would be too complex. I am so glad that I don’t have to pull() and commit() and all that.
I spent most of my time working on the design and on subtle niceties—and that’s how it should be.
It’s clear that there are tremendous advantages here: Dat is apps without death. Because there is no server, it is simple to both seed an app (keep it going) and to copy it (re-centralize it). I have one central Duxtape right now (duxtape.kickscondor.com), but you could easily fork that one (using Beaker’s ‘make editable copy’ button) and improve it, take it further.
The roots of ‘view source’ live on, in an incredibly realized form. (In Beaker, you can right-click on Duxtape and ‘view source’ for the entire app. You can do this for your mixtapes, too. Question: When was the last time you inspected the code hosting your Webmail, your blog, your photo storage? Related question: When was the first time?)
In fact, it now becomes HARD:IMPOSSIBLE to take down an app. There is no app store to shut things down. There is no central app to target. In minutes, it can be renamed, rehashed, reminified even (if needed)—reborn on the network.
This has a fascinating conflict with the need to version and centralize an app. Many might desire to stay with the authoritative app—to preserve their data, to stay in touch with the seeders of that central app. But this is a good tension, too—it INSISTS on backwards compatibility. I am pressured to keep Duxtape’s conventions, to preserve everyone’s mixtapes. It will be difficult to upgrade everything that is possibly out there.
This same pressure is reminiscent of the Web’s own history: HTML that ran in 1995 often still runs today—Flash and Quicktime are quite the opposite, as will be all of the native apps of today. (Think of apps you’ve bought that are already outmoded.) The ‘view source’ keeps compatibility in check. If Beaker is able to keep their APIs firm, then there is real strength here.
Still, Dat is limited. Where is it short? Can we accept these?
But—think about this: I don’t have to take on cloud hosting! I don’t need to scale the app! This is a huge relief. URGENT QUESTION: Why are we trying to even do this?
I also mentioned not needing the multi-writer feature. Obviously, multi-writer demands some centralization. A central Dat needs to authorize other Dats. But I think this centralization could be moved to the DNS resolution—basically, if I edit Duxtape on a second machine, it will have a new unique address—and I can point duxtape.kickscondor.com to that new address. This means I can never get locked out of the Dat—unless I am locked out of the DNS. (So there is a way forward without any new features.)
Still, these downsides are pure side effects of a distributed Web. These are the realities we’re asking for—for me, it’s time to start accepting them.
Several months had passed since I last used Dat—how was it doing with adoption?
Well, it seems, no different. But it’s hard to say for a distributed network. Every Dat runs in secret—they are difficult to find. The discovery problems are perhaps the most urgent ones.
But there is good recent work:
These are all cool—but Dat has a long way to go. With the corpypastas taking up all the attention, adoption is terribly slow. What Beaker may need most of all is a mobile version. But, hey, I’ll write my article here and make my dent—if you feel stimulated to noise about, then please join in. I mean: using a new web browser is just very low effort—perhaps the lowest. You need to use one anyway!
I think HTTPS has proven itself well for the centralized stuff. Perhaps there is a future for HTTPS as simply a collection of centralized REST APIs for things like search and peer discovery. I think the remaining apps could migrate to this fertile garden emerging on the Dat network.
It should be noted that there is a document called “How Dat Works”, which goes into all the details and which is absolutely beautiful, well-organized and, yeah, it actually teaches you very plainly how Dat works! I am not sure I’ve seen such a well-made ‘white paper’/‘spec’-type doc. ↩︎
Apps on the Dat network have no ‘server’, they can be seeded like any other file. ↩︎
Clearly Dat apps will need to put extra work into providing a scratch area for draft work—the protocol puts this pressure on the app. I think this also makes the system lean toward single-page apps, to assist drafting when in a large app. ↩︎
I would be REALLY interested in seeing an equivalent to The Pirate Bay on Beaker. If you could move a tracker to the Dat network, much would be learned about how to decentralize search. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Will your .pizza domain survive?
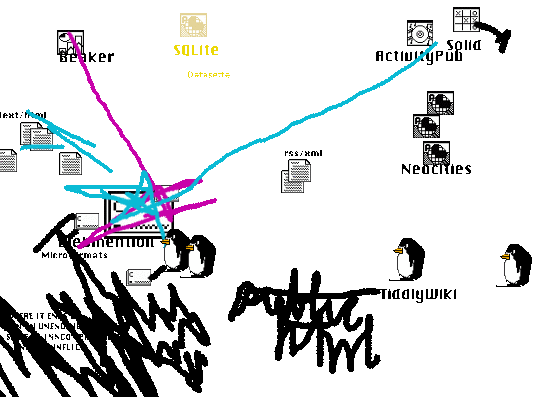
Beaker vs TiddlyWiki. ActivityPub against Webmentions. Plain HTML hates them all.
I step back and, man, all the burgeoning technology out there is at complete odds with the other! Let’s do a run down. I’m not just doing this to stir up your sensibilities. Part of it is that I am lost in all of this stuff and need to sort my socks.
(I realize I’m doing a lot of ‘versus’ stuff below—but I don’t mean to be critical or adversarial. The point is to examine the frictions.)
At face value, Beaker[1] is great for TiddlyWiki[2]: you can have this browser that can save to your computer directly—so you can read and write your wiki all day, kid! And it syncs, it syncs.
No, it doesn’t let you write from different places yet—so you can’t really use it—but hopefully I’ll have to come back and change these words soon enough—it’s almost there?

Big problem, though: Beaker (Dat[3]) doesn’t store differences. And TiddlyWiki is one big file. So every time you save, it keeps the old one saved and the network starts to fill with these old copies. And you can easily have a 10 meg wiki—you get a hundred days of edits under your belt and you’ve created some trouble for yourself.
Beaker is great for your basic blog or smattering of pages. It remains to be seen how this would be solved: differencing? Breaking up TiddlyWiki? Storing in JSON? Or do I just regenerate a new hash, a new Dat every time I publish? And use the hostname rather than the hash. I don’t know if that messes with the whole thing too much.
Where I Lean: I think I side with Beaker here. TiddlyWiki is made for browsers that haven’t focused on writing. But if it could be tailored to Beaker—to save in individual files—a Dat website already acts like a giant file, like a ZIP file. And I think it makes more sense to keep these files together inside a Dat rather than using HTML as the filesystem.
While we’re here, I’ve been dabbling with Datasette[4] as a possible inductee into the tultywits and I could see more sites being done this way. A mutation of Datasette that appeals to me is: a static HTML site that stores all its data in a single file database—the incomparable SQLite.
I could see this blog done out like that: I access the database from Beaker and add posts. Then it gets synced to you and the site just loads everything straight from your synced database, stored in that single file.
But yeah: single file, gets bigger and bigger. (Interesting that TorrentNet is a network built on BitTorrent and SQLite.) I know Dat (Hypercore) deals in chunks. Are chunks updated individually or is the whole file replaced? I just can’t find it.
Where I Lean: I don’t know yet! Need to find a good database to use inside a ‘dat’ and which functions well with Beaker (today).
Ok, talk about hot friction—Beaker sites require no server, so the dream is to package your raw posts with your site and use JavaScript to display it all. This prevents you from having HTML copies of things everywhere—you update a post and your index.html gets updated, tag pages get updated, monthly archives, etc.
And TiddlyWiki is all JavaScript. Internal dynamism vs Indieweb’s external dynamism.

But the Indieweb craves static HTML—full of microformats. There’s just no other way about it.
Where I Lean: This is tough! If I want to participate in the Indieweb, I need static HTML. So I think I will output minimal HTML for all the posts and the home page. The rest can be JavaScript. So—not too bad?
ActivityPub seems to want everything to be dynamic. I saw this comment by one of the main Mastodon developers:
I do not plan on supporting Atom feeds that don’t have Webfinger and Salmon (i.e. non-interactive, non-user feeds.)
This seems like a devotion to ‘social’, right?
I’ve been wrestling with trying to get this blog hooked up to Mastodon—just out of curiosity. But I gave up. What’s the point? Anyone can use a web browser to get here. Well, yeah, I would like to communicate with everyone using their chosen home base.
ActivityPub and Beaker are almost diametrically opposed it seems.
Where I Lean: Retreat from ActivityPub. I am hard-staked to Static: the Gathering. (‘Bridgy Fed’[5] is a possible answer—but subscribing to @[email protected] doesn’t seem to work quite yet.)

It feels like ActivityPub is pushing itself further away with such an immense protocol. Maybe it’s like Andre Staltz recently told me about Secure Scuttlebutt:
[…] ideally we want SSB to be a decentralized invite-only networks, so that someone has to pull you into their social circles, or you pull in others into yours. It has upsides and downsides, but we think it more naturally corresponds to relationships outside tech.
Ok, so, perhaps building so-called ‘walled gardens’—Andre says, “isolated islands of SSB networks”—is just the modern order. (Secure Scuttlebutt is furthered obscured by simply not being accessible through any web browser I know of; there are mobile apps.)
This feels more like a head-to-head, except that ‘Bridgy Fed’[5:1] is working to connect the two. These two both are:
I think the funny thing here goes back to ‘Fed Bridgy’: the Indieweb/Webmention crowd is really making an effort to bridge the protocols. This is very amusing to me because the Webmention can be entirely described in a few paragraphs—so why are we using anything else at this point?
But the Webmention crowd now seems to have enough time on its hands that it’s now connecting Twitter, Github, anonymous comments, Mastodon, micro.blog to its lingua franca. So what I don’t understand is—why not just speak French? ActivityPub falls back to OStatus. What gives?
Beaker Browser. A decentralized Web browser. You share your website on the network and everyone can seed it. ↩︎
TiddlyWiki. A wiki that is a single HTML page. It can be edited in Firefox and Google, then saved back to a single file. ↩︎
Beaker uses the Dat protocol rather than the Web (HTTP). A ‘dat’ is simply a zip file of your website than can be shared and that keeps its file history around. ↩︎
Datasette. If you have a database of data you want to share, Datasette will automatically generate a website for it. ↩︎
fed.brid.gy. A site for replying to Mastodon from your Indieweb site. ↩︎ ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A prototype for the time being.
I’m sorry to be very ‘projecty’ today—I will get back to linking and surfing straightway. But, first, I need to share a prototype that I’ve been working on.
Our friend h0p3[1] has now filled his personal, public TiddlyWiki to the brim—a whopping 21 MEGAbyte file full of, oh, words. Phrases. Dark-triadic memetic, for instance. And I’m not eager for him to abandon this wiki to another system—and I’m not sure he can.
So, I’ve fashioned a doorway.
This is not a permanent mirror yet. Please don’t link to it.

Yes, there is also an archive page. I took these from his Github repo, which appears to go all the way back to the beginning.
Ok, yes, so it does have one other feature: it works with the browser cache. This means that if you load snapshot #623 and then load #624, it will not reload the entire wiki all over again—just the changes. This is because they are both based on the same snapshot (which is #618, to be precise.) So—if you are reading over the course of a month, you should only load the snapshot once.
Snapshots are taken once the changes go beyond 2 MB—though this can be tuned, of course.
Shrunk to 11% of its original size. This is done through the use of judicious diffs (or deltas). The code is in my TiddlyWiki-loader repository.
I picked up this project last week and kind of got sucked into it. I tried a number of approaches—both in snapshotting the thing and in loading the HTML.
I ended up with an IFRAME in the end. It was just so much faster to push a 21 MB string through IFRAME’s srcdoc property than to use stuff like innerHTML or parseHTML or all the other strategies.
Also: document.write (and document.open and document.close) seems immensely slow and unreliable. Perhaps I was doing it wrong? (You can look through the commit log on Github to find my old work.)
I originally thought I’d settled on splitting the wiki up into ~200 pieces that would be updated with changes each time the wiki gets synchronized. I got a fair bit into the algorithm here (and, again, this can be seen in the commit log—the kicksplit.py script.)
But two-hundred chunks of 21 MB is still 10k per chunk. And usually a single day of edits would result in twenty chunks being updated. This meant a single snapshot would be two megs. In a few days, we’re up to eight megs.
Once I went back to diffs and saw that a single day usually only comprised 20-50k of changes (and that this stayed consistent over the entire life of h0p3’s wiki,) I was convinced. The use of diffs also made it very simple to add an archives page.
In addition, this will help with TiddlyWikis that are shared on the Dat network[2]. Right now, if you have a Dat with a TiddlyWiki in it, it will grow in size just like the 6 gig folder I talked about in the last box. If you use this script, you can be down to a reasonable size. (I also believe I can get this to work directly from TiddlyWiki from inside of Beaker.)
And, so, yeah, here is a dat link you can enjoy: dat://38c211…a3/
I think that’s all that I’ll discuss here, for further technical details (and how to actually use it), see the README. I just want to offer help to my friends out there that are doing this kind of work and encourage anyone else who might be worried that hosting a public TiddlyWiki might drain too much bandwidth.
philosopher.life, dontchakno? I’m not going to type it in for ya. ↩︎
The network used by the Beaker Browser, which is one of my tultywits. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
My personal strategy for handling HTML on the distributed Web.
So, HTML is a bit different on the distributed Web (the Dat network which the Beaker Browser uses, IPFS and so on) because your file history sticks around there. Normally on the Web, you upload your new website and it replaces the old one. With all of these other ‘webs’, it’s not that way—you add your new changes on top of the old site.
Things tend to pile up. You’re filing these networks with files. So, with a blog, for instance, there are these concerns:
Ultimately, I might end up delivering a pure JavaScript site on the Dat network. It seems very efficient to do that actually—this site weighs in at 19 MB normally, but a pure JavaScript version should be around 7 MB (with 5 MB of that being images.)
My interim solution is to mimick HTML includes. My tags look like this:
<link rel="include" href="/includes/header.html">
The code to load these is this:
document.addEventListener('DOMContentLoaded', function() {
let eles = document.querySelectorAll("link[rel='include']");
for (let i = 0; i < eles.length; i++) {
let ele = eles[i];
let xhr = new XMLHttpRequest()
xhr.onload = function() {
let frag = document.createRange().
createContextualFragment(this.responseText)
let seq = function () {
while (frag.children.length > 0) {
let c = frag.children[0]
if (c.tagName == "SCRIPT" && c.src) {
c.onload = seq
c.onerror = seq
}
ele.parentNode.insertBefore(c, ele);
if (c.onload == seq) {
break
}
}
}
seq()
}
xhr.open('GET', ele.href);
xhr.send();
}
})
You can put this anywhere on the page you want—in the <head> tags, in a
script that gets loaded. It will also load any scripts inside the HTML fragment
that gets loaded.
This change saved me 4 MB immediately. But, in the long run, the savings are much greater because my whole site doesn’t rebuild when I add a single tag (which shows up in the ‘archives’ box on the left-hand side of this site.)
I would have used ‘HTML imports’—but they aren’t supported by Firefox and are a bit weird for this (because they don’t actally put the HTML inside into the page.)
I am happy to anyone for improvements that can be made to this.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Thinking harder about the surprising return of static HTML.
Static website and blog generators continue to be a very solid and surprising undercurrent out there. What could be more kitschy on the Web than hand-rolled HTML? It must be the hipsters; must be the fusty graybeards. Oh, it is—but we’re also talking about the most ubiquitous file format in the world here.
Popular staticgens sit atop the millions of repositories on Github: Jekyll (#71 with 35.5k stars—above Bitcoin), Next.js (#98 with 29.3k stars, just above Rust), Hugo (#118 with 28.9k stars). This part of the software world has its own focused directories[1] and there is constant innovation—such as this week’s Vapid[2] beta and the recent Cabal[3].
And I keep seeing comments like this:
I recently completed a pretty fun little website for the U.S. freight rail industry using Hugo […] It will soon replace an aging version of the site that was built with Sitecore CMS, .NET, and SQL Server.[4]
Yes, it’s gotten to the point that some out there are creating read-only web APIs (kind of like websites used by machines to communicate between each other)—yes, you heard that right![5]
Clearly there are some obvious practical benefits to static websites, which are listed time and again:

Fast.
Web servers can put up static HTML with lightning speed. Thus you can endure
a sudden viral rash of readers, no problem.
Cheap.
While static HTML might require more disk space than an equivalent dynamic
site—although this is arguable, since there is less software to install
along with it—it requires fewer CPU and memory resources. You can put your
site up on Amazon S3 for pennies. Or even Neocities or Github Pages for free.
Security.
With no server-side code running, this closes the attack vector for things
like SQL injection attacks.
Of course, everything is a tradeoff—and I’m sure you are conjuring up an argument that one simply couldn’t write an Uber competitor in static HTML. But even THAT has become possible! The recent release of the Beaker Browser has seen the appearance of a Twitter clone (called Fritter[6]), which is written ENTIRELY IN DUN-DUN STATIC JS AND H.T.M.L!!
Many think the Beaker Browser is all about the ‘decentralized Web’. Yeah, uh, in part. Sure, there are many that want this ‘d-web’—I imagine there is some crossover with the groups that want grassroots, localized mesh networks—for political reasons, speech reasons, maybe Mozilla wants a new buzzword, maybe out of idealism or (justified!) paranoia. And maybe it’s for real.
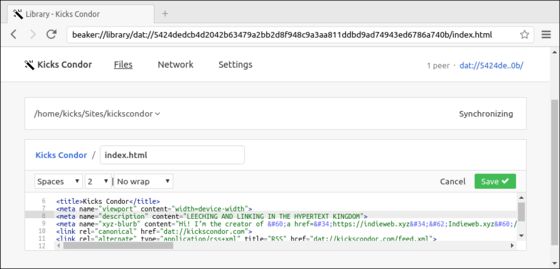
No, my friends, Beaker marks a return of the possibility of a read-write Web. (I believe this idea took a step back in 2004 when Netscape took Composer out of its browser—which at that time was a ‘suite’ you could use to write HTML as well as read it.) Pictured above, I am editing the source code of my site right from the browser—but this is miniscule compared to what Beaker can do[7]. (Including Beaker’s dead-simple “Make an editable copy”—a button that appears in the address bar of any ‘dat’ website you visit.)
(And, yes, Twitter has given you read-write 140 chars. Facebook gave a read-write width of 476 pixels across—along with a vague restriction to height. And Reddit gave you a read-write social pastebin in gray-on-white-with-a-little-blue[8]. Beaker looks to me like read-write full stop.)
Now look—I couldn’t care less how you choose to write your mobile amateur Karaoke platform[9], what languages or what spicy styles. But for personal people of the Web—the bloggers, the hobbyists, the newbs still out there, the NETIZENS BAAAHAHAHAHHAAA!—yeah, no srsly, let’s be srs, I think there are even more compelling reason for you.
Broken software is a massive problem. Wordpress can go down—an upgrade can botch it, a plugin can get hacked, a plugin can run slow, it can get overloaded. Will your Ghost installation still run in ten years? Twenty years?
Dynamic sites seem to need a ‘stack’ of software and stacks do fall over. And restacking—reinstalling software on a new server can be time-consuming. One day that software simply won’t work. And, while ‘staticgens’ can break as well, it’s not quite a ‘stack’.
And, really, it may not matter at that point: the ‘staticgens’ do leave you with the static HTML.
The more interesting question is: how long will the web platform live on for? How long will HTML and JavaScript stay on? They have shown remarkable resilience and backward compatibility. I spend a lot of time surfing the Old Web and it’s most often Flash that is broken—while even some of the oldest, most convuluted stuff is exactly as it was intended.
Static HTML is truly portable and can be perfectly preserved in the vault. Often we now think of it simply as a transitory snapshot between screen states. Stop to think of its value as a rich document format—perhaps you might begin to think of its broken links as a glaring weakness—but those are only the absolute ones, the many more relative links continue to function no matter where it goes!
And, if there were more static HTML sites out there, isn’t it possible that we would find less of the broken absolutes?
Furthermore, since static HTML is so perfectly amenable to the decentralized Web—isn’t it possible that those absolute links could become UNBREAKABLE out there??
A friend recently discovered a Russian tortoise—it was initially taken to the Wildlife Service out of suspicion that it was an endangered Desert tortoise. But I think its four toes were the giveaway. (This turtle is surprisingly speedy and energetic might I add. I often couldn’t see it directly, but I observed the rustling of the ivy as it crawled a hundred yards over the space of—what seemed like—minutes.)
This friend remarked that the tortoise may outlive him. A common lifespan for the Russian is fifty years—but could go to even 100! (Yes, this is unlikely, but hyperbole is great fun in casual mode.)
This brought on a quote I recently read from Gabriel Blackwell:
In a story called “Web Mind #3,” computer scientist Rudy Rucker writes, “To some extent, an author’s collected works comprise an attempt to model his or her mind.” Those writings are like a “personal encyclopedia,” he says; they need structure as much as they need preservation. He thus invented the “lifebox,” a device that “uses hypertext links to hook together everything you tell it.” No writing required. “The lifebox is almost like a simulation of you,” Rucker says, in that “your eventual audience can interact with your stories, interrupting and asking questions.”
— p113, Madeleine E
An aside to regular readers: Hell—this sounds like philosopher.life! And this has very much been a theme in our conversations, with this line bubbling up from the recent Hyperconversations letter:
I do not consider myself my wiki, but I think it represents me strongly. Further, I think my wiki and I are highly integrated. I think it’s an evolving external representation of the internal (think Kantian epistemology) representations of myself to which I attend. It’s a model of a model, and it’s guaranteed to be flawed, imho (perhaps I cannot answer the question for you because I consider it equivalent to resolving the fundamental question of philosophy).
God, I’ve done a bang-up job here. I don’t think I can find a better argument for static HTML than: it might actually be serializing YOU! 😘
I am tempted to end there, except that I didn’t come here to write some passionate screed that ultimately comes off as HTML dogmatism. I don’t care to say that static HTML is the ultimate solution, that it’s where things are heading and that it is the very brick of Xanadu.
I think where I stand is this: I want my personal thoughts and writings to land in static HTML. And, if I’m using some variant (such as Markdown or TiddlyWiki), I still need to always keep a copy in said format. And I hope that tools will improve in working with static HTML.
And I think I also tilt more toward ‘static’ when a new thing comes along. Take ActivityPub: I am not likely to advocate it until it is useful to static HTML. If it seems to take personal users away from ‘static’ into some other infostorage—what for? I like that Webmention.io has brought dynamism to static—I use the service for receiving comments on static essays like these.
To me, it recalls the robustness principle:
Be conservative in what you do, be liberal in what you accept from others.
In turn, recalling the software talk Functional Core, Imperative Shell—its idea that the inner workings of a construct must be sound and impervious; the exterior can be interchangable armor, disposable and adapted over time. (To bring Magic: the Gathering fully into this—this is our ‘prison deck’.)
Static within; dynamic without. Yin and yang. (But I call Yin!)
Certainly there is an ‘awesome’. But also custom directories, such as staticgen.com and ssg. Beyond that, there are loads of ‘10 best staticgens’ articles on the webdev blogs. ↩︎
A tool that builds a dashboard from static HTML pages. (Think of it: HTML is the database schema??) Anyway: vapid.com. ↩︎
A chat platform built on static files. I do consider this to be in the neighborhood—it can die and still exist as a static archive. See the repo. ↩︎
Build a JSON API with Hugo’s Custom Output Formats, April 2018. ↩︎
If you’re in Beaker: dat://fritter.hashbase.io. ↩︎
The DatArchive API, which any website can leverage if it runs inside of Beaker, allows you to edit any website that you own FROM that same website. A very rudimentary example would be dead-lite. ↩︎
The “gray on white with a little blue” phenomenon is covered in further detail at Things We Left in the Old Web. ↩︎
My apologies—I am pretty glued to this right now. Finally there is a whole radio station devoted to the musical stylings of off-key ten-year-olds and very earnest, nasally Sinatras. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A proof-of-concept for enjoying HTML includes.
It seems like the Beaker Browser has been making an attempt to provide tools so that you can create JavaScript apps that function literally without a server. Their Twitter-equivalent (‘fritter’) runs entirely in the browser—it simply aggregates a bunch of static dats that are out there. And when you post, Beaker is able to write to your personal dat. Which is then aggregated by all the others out there.
One of the key features of Beaker that allows this is the ‘fallback_page’ setting. This setting basically allows for simplified URL rewriting—by redirecting all 404s to an HTML page in your dat. In a way, this resembles mod_rewrite-type functionality in the browser!
What I’ve been wondering is: would it be possible to bring server-side includes to Beaker? So, yeah: browser-side includes. My patch to beaker-core is here. It’s very simple—but it works!
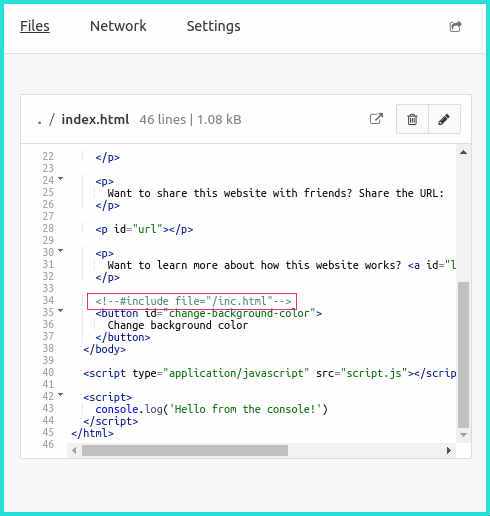
Here is Beaker editing the index.html of a new basic Website from its template. I’m including the line:
<!--#include file="inc.html"-->
This will instruct beaker to inline the inc.html contents from the same dat archive.
Its contents look like this:
<p style="color:red">TEST</p>
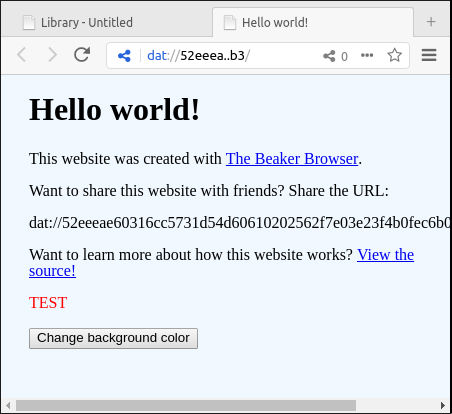
And here we see the HTML displayed in the browser.
I’m not sure. As I’ve been working with static HTML in dat, I’ve thought that it would be ‘nice’. But is ‘nice’ good enough?
Here are a few positives that I see:
Appeal to novices. Giving more power to HTML writers can lower the bar to building interesting things with Dat. Beaker has already shown that they are willing to flesh out JavaScript libraries to give hooks to all of us users out here. But there are many people who know HTML and not JavaScript. I think features for building the documents could be really useful.
Space savings. I think static blogs would appreciate the tools to break up HTML so that there could be fewer archive changes when layouts change subtly.
Showcase what Beaker is. Moving server-side includes into Beaker could demonstrate the lack of a need for an HTTP server in a concrete way. And perhaps there are other Apache/Nginx settings that could be safely brought to Beaker.
The negative is that Dat might need its own wget that understands a feature
like this. At any rate, I would be interested if others find any merit to
something like this. I realize the syntax is pretty old school—but it’s
already very standard and familiar, which seems beneficial.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

It’s good to be a little ‘river’ of thoughts—apart from the estuaries.
Inspired by the concept of Ripped Sheets of Paper, I began to see a new blog design in my mind that departed from all the current trends. (Related: Things We Left in the Old Web.)
The large majority of blogs and social media feeds out there are:
So, yeah, no wonder the Web has deteriorated! We just don’t care. It’s understandable—we experimented for a good ten or twenty years. I guess that’s why I wanted this site to border on bizarre—to try to reach for the other extreme without simply aspiring to brutalism.
To show that leaving social media can free you to build your own special place on the web. I have no reason to scream and war here in order to stand apart.
When I started laying out the main ‘river’ of strips on my various feed pages—here’s my August archive, for instance—I started to want the different posts to have a greater impact on the page based on what they were.

A tweet-style note thing should be tiny. It’s a mere thought.
A reply to someone might be longer, depending on the quality of the ideas within it.
And the long essays take a great length of time to craft—they should have the marquee.
It began to remind me of the aging ‘tag cloud’. Except that I couldn’t stand tag clouds because the small text in the cloud was always too small! And they also became stale—they always use the same layout. (It would be interesting to rethink the tag cloud—maybe with this ‘river’ in mind!)
Even though these ‘river’-style feeds are slender and light on metadata—for instance, the ‘river’ is very light on date and tagging info—it’s all there. All the metadata and post content is in the HTML. This is so that I can pop up the full post immediately. But also: that stuff is the microformats!
Why bother with microformats? I remember this technology coming out like a decade ago and—it went nowhere!
But, no, they are actually coming into stride. They allow me to syndicate and reply on micro.blog without leaving my site. I can reply to all my webfriends in like fashion. They have added a lot to blogging in these times—look up ‘Indieweb’.
Honestly, they make this blog worth using. For me. I feel like the design should be for you; the semantic structure is for me.
This lead to a happy coalescing of the design and the structure: I could load individual posts on a windowing layer over the home page. This is a kickback to the old DHTML windowing sites of yesteryear. (And, in part, inspired by the zine at whimsy.space.)
What’s more—nothing (except the archives dropdown, I should say) is broken if Javascript is off. You can still center-click on the square blog post cards to launch them in a tab. URLs in the browser should line up properly without filling your history with crap.
I do have some new kinds of post layouts that will be cropping up here are there—such as how this article is made of individual tiles. But it all flattens to simple HTML where I need it to.
One of the struggles of the modern Indieweb is to have uniqueness and flair without sacrificing function. I have to do a lot of customization to integrate with Twitter, micro.blog and RSS. But I hope you will not need to work around me. So that remains to be seen.
At any rate: thankyou! So many of you that I correspond with offered juicy
conversations that stimulated this new design. My muse has always been Life
Itself. The experiences and conversations all around --> inspiration!
I feel fortunate to any eyes that wipe across my sentences from time to time.
Time to get back to linking to you.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A rundown of improvements—and the general mood—one month since opening Indieweb.xyz.
Ok, Indieweb.xyz has been open for a month! The point of the site is to give you a place to syndicate your essays and conversations where they’ll actually be seen.
In a way, it’s a silo—a central info container. Silos make it easy. You go there and dump stuff in. But, here in the Indieweb, we want No Central. We want Decentral. Which is more difficult because all these little sites and blogs out there have to work together—that’s tough!
Ok so, going to back to how this works: Brad Enslen and I have been posting our thoughts about how to innovate blog directories, search and webrings to the /en/linking sub on Indieweb.xyz. If you want to join the conversation, just send your posts there by including a link like this in your post:
<p><em>This was also posted to <a href="https://indieweb.xyz/en/linking"
class="u-syndication">/en/linking</a>.</em></p>
If your blog supports Webmentions, then Indieweb.xyz should be notified of the post when you publish it. But even if your blog doesn’t support Webmentions, you can just submit your link by hand.
One of my big projects lately has been to make it very easy for you all out there to participate. You no longer need a ton of what they call ‘microformats’ everywhere on your blog.
You literally just need to:
class="u-syndication" part, but I would still recommend it. If you
have multiple links to Indieweb.xyz in your post, the one marked u-syndication
will be preferred.)It helps if you have the microformats—this makes it easy to figure out who the
author of the post is and so on. But Indieweb.xyz will now fallback to
using HTML title tags (and RSS feed even) to figure out who is posting
and what they are posting.
A feature I’m incredibly excited about is the blog directory,
which lists all the blogs that post to Indieweb.xyz—and which also gives you a few hundred
characters to describe your blog! (It uses the description meta tag from
your blog’s home page.)
I think of Indieweb.xyz as an experiment in building a decentralized forum in which everyone contributes their bits. And Indieweb.xyz merges them together. It’s decentralized because you can easily switch all your Indieweb.xyz links to another site, send your Webmentions—and now THAT site will merge you into their community.
In a way, I’m starting to see it as a wiki where each person’s changes happen on their own blog. This blog directory is like a wiki page where everyone gets their little section to control. I’m going to expand this idea bit-by-bit over the next few months.
Just to clarify: the directory is updated whenever you send a Webmention, so if you change your blog description, resend one of your Webmentions to update it.
We are a long way off from solving abuse on our websites. We desperately want technology to solve this. But it is a human problem. I am starting to believe that the more we solve a problem with technology, the more human problems we create. (This has been generally true of pollution, human rights, ecology, quality of life, almost every human problem. There are, of course, fortuitous exceptions to this.)
Decentralization is somewhat fortuitous. Smaller, isolated communities are less of a target. The World Trade Tower is a large, appealing target. But Sandy Hook still happens. A smaller community can survive longer, but it will still degenerate—small communities often become hostile to outsiders (a.k.a newcomers).
So while a given Mastodon instance’s code of conduct provides a human solution—sudden, effortless removal of a terrorist—there will be false positives. I have been kicked out, hellbanned, ignored in communities many times—this isn’t an appeal for self-pity, just a note that moderation powers are often misdirected. I moved on to other communities—but I earnestly wanted to participate in some of those communities that I couldn’t seem to penetrate.
So, yeah: rules will be coming together. It’s all we have. I’m impressed that the Hacker News community has held together for so long, but maybe it’s too much of a monoculture. HN’s guidelines seem to work.
Last thing. A recent addition is a comment count on each submission. These comment counts are scraped from the blog post. It seems very “indieweb” to let the comments stay on the blog. The problem is that the microformats for comments are not widely supported and, well, they suck. It’s all just too complicated. You slightly change an HTML template and everything breaks.
Not to mention that I have no idea if the number is actually correct. Are these legit comments? Or is the number being spoofed?
I will also add that—if you submit a link to someone else’s blog, even if it’s an “indieweb” blog—the comment count will come from your blog. This is because the original entry might have been submitted by the author to a different sub. So your link contains the comments about that blog post for that sub.
Really tight microformat templates will need to become widespread for this to become really useful. In the meantime, it’s a curious little feature that I’m happy to spend a few characters on.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Continuing my discussion from Foundations of a Tiny Directory, I discuss the recent trend in ‘awesome’ directories.
All this recent discussion about link directories and one of the biggest innovations was sitting under my nose! The awesome-style directory, which I was reminded of by the Dat Project’s Awesome list.
An “awesome” list is—well, it isn’t described very well on the about page, which simply says: only awesome is awesome. I think the description here is a bit better:
Curated lists of awesome links around a specific topic.
The “awesome” part to me: these independently-managed directories are then brought together into a single, larger directory. Both at the master repo and at stylized versions of the master repo, such as AwesomeSearch.
In a way, there’s nothing more to say. You create a list of links. Make sure they are all awesome. Organize them under subtopics. And, for extra credit, write a sentence about each one.

Generally, awesome lists are hosted on Github. They are plain Markdown READMEs.
They use h2 and h3 headers for topics; ul tags for the link lists. They are
unstyled, reminiscent of a wiki.
This plain presentation is possibly to its benefit—you don’t stare at the directory, you move through it. It’s a conduit, designed to take you to the awesome things.
Awesome lists do not use tags; they are hierarchical. But they never nest too deeply. (Take the Testing Frameworks section under the JavaScript awesome list—it has a second level with topics like Frameworks annd Coverage.)
Sometimes the actual ul list of links will go down three or four levels.
But they’ve solved one of the major problems with hierarchical directories: needing to click too much to get down through the levels. The entire list is displayed on a single page. This is great.
The emphasis on “awesome” implies that this is not just a complete directory of the world’s links—just a list of those the editor finds value in. It also means that, in defense of each link, there’s usually a bit of explanatory text for that link. I think this is great too!!
The reason why most awesome lists use Github is because it allows people to submit links to the directory without having direct access to modify it. To submit, you make a copy of the directory, make your changes, then send back a pull request. The JavaScript awesome list has received 477 pull requests, with 224 approved for inclusion.
So this is starting to seem like a rebirth of the old “expert” pages (on sites like About.com). Except that there is no photo or bio of the expert.

As I’ve been browsing these lists, I’m starting to see that there is a wide variety of quality. In fact, one of the worst lists is the master list!! (It’s also the most difficult list to curate.)
I also think the lack of styling can be a detriment to these lists. Compare the Static Web Site awesome list with staticgen.com. The awesome list is definitely easier to scan. But the rich metadata gathered by the StaticGen site can be very helpful! Not the Twitter follower count—that is pointless. But it is interesting to see the popularity, because that can be very helpful sign of the community’s robustness around that software.
Anyway, I’m interested to see how these sites survive linkrot. I have a feeling we’re going to be left with a whole lot of broken awesome lists. But they’ve been very successful in bringing back small, niche directories. So perhaps we can expect some further innovations.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

Can the failing, impotent web directory be transformed? Be innovated??
Can we still innovate on the humble web directory? I don’t think you can view large human-edited directories (like Yahoo! or DMOZ) as anything but a failure when compared to Google. Sure, they contained millions of links and, ultimately, that may be all that matters. But a human editor cannot keep up with a Googlebot! So Google’s efficiency, speed and exhaustiveness won out.
But perhaps there is just no comparison. Perhaps the human-edited directory still has its strengths, its charms. After all, it has a human, not a GoogleBot. Could a human be a good thing to have?
We now have an abundance of blogs, news, podcasts, wikis—we have way too much really. Links constantly materialize before your very eyes. Who would even begin, in 2018, to click on Yahoo!'s “Social Science” header and plumb its depths?

Strangely enough, even Wikipedia has a full directory of itself, tucked in a corner. (Even better, there’s a human-edited one hidden in there! Edit: Whoa! And the vital articles page!) These massive directories are totally overwhelming and, thus, become more of an oddity for taking a stroll. (But even that—one usually begins a stroll through Wikipedia with a Google search, don’t they?)
The all-encompassing directory found another way: through link-sharing sites like Del.icio.us and Pinboard. If I visit Pinboard’s botany tag, I can see the latest links—plant of the week the “Night Blooming Cereus” and photos of Mount Ka’ala in Hawaii. Was that what I was looking for? Well at least I didn’t have to find my way through a giant hierarchy.
Where directories have truly found their places is in small topic-based communities. Creepypasta and fan site wikis have kept the directory alive. Although, hold up—much like Reddit’s sub-based wikis—these mostly store their own content. The Boushh page mostly links back to the wiki itself, not to the myriad of essay, fan arts and video cosplays that must exist for this squeaky bounty hunter.
Besides—what if a directory wasn’t topic-based? What if, like Yahoo!, the directory attempted to tackle the Whole Web, but from a specific viewpoint?
You see this in bookstores: staff recommendations. This is the store’s window into an infinite catalog of books. And it works. The system is: here are our favorites. Then, venturing further into the store: this is what we happen to have.

“But I want what I want,” you mutter to yourself as you disgustedly flip through a chapbook reeking of hipster.
Well, of course. You’re not familiar with this store. But when I visit Green Apple in San Francisco, I know the store. I trust the store. I want to look through its directory.
This has manifested itself in simple ways like the blogroll. Two good examples would be the Linkage page on Fogus.me, which gives short summaries, reminiscent of the brief index cards with frantic marker all over them. This is the staff recommendation style blogroll.
Another variation would be Colin Walker’s Directory, which collects all blogs that have sent a Webmention[1]. This serves a type of “neighborhood” directory.[2]
What I want to explore now is the possibility of expanding the blogroll into a new kind of directory.
Likes, upvotes, replies, friending. What if it’s all just linking? In fact, what if linking is actually more meaningful!
When I friend you and you disappear into the number twenty-three—my small collection of twenty-three friends—you are but a generic human, a friendly one, maybe with a tiny picture of you holding a fishing rod. With any luck, the little avatar is big enough that I can discern the fishing rod, because otherwise, you’re just a friendly human. And I’m not going to even attempt to assign a pronoun with a pic that small.

It’s time for me to repeat this phrase: Social Linking. Yes, I think it could be a movement! Just a small one between you and I.
It began with an ‘href hunt’: simply asking anyone out there for links and compiling an initial flat directory of these new friends. (Compare in your mind this kind of treatment of ‘friends’ to the raw name dumps we see on Facebook, et al.) How would you want to be linked to?
Now let’s turn to categories. A small directory doesn’t need a full-blown hierachy—the hierarchy shouldn’t dwarf the collection. But I want more than tags.
---
Link Title
url://something/something
*topic/subtopic format time-depth
Markdown-formatted *description* goes here.
Ok, consider the above categorization structure. I’m trying to be practical but multi-faceted.
topic/subtopic is a two-level ad-hoc categorization similar to a tag.
A blog may cover multiple categories, but I’m not sure if I’ll tackle that.
I’m actually thinking this answers the question, “Why do I visit this site?
What is it giving me?” So a category might be supernatural/ghosts if I go there
to get my fix of ghosts;
or, it could be writing/essays for a blog I visit to get a variety of longform.
An asterisk
would indicate that the blog is a current feature among this topic (and this
designation will change periodically.)format could be: ‘blog’, ‘podcast’, ‘homepage’, a single ‘pdf’ or ‘image’, etc.time-depth indicates the length one can expect to spend at this link. It could
be an image that only requires a single second. It could be a decade worth of blog
entries that is practically limitless.The other items: author, url and description—these are simply metadata that would be collected.
The directory would then allow discovery by any of these angles. You could go
down by topic or you could view by ‘time depth’. I may even nest these structures
so that you could find links that were of short time depth under supernatural/ghosts.
The key distinct between this directory and any other would be: this is not a collection of the “best” links on the Web—or anywhere near an exhaustive set of links. But simply my links that I have discovered and that I want to link to.
I don’t know why, but I think there is great promise here. Not in a return to the old ways. Just: if anyone is here on the Web, let’s discover them.
I should also mention that many of the realizations in this post are very similar to Brad’s own Human Edited vs. Google post, which I cite here as an indication that this topic is currently parallelized. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
We talk about the privacy and data ownership of the Old Web, but I think there are other sweet angles we left off there. I still hate the word blog, though.
The Old Web isn’t dead. It just got old enough that it constantly seems to leave the spreadsheet with all of its passwords open on the desktop. It is sinking into the sofa while images of a low-bitrate Spaghetti Western dance in its bifocals.
We decry the loss of privacy and data ownership that seemed to be there in the Old Web. And we always wish there had been security. However, there are other things we left in the pockets of that Old Gray Web on the couch.
It seems that everything is white and blue in the present day. We’ve settled on these neutral colors, in case we need to sell it all. The old garish animated construction cones and embedded MIDI files are relegated to Neocities now—and who even cares what that is?

When we post, we post a few words. A picture and a few words. Some gray words on white. With a little blue.
This is one reason I was happy to see RSS fall out of favor. I don’t really want to read everything in Arial, gray on white with a little blue. Blog posts that were beautifully arranged in their homes, now stuffed together into a makeshift public shelter of dreary gray and white and chalked around with a little line of blue.
Did Google’s killing Reader kill the web? Or did Reader at least do some initial trial strangling?

We had been bitten too deeply by Myspace—its many glittery backgrounds and flame-filled Lightning McQueen backgrounds, golden cash symbol backgrounds and spinning Cool Ranch chip backgrounds. (Incidentally, some of this made a return with Subreddit style; 4chan and creepypastas never left the Old Web.)
I always wondered if the term “blog” was supposed make the term “home page” sound cooler. They both empitomize the idyllic Early Internet. Maybe the idea of “home” just IS corny—you only ever see it cross-stitched.
We moved on to a cosmopolitan empire, where we’re all living in the street. My house is full of your shit. And my uncles’ and aunts’ shit. And The Donald’s, of course, and the sad, desperate slideshows that Facebook makes for me in its spare time—it’s been basking in my shit again, trying to find some meaning in those three pictures I posted of a metal chair I spray-painted. It turns them over and fades them out again and again to try to stir some vital force. It all ends too quick—I’m trying here, but you’re not yet worth a slideshow, kid.
Gah, how I miss a good arm’s length. Between myself and all those people, bots and algorithms analyzing me for the little fractions of a second I might get. But what am I talking about? I have a blog and you’re standing on it right now! Or maybe you’re not. It gets lonely out here and I’m talking to myself again. The handful of devoted Baidubots, who quietly read the journals I leave on the stoop, look up but don’t even want to admit they’re there.
Reddit helped this situation so much. You could have a blog AND have a public place to leave a card!
The trouble is that Reddit has become the Big Blog. You are welcome to post your stuff there. But it’s usually in gray and white with a little blue—so that I lose a sense of who I’m reading exactly, who they are and where they call home. Reddit isn’t keen on a link to your blog without an acceptable amount of foreplay. You’re not yourself, you’re a Redditor—ten to twelve letters with a little bit of flair, maybe a cake, maybe a gold star. Could I be so lucky?

This might be reaching: I think an actual home—a blog or a home page—gave people time to represent themselves. In a stream of faces, you have to leap up from the river and shout HEY, throw a stick before the current pushes on. That picture has to have all of you in there.
Twitter has done well with this. You can find yourself reading someone’s history there. But Facebook, Instagram, Reddit—these all leave you crammed in the subway.

The Web—Old Web and The Now—it’s all a public place. Every page is an exhibition. Maybe Reddit has it right. By draining away the individual to a few letters, it becomes all about the message that they post. It hearkens back to mailing lists, when all you knew was a person’s From field. Though there were signatures, too, I suppose.
I think this has blossomed into a nice devotion to their community, because a Redditor’s works are tied up there. Do Redditors ever wish their stuff was home—where they could style it, save it, share it elsewhere?
I was recently impressed by something in the FAQ for a service called Bridgy:
How much does it cost?
Nothing! We have great day jobs, and Bridgy is small, so thanks to App Engine, it doesn’t cost much to run. We don’t need donations, promise.
This too felt very Old Web. Part of the tension in the modern Web is that we expect free in a billions-dollar industry.
When one company is taking on everyone’s blogs and pictures and witty repasts, that takes a toll. But the cottage tilde blogs of yesteryear came with your Internet connection.
It was an age of building things. Mostly little communities that had to be sought out. You had your phpBBs out there and blogs for different topics that acted like subreddits, but weren’t definitive. You built your own brick in this.
It sounds like I’m asking for the suburbs back. We built the ideal metropolis—now move back to the suburbs? What for? The Arcade Fire once sang a song about how much that sucks!

I think it’s more like a grassroots community thing vs. a corporate complex we can all live in. You can see the advantage in a community like BoardGameGeek, which hasn’t found its equivalent in Facebook and Reddit and so on. It houses a community tailored to its topic—every board game has its rules questions and its variants, so forums are tailored to this. You can search through the tree of associations—who designed what game and what other games and expansions did they produce?
Yes, it’s gray and white with a LOT of blue. It’s graceless in a way. But it’s managed to stay alive and independent. And it coexists with Reddit. They link back and forth and have a grand old time. (BGG also encourages posting on a forum rather than on your blog.)
It feels like there’s still building to do. No BGG isn’t ideal—but what does it become? Communities can still build out their facilities. I wonder what happened with the maker community. Hackaday seems to link mostly to YouTube and Instructables. Top notch work is still posted there and all around us (and at /r/diy.) It just seems that the will to “make” your web has left this crowd.
I guess this brings us to the Indieweb where you can probably still call each other Netizens and bemoan the death of RSS. Even though it’s been around since 2013, I see a spark of hope in this ragtag group of HTMLists. (Why isn’t “ragtag” some kind of microformat for the homeless?)
Now, certainly the Old Web had its spam and trolls and barriers. Discovering each other from across the Web has always been difficult. At least millions of people can get on Twitter and attempt to flag down Robert Downey Jr. in realtime. I just wonder if the little builders of the Web out there can start to reconnect.
I see a few projects out there that are in the vein of what I mean.
Webmentions.
At first I thought these
were very odd. Reading some one’s comment on your blog from their web page
seemed… a mess. But, after tinkering for a bit, I’m sold! Yes, blogs
are forced to conform if they want to participate—this is both a troublesome
barrier to entry and perhaps a too forceful structuring of a blog. It works for
me; for some others. If not for you, that’s fine.
The dat:// Project.
Dat transmits your blog
from your actual home. We all want decentralized, right? I don’t think we need
to be peer-to-peer to be decentralized. However, I’m impressed at the robustness
of this network—and the quality of the Beaker Browser.
I do think this protocol directly addresses the point about the $0.00 blog.
Jekyll, Metalsmith, etc.
Static sites still seem pretty crucial. The hosting fees are low. You can
handle high traffic in spurts. And you can publish anywhere without needing
to set up a bunch of software. So much innovation could still happen here!
Why am I not excited by Mastodon? Or Secure Scuttlebutt? Or micro.blog?
These seem like great projects. My main issue with them is that everything posted is, once again, reduced to gray and white with a bit o’ blue. (In Mastodon’s case, invert those colors.) They address decentralization, but not the other bits.
Now, just let me know you’re out there. If I link to you and you link to me, that’s a pretty good start I’d say.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Some nice key combos for the combo-driven Firefox extension.
Having long been a fan of web-browsing with a keyboard—by way of the old Vimperator extension for Firefox—I have enjoyed its rebirth in the present incarnation of the Tridactyl extension.
As I’ve been adapting to the subtle differences, I’ve found myself browsing the complete list of key combos lately—trying to impress the useful combos into muscle memory. I’m going to jot some favorites here for future reference.
I know this is going to seem sketchy, like I’m hiding something, but I often find myself needing to clean cookies for a web site while I’m working on it.
:sanitize cookies -t 1h
This cleans all cookies set in the last hour. Wish I could narrow it to a specific domain name match.
Adding your own helpful signout command might look like:
:command signout sanitize cookies localStorage -t 1h
Never had this ability before: a combo to copy an HTML element’s text to the clipboard and then “put” it into the current tab—which will usually pass the text into your search engine. (If it’s a URL, though, it will just go there.)
;pP
The ;p allows you to yank the contents of a page element by name. And the
P puts (or pipes) the clipboard contents into a “tabopen” command.
(I think of this move as the “double raspberry”—it’s the emoticon upon one’s face when landing such a maneuver.)
It just so happens that the [[ and ]] keybindings work great on BGG
geeklists and Yucata.de forums. This is so much more convenient than follow
on those tiny fonts they often use.
I’ve bound the shifted J and K to tabprev and tabnext—hitting gtgtgtgt
over and over again was a bit too much of an exercise. Perhaps I would use that
hotkey more if it was possible to hold down g and hit t or T in repetition
to cycle.
:bind J tabprev
:bind K tabnext
In my mind, this works well with H and L to navigate history.
(Incidentally, to pop a tab out into a new window, use the :tabdetach command.
I tend to use this frequently enough that it should probably be bound—just
not sure where!)
This isn’t documented very well, but if you want to bookmark a site, you can
supply it’s URL to the bmark comand:
:bmark https://www.kickscondor.com/
These are not kept in the same list as your Firefox bookmarks—this is a flat list rather than a hierarchy.
There are some keys bound to some bookmark calls. Allow me to clear them up:
A bookmarks (or unbookmarks) the current URL.a does the same, but allows the URL to be edited first.M<key> gives the bookmark (at the current URL) a single character alias.
To use this, you must be on the bookmarked page.go, gn or gw—these expand to open,
tabopen and windowopen. (So: gwp will open a new window with the URL
aliased as “p”.)These three commands are created when you run the M command. So, to remove
these commands, you’ll need to do individually: :reset gnp and so on.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

In my first game of Rising Sun, a Kaiju came in from the sea—and what happened next brought a profound mix of delight and sadness.
This is the first in my Fables of Tables series. It’s a type of review series. But instead of dryly reviewing the game’s mechanics and stamping some harsh grade on its face, I’m just going to tell a story.
Today’s game is Rising Sun. This is a miniatures game—full of plastic monsters. I don’t really play miniatures games, but a friend had a copy so it just happened. And, what the blazes? A miniatures game in pastels?
Midway through the game, I noticed that you could buy a giant Godzilla-like monster to have in your crew.

“What’s the Godzilla do?” I asked.
And the friend who owns the game—I’ll call him Hustle—says, “Oh, he has five force.” So he’s huge—his power is equal to five whole army guys.
He goes on to explain that when you buy the Kaiju, you put him out in the sea—the whole board is a rough map of Japan and there is water surrounding the islands—so you put the monster out there, and then during battle you can spring him on to any of the game’s provinces and he’ll destroy all the buildings there. (The buildings are these strongholds where your units can appear.)
“Oh man!” I’m thinking. “Just like Godzilla! I love it! I gotta have it!”
I just really enjoy monster movies—particularly Shin Godzilla—that wail that sounds like metal sheets tearing and that slow, sinuous tail as he moves methodically through the cityscape. I get that he’s historically out of place in this game, but I don’t care! He is the force of the Earth fighting back against civilization—what if he could have done this in some bygone age?
The guy playing purple (don’t recall his name) buys the Kaiju before I can. This player is already in the lead and now has Godzilla, placing him in the sea. It is as if two titans of this world have allied and we are waiting for our defeat.
I look on wistfully at this being. Five force! I am in awe and I sit in anticipation of what the lurking god will do when war begins.
War arrives and the fellow playing purple brings Godzilla on to land in the northern province of Hokkaido. The Kaiju storms into the scene and—well, there are no buildings there—he has no effect. But still—this is an island teaming with monsters and warriors and look how Godzilla towers above them!!
Hustle reaches across the giant board and points. “Ok, so, you see, I have the Earth Dragon here.”
Hot snakes, I had forgotten about the Earth Dragon! So the Earth Dragon does not have the force that Godzilla has. However, the Earth Dragon is able to push away one unit from each opponent in the battle. It is as if the Earth Dragon takes a big breath and then >SNUFF< a bunch of guys fly off to other parts of the island.
Of course, he chooses to snuff off Godzilla. The Earth Dragon takes a big breath and a myriad of warriors and creatures scatter across the map. Godzilla is propelled all the way across the board—using a marked sea lane, I should add, since the winds of the dragons respect these rules as well—and he lands in Kyushu, destroying a few buildings when he lands.
War rages on and, before long, the spotlight shines on Kyushu. Godzilla has picked up the pieces and, with some tarnished pride, admirably overshadows the vast assembly of demons and gods there.
“Hang on,” says the player to my right, “my Fire Dragon goes first.”
Holy cats! Right! The Fire Dragon! This twisty, devious dragon coughs his terrible fireballs just as the battle forms—incinerating one unit for each opponent present in the conflict. Warriors and barbaric creatures fall away in the fire—and Godzilla himself, no, it can’t be! Can it??
Gods, it is true! The vast unshakable behemoth is now wildly dashing from the island in a pyre of his own burning scales. He tumbles down the beach, a maniacally flailing lizard, a lizard of flame and agony, howling his metal-rending chord.
The great Kaiju sinks back into the ocean—in shame and sorrow—having made no effect on the actual game at all. Like we never did any math with Godzilla involved. Literally no effect.
I sat there for some time after the game had concluded. Stunned and humbled. I contemplated the fate of Godzilla. Perhaps even the great gods get tossed and squashed and embarassed on a bad day.
Perhaps when I die, my Guardian—or my Saint or Kami—will approach me to greet me into a new kingdom. And she, too, may trip and fall into fire, to be engulfed and never seen again. These things happen. I realize that now.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

The thing—the key—the realization that’s needed before you can write shaders. Really, I think this will help.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

While trying to get JoyLabz Makey Makey 1.2 to work with an iPad, I discovered there is no way to reprogram it.
It seems like this information hasn’t been disclosed quite enough as it should: Makey Makey’s version 1.2, produced by JoyLabz, cannot be reprogrammed with the Arduino software. In previous versions, you could customize the firmware — remap the keys, access the AVR chip directly — using an Arduino sketch.
🙌 NOTE: Dedokta on Reddit demonstrates how to make a Makey Makey.
Now, this isn’t necessarily bad: version 1.2 has a very nice way to remap the keys. This page here. You use alligator clips to connect the up and down arrows of the Makey Makey, as well as the left and right arrows, then plug it into the USB port. The remapping page then communicates with the Makey Makey through keyboard events. (See Communication.js.)
This is all very neat, but it might be nice to see warnings on firmware projects like this one that they only support pre-1.2 versions of the Makey Makey. (I realize the page refers to “Sparkfun’s version” but it might not be clear that there are two Makey Makeys floating about—it wasn’t to me.)
⛺ UPDATE: The text on the chip of the version 1.2 appears to read: PIC18F25K50. That would be this.
Now, how I came upon this problem was while experimenting with connecting the Makey Makey to an iPad. Instructions for doing this with the pre-1.2 Makey Makey are here in the forums—by one of the creators of the MM.
With the 1.2 version, it appears that the power draw is too great. I received this message with both an iPad Air and an original iPad Mini.
Obviously a Makey Makey isn’t quite as interesting with an iPad — but I was messing with potentially communicating through a custom app.
Anyway, without being able to recompile the firmware, the iPad seems no longer an option. (The forum post should note this as well, no?)
If you do end up trying to get a pre-1.2 Makey Makey working with the latest Arduino, I ran into many problems just getting the settings right. The github repos for the various Makey Makey firmwares are quite dated.
One of the first problems is getting boards.txt to find my avr compiler. I had this problem both on Linux and Windows. Here’s my boards.txt that finally clicked for me:
############################################################################
menu.cpu=Processor
############################################################################
################################ Makey Makey ###############################
############################################################################
makeymakey.name=SparkFun Makey Makey
makeymakey.build.board=AVR_MAKEYMAKEY
makeymakey.build.vid.0=0x1B4F
makeymakey.build.pid.0=0x2B74
makeymakey.build.vid.1=0x1B4F
makeymakey.build.pid.1=0x2B75
makeymakey.upload.tool=avrdude
makeymakey.upload.protocol=avr109
makeymakey.upload.maximum_size=28672
makeymakey.upload.speed=57600
makeymakey.upload.disable_flushing=true
makeymakey.upload.use_1200bps_touch=true
makeymakey.upload.wait_for_upload_port=true
makeymakey.bootloader.low_fuses=0xFF
makeymakey.bootloader.high_fuses=0xD8
makeymakey.bootloader.extended_fuses=0xF8
makeymakey.bootloader.file=caterina/Caterina-makeymakey.hex
makeymakey.bootloader.unlock_bits=0x3F
makeymakey.bootloader.lock_bits=0x2F
makeymakey.bootloader.tool=avrdude
makeymakey.build.mcu=atmega32u4
makeymakey.build.f_cpu=16000000L
makeymakey.build.vid=0x1B4F
makeymakey.build.pid=0x2B75
makeymakey.build.usb_product="SparkFun Makey Makey"
makeymakey.build.core=arduino
makeymakey.build.variant=MaKeyMaKey
makeymakey.build.extra_flags={build.usb_flags}
I also ended up copying the main Arduino platform.txt straight over.
Debugging this was difficult: arduino-builder was crashing (“panic: invalid memory address”) in create_build_options_map.go. This turned out to be a misspelled “arudino” in boards.txt. I later got null pointer exceptions coming from SerialUploader.java:78 — this was also due to using “arduino:avrdude” instead of just “avrdude” in platforms.txt.
I really need to start taking a look at using Ino to work with sketches instead of the Arduino software.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

Sometimes your PWM pin is tied up doing SPI. You can still salvage the PWM timer itself, though.
Right now the spotlight is stolen by lovely chips like the ESP8266 and the BCM2835 (the chip powering the new Raspberry Pi Zero). However, personally, I still find myself spending a lot of time with the ATtiny44a. With 14 pins, it’s not as restrictive as the ATtiny85. Yet it’s still just a sliver of a chip. (And I confess to being a sucker for its numbering.)
My current project involves an RF circuit (the nRF24l01+) and an RGB LED. But the LED needed some of the same pins that the RF module needs. Can I use this chip?
The LED is controlled using PWM — pulse-width modulation — a technique for creating an analog signal from code. PWM creates a wave — a rise and a fall.
This involves a hardware timer — you toggle a few settings in the chip and it begins counting. When the timer crosses a certain threshold, it can cut the voltage. Change the threshold (the OCR) and you change the length of the wave. So, basically, if I set the OCR longer, I can get a higher voltage. If I set a lower OCR, I get a lower voltage.
I can have the PWM send voltage to the green pin on my RGB LED. And that pin can be either up at 3V (from the two AA batteries powering the ATtiny44a) or it can be down at zero — or PWM can do about anything in between.
My problem, though, was that the SPI pins — which I use to communicate with the RF chip — overlap my second set of PWM pins.
You see — pin 7 has multiple roles. It can be OC1A and it can also be DI. I’m already using its DI mode to communicate with the RF module. The OC1B pin is similarly tied up acting as DO.
I’m already using OC0A and OC0B for my green and blue pins. These pins correspond to TIMER0 — the 8-bit timer used to control those two PWM channels on OC0A and OC0B. To get this timer working, I followed a few steps:
// LED pins
#define RED_PIN PA0
#define GREEN_PIN PB2
#define BLUE_PIN PA7
Okay, here are the three pins I want to use. PB2 and PA7 are the TIMER0 pins I was just talking about. I’m going to use another one of the free pins (PA0) for the red pin if I can.
DDRA |= (1<<RED_PIN) | (1<<BLUE_PIN);
DDRB |= (1<<GREEN_PIN);
Obviously I need these pins to be outputs — they are going to be sending out this PWM wave. This code informs the Data Direction Register (DDR) that these pins are outputs. DDRA for PA0 and PA7. DDRB for PB2.
// Configure timer0 for fast PWM on PB2 and PA7.
TCCR0A = 3<<COM0A0 | 3<<COM0B0 // set on compare match, clear at BOTTOM
| 3<<WGM00; // mode 3: TOP is 0xFF, update at BOTTOM, overflow at MAX
TCCR0B = 0<<WGM02 | 3<<CS00; // Prescaler 0 /64
Alright. Yeah, so these are TIMER0’s PWM settings. We’re turning on mode 3 (fast PWM) and setting the frequency (the line about the prescaler.) I’m not going to go into any detail here. Suffice to say: it’s on.
// Set the green pin to 30% or so.
OCR0A = 0x1F;
// Set the blue pin to almost the max.
OCR0B = 0xFC;
And now I can just use OCR0A and OCR0B to the analog levels I need.
Most of these AVR chips have multiple timers and the ATtiny44a is no different — TIMER1 is a 16-bit timer with hardware PWM. Somehow I need to use this second timer to power th PWM on my red pin.
I could use software to kind of emulate what the hardware PWM does. Like using delays or something like that. The Make: AVR Programming book mentions using a timer’s interrupt to handcraft a hardware-based PWM.
This is problematic with a 16-bit timer, though. An 8-bit timer maxes out at 255. But a 16-bit timer maxes out at 65535. So it’ll take too long for the timer to overflow. I could lower the prescaler, but — I tried that, it’s still too slow.
Then I stumbled on mode 5. An 8-bit PWM for the 16-bit timer. What I can do is to run the 8-bit PWM on TIMER1 and not hook it up to the actual pin.
// Setup timer1 for handmade PWM on PA0.
TCCR1A = 1<<WGM10; // Fast PWM mode (8-bit)
// TOP is 0xFF, update at TOP, overflow at TOP
TCCR1B = 1<<WGM12 // + hi bits
| 3<<CS10; // Prescaler /64
Okay, now we have a second PWM that runs at the same speed as our first PWM.
What we’re going to do now is to hijaak the interrupts from TIMER1.
TIMSK1 |= 1<<OCIE1A | 1<<TOIE1;
Good, good. OCIE1A gives us an interrupt that will go off when we hit our threshold — same as OCR0A and OCR0B from earlier.
And TOIE1 supplies an interrupt for when the thing overflows — when it hits 255.
Now we manually change the voltage on the red pin.
ISR(TIM1_COMPA_vect) {
sbi(PORTA, RED_PIN);
}
ISR(TIM1_OVF_vect) {
cbi(PORTA, RED_PIN);
}
And we control red. It’s not going to be as fast as pure PWM, but it’s not a software PWM either.
I probably would have been better off to use the ATtiny2313 (which has PWM channels on separate pins from the SPI used by the RF) but I needed to lower cost as much as possible — 60¢ for the ATtiny44a was just right. This is a project funded by a small afterschool club stipend. I am trying to come up with some alternatives to the Makey Makey — which the kids enjoyed at first, but which alienated at least half of them by the end. So we’re going to play with radio frequencies instead.
I imagine there are better other solutions — probably even for this same chip — but I’m happy with the discovery that the PWM’s interrupts can be messed with. Moving away from Arduino’s analogWrite and toward manipulating registers directly is very freeing — in that I can exploit the chip’s full potential. It does come with the trade off that my code won’t run on another chip without a bunch of renaming — and perhaps rethinking everything.
Whatever the case, understanding the chip’s internals can only help out in the long run.
If you’d like to see the code in its full context, take a look through the Blippydot project.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

I often have the students concoct their own story problems. I highlight the most insane.
I often have the students concoct their own story problems. Lately, I’ve been using a tablet-based drawing tool along with some stickers from Byte. (I would love to use Byte—but it doesn’t live up to COPPA.)
One kid came up with the pictured story problem. Pardon the grammar—we didn’t proofread these.

To clear this up: the lemon is struck by lightning 117 times each day! This lemon also appears to be alive, unlike the unfortunate turtle and teacup that found themselves stuck on the same hillside.
He is also probably actually a lime. How would that be—to have your key identity discarded during this defining moment? Maybe this is that elusive lemon-lime that the soft drinks always talk about.
Clearly we are dealing with a tough fellow here—an affluent, though morose, lemon-maybe-lime. We all hurriedly dashed out the answer so that we could know exactly how many strikings this poor citrus had endured! It was a tough four days.
Now for this one.

I asked the student, “Will the hobo still blow the monkey up after he spends his $40,000?”
He said, “He’s going to blow him up no matter what.”
Wealthy monkeys, don’t do business with hoboes! Especially hoboes trafficking 18 mil in explosives! That seems suspicious to me.
The last story problem I want to mention never actually materialized, but this next one is a math-in-feelings problem.
It went like this:
(Student who has been at the counselor’s office arrives late for the activity.)
Me: “Ok, (Student). We’re coming up with story problems.”
Student: “Oh, I know what mine is!”
Me: “Let’s hear it.”
Student: “Ok. There are two guys. And they’re neighbors.”
Me: “Sounds good.”
Student: “And they hate each other in a hundred different ways.”
Me: “Oh, wow.”
Student: “But they love each other in a hundred different ways.”
Me: “So they cancel each other out.”
Student: “No, so you take all of their feelings—how many feelings all together do they have for each other?”
One of the kids next to us goes, “Four hundred feelings!” jubilantly.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

A detour: three weeks teaching Twine at school. Implications feel profound.
At the beginning of the year, the principal came to me and said, “I’m going to have you help with the after-school computer club. It’s a club for fourth- and fifth-graders.”
I was like, well, yeah, I’m the computer teacher, that makes sense.
She tells me the first grade teacher is in charge and I’ll just help her.
Perfect. This particular teacher is a close friend and this probably means we can do what we want.
“And code.org is going to give you all the stuff.”
Ok, no sweat. We’ll take a look.
A month ago, I walk into the first grade teacher’s room and she’s got this little pile of stuff on her desk.
I go, “What’s all this?”
It’s the stuff from code.org. A cup. A packet of seeds. A gumball. Dirt.
She’s like, “I don’t get this.”
I clear a space and start to look over the paper she’s got—it’s this lesson plan that goes with the cup. And the dirt. (Wait—is that real dirt?)
Now, I’m just a computer teacher at a public elementary school—meaning I am absolutely the bottom of the chart on Career Day—like you do NOT bring up my job as some kid’s future—I am next to the guy selling Japanese dexterity games out of a kiosk at the mall—same guy who dresses in gold spandex and gets to be the Snitch in college Quidditch games—you don’t see him for two hours until you notice him above the quad, scaling the political science building—so, yes, a paltry elementary school computer teacher, but I have to tell you: I would never teach computer programming with a cup of dirt and a gumball. Nut uh. Not the way they’ve got this.[1]
So we bag that.
“Ok, good,” she says. “So I’m not crazy.”
She is. All humans are. But now’s not the time.
She seems relieved at first. Until she goes on. “So the next thing is: zombies.”
Couple clicks and her Macbook is showing the zombie lesson. In this lesson, all the kids get a zombie.[2] You basically control a zombie with code. You make it walk. Lurch forward, lurch left, lurch forward, lurch left, lurch left, lurch, lurch, lurch, then lurch right. That kind of thing.
“It’s not bad,” I say.
“I just don’t get why,” she says. “What is this for? Like: is this really teaching code?”
I’m thinking that, well, it kind of does—I guess?
“Code.org is like a million-billion dollar thing, isn’t it?”
“Well, Mark Zuckerberg,” she says. “And I think President Obama is in the video. Or he’s on the site or something.”
We look. Yeah, that IS Obama.
“So we’ll work for an hour and the kids will have made a zombie walk around a bit.”
So we bag that.
Fortunately—meaning this is where our fortune left the realm of mere dirt and a little bit of zombie walking—I had recently played a game called HIGH END CUSTOMIZABLE SAUNA EXPERIENCE. And somehow my thoughts turned toward this game, of which I recalled two things. For one, I remembered something about hacking into a cupcake in the game, which was certainly a fond memory. And then, the other thing, of course, what also came to mind, is that the game was a Twine game. A hypertext game. Made by Twine—some kind of neat way of building these games.
I pulled it up on her Macbook. Fifteen minutes later, we were like: “This. We are doing this.”
So we covered Twine for the first three weeks of the club. The first day we just showed them how to link.[3] This was actually plenty. I think this could have gone on for three weeks alone. One of the kids came up with this game THE BLOOD FLOOD. And, in his game, everywhere you went, THE BLOOD FLOOD showed up. Like this tsunami of gore.
Another girl came up with this game where you just lose. Over and over, you just lose. First you die. Then you lose a hundred points. Then your mom traps you and you lose. And then you die and you’re broke.
Great game. Pretty lifelike.
I expected the crazy stories. What really surprised me was: a kid showed me his project and it was a map of his family, done using Twine links. So he had links for his sister and mother and father and grandparents. And you could navigate his whole family and learn about them.
The creative story side didn’t appeal to him. He wanted to use the information housing and organization aspect of programming. It was a database.
So the kids universally loved the first week. (Kids love a lot of things, though.)
Second week we ran into problems getting everyone’s pages loaded. Not everyone was using the same laptop that they used the first week. So that can be a bit of a setback when using Twine—you’ll need to archive your stories and put them on a USB stick or something. Technically, the district’s user profile sync stuff should have brought down all the Chrome settings. However, I guess it doesn’t do anything with Chrome’s LocalStorage. So some kids had to start over. It was okay—they’re a resilient bunch. All humans are. But this problem, coupled with the time required to subsequently be resilient, meant we couldn’t cover as much.
We talked about the set: command and the if: command. The point was to help them see how to pick up things and how to give the player coins, swords and other trinkets one might take a-questing.
One kid wrote this dungeon where you could pick up a sword—and the sword is at 100%—so it’s like (set: $sword to 100).
And then, as you fight through the dungeon, the sword wears down.
So: (set: $sword to $sword - 5).
And then when it’s at zero, it’s useless.
(if: $sword > 0)[Take another [[swing]]?]
I was blown away by how much they could do with a simple variable and a conditional statement. I mean how. How are we spending time drawing shapes, lurching left, lurching right, when you can do all this great stuff with a variable and an if? I realize Papert did it this way—with shapes, with lurching—not with zombies but with turtles. Who am I to question Papert? Look him up on the career chart.
To me, this is incredible. On our first day, we were making actual games—text games, yes, but fun ones. I should have known better. I mean this is the generation that plays Minecraft for fun.
They were actually building the game logic. Like in a meaningful way—by turning these abstract constructs into concrete, actual iron swords that wear down.
The beauty of Twine is that your variables persist—they last the whole game. Doing this with straight JavaScript and HTML would be such a hassle to teach. There’s no need to understand scope or storage or anything like that. You’re just putting stuff in little cups. Not irrelevant dirt or gumballs. But REAL imaginary coins.
Initially I had planned to write some macros to help with inventory in Twine. I’m so glad I didn’t. By forcing the kids to use the basic constructs directly, they were able to grasp the rudiments and then apply those throughout their games.
Too often I see sites (like codecombat.com comes to mind) which give a kid an API to use. Like useSword(), turnRight(), openDoor(). I can’t understand this. It is teaching the API—not the simple constructs. Anyway, should we really be starting right into objects, methods, arguments and all that?
Our third lesson covered adding images, music, colors and text styling. I’m not as happy with Twine’s absence of syntax here—you’re basically just doing HTML for most things. But I also felt it would be good for them to dip their toes in HTML. For some kids, they didn’t care to take the time to use this tougher syntax just to put a picture in there.
They also struggled with stuff like (text-style: “rumble”). They loved the effect—esp. the two girls doing a graveyard adventure—but they didn’t like having to get everything perfect—the double-quotes, the colon, the spacing. This kind of syntax is a hurdle for them. Typing skills are still needed. This is a generation of iPhone users.
In all, my experiment using Twine went great—super great—they could do this every week and be content. There are a lot of movements out there to try to teach computer hacking, but they all really miss the mark in a way that Twine doesn’t. They don’t get railroaded into solving mazes. The kids come away with a real game.
In case you don’t believe me: Real-life Algorithms. ↩︎
Twine kind of follows the wiki-style of linking. You simply surround a phrase by double square brackets. Like so: [[Johnston St.]] Now it’ll create a new story page for Johnson St. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

A speech I like to give—my beliefs wrt Nicolas Cage.
This is a speech I like to give my students about my beliefs with regard to Nicolas Cage, to clear up any misunderstanding. Please contact my office if you would like me to give this speech at your school or at a civic meeting.
Let’s get right to it.
I believe in Nicolas Cage.
I believe he is real.
I believe that he is not a projection of my mind. I could not have invented Nicolas Cage—that much I know.
I believe he lives.
I believe that he believes that he lives. Which I find even more convincing.
I believe in him—that he’ll go far in life. He already has gone far, yes, but he will go far again and again.
I believed him in National Treasure when he said he would be stealing The Declaration of Independence. He did.
I believed him in National Treasure 2 when he said he would be kidnapping The President of the United States of America. He did.
I believe in the “nouveau shamanic” style of acting that this man employs.
And so I believe that there was no script for the National Treasure movies. I believe we are simply watching a man go about his daily routine. I believe that, right now, Nicolas Cage is solving national mysteries and nerding out over rare coins. He could be travelling back in time to kill Betsy Ross. He could be fighting a giant lizard-enhanced Benedict Arnold and walking on a bridge made of rare historical documents—a bridge which he himself made using a power like Iceman has—but with rare historical documents in place of ice.
I believe Diane Kruger is with him on these escapades.
I believe the quiver-like document case that he has slung over his shoulder, and which he often carries The Declaration of Independence in, except when he’s faking out Sean Bean’s character, is made from the hollowed out wooden leg of President Zachary Taylor. I believe that, at the time of his presidency, people suspected that Zachary Taylor had a wooden leg—but they said nothing, because it was possible he was using it to traffick state secrets and important rare and historical documents.
However, I believe that President Taylor NEVER COULD HAVE imagined that his leg would one day carry The Declaration of Independence. I believe this information would have been too much. I believe he would have turned away from his destiny and began a new quest to destroy the leg, in a misguided attempt to save The Declaration of Independence.
But I believe you can’t change the timeline. I believe everything happened as it should. I believe in the vindication of the Gates family. I believe Diane Kruger should have rightfully had the missing 1789 button for George Washington’s inauguration and that part of Nicolas Cage’s destiny was to help her complete the full set. It makes sense and I believe Diane Kruger collects masonic aprons as well.
I believe that they DID heat up the back of The Declaration of Independence together with their breath, though I believe Nicolas Cage’s breath accounted for more than two-thirds of that exhalatory heat. I believe that Diane Kruger’s breath was very hot as well, though, considering that it only took them one breath—and not even a particularly strong one at that—though not a bad one either—a good breath—a generous but not strengthful breath—just one breath to heat up the whole corner of The Declaration of Independence. I mean that’s pretty good!
I believe the “national treasure” referred to in the title of the film series is not The Declaration of Independence, nor is it The President of the United States, nor is it the sweet steampunk glasses of Benjamin Franklin—I believe it’s Nicolas Cage duh.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

How to teach — with an eye to Plato and Vygotsky
It was Christmas—and I binged on Piaget videos. And later that week, the grainy Seymour Papert documentaries where he has kids acting like robots in a field. Left! Left! LEFT! And I made several meals of Susan Engel’s essay on Curiosity. And then had it all dashed apart by Vygotsky.
Okay. Good. However—how should I teach? All this theory swimming around so impressively. What to actually say and do?
I was recommended The Educated Mind by Bret Victor at the 20 minute mark in a talk of his[1]. Turns out this is truly a lovely book. It attempts to sum up all the theory. Everything from Plato to Piaget, Vygotsky to Carl Sagan. (Even devoting a hearty portion to irony—a virtue which never seems to get its due.) After half the book mulling over the theories, we move into practical discussion of how to materialize all of this lofty thinking into teaching our real classes. Much like the real classes I teach in one corner of an old brick elementary.
Now, it’s funny. At the same time that I find myself troubled with how to teach, I realize there is almost no other way to do this. As the King of Hearts said, “Begin at the beginning and go on till you come to the end: then stop.”
We recapitulate. We take a young one through the alphabet and all the numbers and symbols, the great novels and how to sketch with perspective and how to disassemble a frog—all that we once went through. We relive a history with them.
It is through this interiorization of historically determined and culturally organized ways of operating on information that the social nature of people comes to be their psychological nature as well.[2]
This interiorization happens through understanding. Kieran Egan covers the many ways of understanding—he lists his five most crucial types—like Mythically, in which we deal with binary concepts and construct imaginary beings that dwell at the extremes. Romantically, in great stories that pretend to have some grand purpose. As well as Philosophic, Somatic and Ironic.
These are not mere gimmicks. We often rely, in small children, on their mythical understanding. We don’t need to explain Hansel and Gretel.
The narrator does not explicitly discuss and explain the concepts of opposition—in this case, security and fear. We presuppose that in some profound way children already know these concepts; the narrator is using their familiarity to make events in some distant forest at some distant time meaningful.[3]
These early chapters on mythical and romantic understanding are wonderful. The mythical section studies the import of fairy tales and Peter Rabbit to toddlers; the romantic part studies both Herodotus and The Guinness Book of World Records, the appeal of high drama and human limits to adolescents. I found so many of his questions to be top notch.
[B]y far the most common learning principle urged on teachers is that children’s learning moves “from the known to the unknown,” and that, to engage their interest and make new knowledge meaningful, one must begin with something relevant to their everyday experience and connect the new knowledge to that. If this indeed is how children learn most effectively, one must wonder what does the fattest person who ever lived have to do with their everyday experience, or the most expensive postage stamp, or the longest beard?[4]
So the theory isn’t too detached from practice. Find the extremes in the subject you’re teaching, the soul of it. Play to the bizarre and the novel. It’s not quite as simple as that, of course—leave room for a touch of irony.
By preserving the earlier kinds of understanding as much as possible, we may develop a kind of irony that enables its users to recognize validity in all perspectives, to believe all metanarratives, to accept all epistemological schemes, to give assent to every belief. […] we do have other pursuits than understanding, and for some of the more exotic amoong them magic will trump science.[5]
Wow, this kind of thing has got to be a heresy in today’s society! The predominant notion today is that our goal is progress, our goal is a perfect truth and knowledge. To be brought back to Socrates and Nietzche—who suggested that the pursuit of truth is only driven by “wanting to be superior”[6]—gives the feeling of an old great truth: that we are really just working with scraps of the universe here. Not the keys to ultimate truth that we pretend.
As a technology teacher, this helps remind me that maybe technology is more of a magical substance than it is a great medicine for society. A realization that cannot come quick enough now that our ideals about social media have been dispelled by the absence of the interpersonal advances we were promised. No, it was all just a trick of getting messages from here to there, not a new form of living.
The final chapters take apart how to structure actual lessons. He falters a bit here—I feel there aren’t quite enough good examples given. But he does give a few very good ones. Such as when he discusses teaching about the air around us in a mythical way.
All in all, though, very near five stars here. I read books not to agree with the authors, but to think. To mull over someone else’s thoughts, in order to find where mine stand. But this book very much influenced me. I know I will be staying close to it from now on.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Using Xcode 7’s new ‘sideloading’ to prototype.
OpenFL is good. It is pleasing. This we know. It makes computer programs. However, it is itself one of these programs. Gah! So it is actually very bad and frustrating! But oh how we love it still—we needn’t be primates.
Okay, let’s see how good it is with the new Xcode. This new Xcode 7 lets us sideload. Yes, it’s true. It lets us put our mobile programs into our mobile computers without anything special—without a premium account of any kind or any permission—as if we were now in control.
How it does this is by granting us little licenses through a plain, average Apple ID. We will need to tell Xcode about our account. And we will need to create these things called provisioning profiles for each one of our apps. And we will need to click the Fix Issue button many times. More to come on that.
For this, you must have OpenFL installed for Mac. Download the latest Haxe from that page and then run, in a Terminal:
$ haxelib install openfl
$ haxelib run openfl setup
Now, let’s get a sample going.
$ openfl create NyanCat iNyanCat
$ cd iNyanCat
OpenFL already has a number of sample programs—we’re copying the built-in NyanCat sample for our purposes. It’s true that Nyan Cat is not as funny as it used to be, but it is funny enough for Xcode to at least compile.
Edit the project.xml file in there.
<meta title="NyanCat" package="org.openfl.samples.nyancat"
version="1.0.0" company="OpenFL" />
Best to change the Bundle Identifier. (The package setting above.) This has to be globally unique (as in one-of-a-kind on all of planet Earth) so put something in that’s peculiar.
<meta title="NyanCat" package="com.kickscondor.nyancat"
version="1.0.0" company="OpenFL" />
I am also using the beta release of Xcode 7. So it was necessary to use xcode-select to point OpenFL in the right direction.
$ sudo xcode-select -s /Applications/Xcode-beta.app/Contents/Developer
Right ok. Back to trying to get this thing to come up.
$ openfl test ios
The openfl test ios command will be very chatty—screens and screens for several minutes. It is making something for us.
⛺ Plug in the iPad or iPhone at this point. If this is your first time connecting it, tell it to Trust this computer.
Hold up.
=== BUILD TARGET NyanCat OF PROJECT NyanCat WITH CONFIGURATION Re
lease ===
Check dependencies
Code Sign error: No matching provisioning profiles found: No prov
isioning profiles with a valid signing identity (i.e. certificate
and private key pair) matching the bundle identifier “com.kicksco
ndor.nyancat” were found.
CodeSign error: code signing is required for product type 'Applic
ation' in SDK 'iOS 9.0'
** BUILD FAILED **
The following build commands failed:
Check dependencies
(1 failure)
It’s true—this thing it’s saying about the provisioning profile is true. We have no provisioning profile. This isn’t confusing. All error messages are repellant, so, no, you can’t look directly at it, but it’s speaking the truth to you.
Normally, if your program is in Apple’s store, you would go to Apple’s site to fix this. You would follow something like these steps. But we want to use Xcode 7 for this.
If you haven’t intuited this already, you must install Xcode 7.
Go into the Export/iOS folder under the iNyanCat folder. Open the iNyanCat.xcodeproj file.
Clicking on the bolded NyanCat project name on the left side of Xcode will show a page with this at the top:
And now we create the team profile. From the Team selector, choose Add an account… and enter your Apple ID credentials.
A Fix Issue button will appear. Press it.

You may also want to be aware of the Deployment Target area.
Sometimes upping the version on this will get you through problems.
At this point, you could just run the project from Xcode. (If you want to do that, just click on the arrow in the toolbar—the one that looks like a Play button—but be advised that it will take FOREVER to build.)
So, no, let’s not—let’s head back to the Terminal, as our build was almost complete when we had the provisioning profile problems.
$ openfl test ios
And it should appear on the iPad.
[ 60%] InspectingPackage
[ 60%] TakingInstallLock
[ 65%] PreflightingApplication
[ 65%] InstallingEmbeddedProfile
[ 70%] VerifyingApplication
[ 75%] CreatingContainer
[ 80%] InstallingApplication
[ 85%] PostflightingApplication
[ 90%] SandboxingApplication
[ 95%] GeneratingApplicationMap
[100%] Installed package /Users/kicks/Code/iNyanCat/Export/ios/bu
ild/Release-iphoneos/NyanCat.app
Yes, so basically now you can just stick to the Terminal and rebuild your app without needing to do anything with Xcode again.
The only issue that arises is if you want to create another new app.
You will need to edit the project.xml and change the Bundle Identifier in the new project. It’s a different app, it needs its own Id.
You will need to load the xcodeproj file into Xcode and hit Fix Issue again. This will assign this Bundle Identifier to your account. It’s like reserving a spot with Apple.
And then you should be in business for that project.
I had my share of problems—I will now relive these with you.
First, this one.
[....] Waiting up to 5 seconds for iOS device to be connected
[....] Using (null) (679c2f770cab0a8d8dc691595a8799b6aee88ca0).
------- Install phase -----
[ 0%] Found (null) connected through USB, beginning install
Assertion failed: (AMDeviceIsPaired(device)), function handle_
device, file ios-deploy.c, line 1500.
This means your iPad needs to trust. Unlock the iPad and you should see a popup: Trust this computer? Yes, please.
Next problem:
[ 60%] TakingInstallLock
[ 65%] PreflightingApplication
[ 65%] InstallingEmbeddedProfile
[ 70%] VerifyingApplication
AMDeviceInstallApplication failed: 0xE8008015: Your application
failed code-signing checks. Check your certificates, provisioning
profiles, and bundle ids.
I opened Xcode and discovered that the iPad Mini I had hooked up was listed as “ineligible.”
If your device is listed as “ineligible” then this means that the Xcode you’re using doesn’t include a Developer Disk Image for that specific version of iOS. In my case, I had 8.0.2 on the iPad Mini. What on earth causes a missing Developer Disk Image, though? Well, let’s see what’s included in my Xcode 7 installation:
$ ls /Applications/Xcode-beta.app/Contents/Developer/Platforms/iPhoneOS
.platform/DeviceSupport
6.0/ 7.0/ 8.1/ 8.3/ Latest@
6.1/ 7.1/ 8.2/ 9.0 (13A4280e)/
These are the versions I can sideload on to. As you can see, 8.0.2 is not present. The simplest way to solve this is for me to upgrade my iPad Mini to one of these versions.
You may also need to look for a newer Xcode release. I had problems with this because I had upgraded to iOS 8.4 on an iPad, but—as seen above—Xcode didn’t support iOS 8.4 yet. My device was ineligible because it was way too upgraded.
This problem also persisted when I hadn’t loaded symbol files onto the iPad Mini. Return to Xcode and load the xcodeproj file and ensure you can deploy to the device from there—once again, “Fix Issue” is your friend.
Here’s another one that plagued me for awhile.
[ 52%] CreatingStagingDirectory
[ 57%] ExtractingPackage
[ 60%] InspectingPackage
[ 60%] TakingInstallLock
[ 65%] PreflightingApplication
AMDeviceInstallApplication failed: -402653058
I tried upgrading the ios-deploy tool that comes with OpenFL. No good. I tried entering device information into the project.xml. Not that either.
I believe it went away when I started using Xcode to setup the provisioning profile. Xcode will connect to the device and put symbol files on it. You might try using Xcode’s arrow button (looks like a Play button on an audio player) and select your iPad in the area right next to the button. It will take a long time—but it only needs to happen once.
There also was this troublesome error that appeared while openfl test ios was running.
clang: error: -fembed-bitcode is not supported on versions of iOS
prior to 6.0
There are two possible solutions here. First, this is fixed in lime 2.4.8. So run haxelib list and ensure that lime is at least more recent than that. If not, run haxelib upgrade. 👈 Do this anyway—seems intellegent.
Second option is to simply open the XCode project and change the deployment target to (at least) iOS 6.0. (Bitcode enables the Apple Store to optimize your binary, at the cost of losing access to iOS 5.)
chmod: Unable to change file mode on /usr/lib/haxe/lib/lime/2,4,8
/templates/bin/ios-deploy: Operation not permitted
sh: /usr/lib/haxe/lib/lime/2,4,8/templates/bin/ios-deploy: Permis
sion denied
This one can be solved by manually making the file executable using sudo:
sudo chmod 0755 /usr/lib/haxe/lib/lime/2,4,8/templates/bin/ios-deploy
I also had difficulties getting the MongoDB driver for Haxe going under iOS. It worked fine for local testing (openfl test neko) but not for the device. I got compiler errors.
I forked the driver and made some alterations. Try this.
$ haxelib git mongodb-kicks https://github.com/kickscondor/mongo-haxe-driver
Add then add to your project.xml:
<haxelib name="mongodb-kicks" />
It is nice little touches like this, such as being able to bring in forked code from Github, that make OpenFL such a pleasure—even when it’s in a somewhat crabby mood about having to move itself onto such a suffocating platform such as Apple’s.
⛺ UPDATE: Recent versions of Xcode (7.2, for example) have a few different error messages that I thought I would cover also.
------- Install phase -----
[ 0%] Found XXX 'DeviceName' (...) connected through USB, beginning install
Assertion failed: (AMDeviceIsPaired(device)), function handle_device,
file ios-deploy.c, line 1500.
This one is a trust issue. Unlock your iPad or iPhone. You should see a dialog box asking if you want to trust this computer. Tap Trust.
You may also need to unplug the device and then plug it back in. This error can persist even after tapping Trust.
[ 65%] PreflightingApplication
[ 65%] InstallingEmbeddedProfile
[ 70%] VerifyingApplication
AMDeviceInstallApplication failed: 0xE8008016: Unknown error.
This is a code-signing issue. You want to use the Fix Issue button in Xcode. (See the And So Now It Just Works? section above for some instructions.)
Lastly, there’s a new popup on iOS that will block your app, with the title Untrusted Developer. The message continues: Your device management settings do not allow using apps from developer “iPhone Developer: [email protected] (XXXX)” on this iPad. You can allow using these apps in Settings.
The solution to this is in iOS Settings. Go to the Settings app. The General settings > tap Profile > tap [email protected] (or whatever the e-mail address was in the warning above.) Now trust [email protected]. And click Verify app. Go back to your app and it should run.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.