The beginning of a new series where readers thoroughly interview themselves.
Some time ago, I had a reader send me a very curious e-mail. It was an interview
that they had conducted. In fact, they had interviewed themself!
At first, this was very puzzling. But, on some reflection, I realized what a
gift this was! I don’t like my part of the interview very well anyway. This is
the answer!
Also I can’t stress to you enough - THIS IS NOT FICTIONAL OR SOME KIND OF HOAX.
This is actually an e-mail I received of someone interviewing themselves. Feel
free to contribute your own if you want to. I am beyond serious. I’m in some
kind of state of eigenseriousness that goes by the street name of CAVE. AGED.
CHEDDAR.
> Herb Quine enters the digichat.
Herb Quine:
You are invited to a house boat party at Ted Nelson’s place. What do you bring?
Herb Quine:
A dozen balloons and a first edition of “Lagos During The 80s - The Birth Of
Competitive Knitting In An Era Of Overinsurance” by Lula Drury. Also, a pet
hamster in case Werner Herzog shows up.
Herb Quine:
Speaking of Werner Herzog, name at least one film missing in his filmography and
how to fix this grave mistake with the help of a voucher for 53 free time
machines minutes to be used for a single travel to a time before October 1995.
Herb Quine:
Easy, the film in question would be the missing biopic of Mike Tyson focusing on
his time as a scholar of Medieval Media Studies in the field of Carolingian
Reality TV, played by Bruno Schleinstein and filmed entirely in Yiddish. How to
use the time machine should be obvious enough.
Herb Quine:
More seriously now, why a pet hamster?
Herb Quine:
Pet hamsters are the closest thing to miniature grizzly bears, a fact which is
of course entirely unrelated to their remarkable characteristics as party
animals (the hamsters, not the bears, though they might qualify, too…). The
purpose of the hamster at Ted’s party is thus twofold: In the unlikely event
that a discussion of Xanadu’s future turns into an attempt to establish the
Seasteading Republic Of Hypertext, someone needs to keep the engines chugging
along. And secondly, you need a fluent German speaker to reminisce about Wagner
with Werner (coincidentally also the title of the longest running radio show in
Nigeria’s Yiddish enclave).
Herb Quine:
You walk down to the shore to buy a new edition of “Learning Perl”, as you do
every Thursday. But when you reach the ice cube factory, you suddenly realize
that Unicode is pointless. Sure, you can play quite a few nice little language
games with all these emojis they keep adding, but the burrow only goes so far.
And then you hit the parking lot of the Consortium’s reserved committee parking
spaces and tumble head first onto the seat of a convertible. Which makes sense,
I guess, until you realize that the wonderful weather of the bay area is no
bueno for rhizomes and others of their ilk. They need constant watering, don’t
they?
Herb Quine:
Sorry, was there a question?
Herb Quine:
Yeah, all right, enough with the rambling. Let’s get down to business. What’s
your affiliation with the FBI and are you or have you ever been an agent engaged
in any work of endeavor related to printables, convertibles, mazes or any
combination thereof?
Herb Quine:
I can neither confirm nor deny the existence of the information sought. Also,
classical logic is overrated and all these lying Cretan hipsters are not nearly
as interesting as they think. If you ask me, and you just did, they are just
lazy bums who came up with this lying-business as an excuse to get out of the
real work of building tremendously beautiful walls like real Cretans do. These
kids nowadays, let me tell you…
Herb Quine:
Dat / Hypercore / Beaker sure look very interesting, but aren’t they a technical
solution to a problem of the medium? One great aspect of Fraidycat is that it
doesn’t care how established or indie your chosen medium is, in a way it feels
as if Fraidycat is rerouting and connecting existing media to extend and create
new media. It doesn’t care if you’re Kylie Jenner or Ted Nelson, it doesn’t
(much) care about the underlying technology, because it changes the topology of
the existing pieces while not denying that centralized sub-parts of the network
still exist. Is a more foundational project like Dat / Hypercore / Beaker
orthogonal to that idea?
Herb Quine:
I know I’m mostly answering rhetorical questions at this point, but this is one
that I’m really not sure how to answer. I do love the spirit of Dat / Hypercore
/ Beaker, I am just a bit suspicious of any attempts to revive the good parts of
the personal web without paying attention to why it became less important as a
medium (the non-app-web, that is), because I would be hesitant to point to
technical reasons. To me, IPFS and SSB in particular often look like solutions
that fix all the underlying tech in a very admirable way, without really
changing the medium that they are producing or favoring. A decentralized
Facebook will still result in a medium very much like Facebook, just at a
disadvantage because the technical forces can never be fully aligned with the
forces of the medium. I do think that Dat / Hypercore / Beaker are not as
susceptible in this regard and I really hope that they do not end up emulating
existing media too much. But really, I don’t know, what do you think?
Herb Quine:
Is the treasure hunt over? What are we supposed to do now? Wait for National
Treasure III? IS THIS REALLY IT? What about CGI Youngface and all the hard shell
kayaks that are still lying around in undiscovered places on the globe? What
about annie dark?
Herb Quine:
Yeah, I don’t think I’m equipped to answer this one. But damn, it was an amazing
ride so far.



 SLIME.DOC
SLIME.DOC
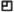












































 Ok - didn’t spot that. Thanks, krisu!
Ok - didn’t spot that. Thanks, krisu!











































")

 (⚬⃔⚬ℕ⚬⃔⚬)☁️")























")
















")













































−☆")

































 But really - this is just the
same thing I am always posting - very slapshod, goofy and overlooked little
bits of whatever.
But really - this is just the
same thing I am always posting - very slapshod, goofy and overlooked little
bits of whatever.






krisu
They have actual RSS feed, you don’t need “email to RSS”: https://webcurios.co.uk/feed/