#code
I use three main tags on this blog:
-
hypertext: linking, the Web, the future of it all.
-
garage: art and creation, tinkering, zines and books, kind of a junk drawer - sorry!
-
elementary: schooling for young kids.


#code
I use three main tags on this blog:
hypertext: linking, the Web, the future of it all.
garage: art and creation, tinkering, zines and books, kind of a junk drawer - sorry!
elementary: schooling for young kids.

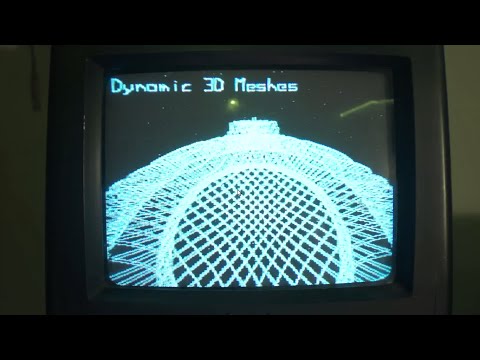
Sick bar code and TV licks from @crab_feet
Wow, am I late to this party. Ei Wada has been making music since at least 1998, much of it on TV tubes and magnetic tape. And still posting mind-blowing bar code freeform on Twitter at @crab_feet in the now. (Like this one - wait till you see what the shirts are for…)
The handle comes from an early piece called ‘Crab Feet Man’. Some of my fave vids I’ve run across:
I love Ei Wada’s infectious and playful way. Please post any other sweet vids you find - searching ‘electronicos fantasticos’ and ‘open reel ensemble’ can reveal others.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Create a single page of text with a certain brutalist aesthetic, an alternative to pastebins.
I stumbled upon this tool by Jonas Pelzer, after encountering the Planet Ujou website. This is exactly the kind of writing tool that I like to collect in href.cool’s Web/Participate category. A simple way to create HTML that you can then slap up to Neocities or 1mb.site.
I think it’s really cool that this is such a small, limited (but focused) tool - it can be polished to near perfection because it is so narrow in its function. I wish there were more little websites like this. It makes me wonder if a directory-building or link list tool could be made along these lines. Or perhaps there already is one! Now - how to find it…
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Brony AI seizes cartoon vocal chords (via @gwern)
The Pony Preservation Project undertakes to model (with machine learning) the voices of the My Little Pony: Friendship is Magic characters, thus granting them immortality. And, for Twilight Sparkle, the decorum of a sailor.
I don’t know if linking to 4chan is considered bad form - Gwern did the footwork on this, though, so who am I to say? Audio deepfakes, but for cartoon ponies. I’m just going to yank the text from 4chan, since I never know when these pages will disappear.
Pay particular notice to the Google Doc below - it contains rough instructions for training. You need a transcript for each audio clip that you’re processing, so a long-running series like Friendship is Magic is helpful, as you have a wide-ranging corpus to begin with. Background noise also needs to be removed from clips, there is a ‘sorting’ process - which also involves assigning ‘moods’ it seems - and there is also some reference to using Praat, which is used to annotate the files, identifying specific sounds.[1]
TwAIlight welcomes you to the Pony Voice Preservation Project!
https://clyp.it/qrnafm4yThis project is the first part of the “Pony Preservation Project” dealing with the voice. It’s dedicated to save our beloved pony’s voices by creating a neural network based Text To Speech for our favorite ponies. Videos such as “Steamed Hams But It’s Trump & Obama” or “RealTalk Joe Rogan” have proven that we now have the technology to generate convincing voices using machine learning algorithms “trained” on nothing but clean audio clips. With roughly 10 seasons (8 soon to be 9 seasons and 5 movies) worth of voice lines available, we have more than enough material to apply this tech for our deviant needs.
Any anon is free to join, and many are already contributing. Just read the guide to learn how you can help bring on the wAIfu revolution. Whatever your technical level, you can help. Document: docs.google.com
We now have a working TwAIlight that any Anon can play with: Instructions
>Active Tasks
Create a dataset for speech synthesis (https://youtu.be/KmpXyBbOObM)
Test some AI program with the current dataset
Research AI (read papers and find open source projects)
Track down remaining English/Foreign dubs that are missing
Evaluate cleaned audio samples
Phonetic dictionary/tagging
AI Training/Interface>Latest Developments
https://clyp.it/xp4q1bru [Yay!]
Anons are investigating Deepvoice3, Tacotron2 with GSTs, SV2TTS, and Mellotron
New tool to test audio clips
New “special source” audio
Several new AInons>Voice samples (So far)
https://clyp.it/2pb4bp05
https://clyp.it/s0klxftk
https://clyp.it/samzm4sk
https://pastebin.com/JUpDRsiw>Clipper Anon’s Master File:
https://mega.nz/#F!L952DI4Q!nibaVrvxbwgCgXMlPHVnVw>Synthbot’s Torrent Resources
In the doc at end of resources.
Gwern also found a larger directory of clips, same voice.
Predictions:
I’m still not too hyped by machine learning, though. It seems pretty weak given the empire frothing around it. But these small iterations are cool. And you have to love when it comes out of a random subculture rather than the military. Who can’t respect this kind of insanely determined fandom? Impressive work for one week.
A good start on this is “Analyze Your Voice” video by Prof Merryman. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
(Draft.)
I don’t know if I can explain this quite right - but I’m feeling as if “omniscience” has an indexing problem - and that is the source of quite a bit of amusement. It’s also somewhat tied in with our memories.
This thought occured when we were out of cheese at my place - and someone said, “I wish we could call up how many blocks of cheese we’ve used.” And we all guessed at what the number would be.
But if you think about a computer passively monitoring you 24/7 - XKeyscore, for instance - I can’t help but wonder how it could productively sense each new cheese entering the house (via grocery shopping) and leaving (via shitting).
Omniscience comes up quite regularly. People speak of “their life flashing before their eyes” when they die - or the ability to rewind and call up memories in some post-death review. But there are also characters such as “Janet” from The Good Place or the precogs from Minority Report, who are aware of everything and can be queried like a database. The concept of “The Singularity” often is meant to refer to a superintellegence that approaches omniscience.
So, could I ask an omniscient source: “Bring up all my conversations where Nicholas Cage is mentioned?” Given that sometimes I may be referring to National Treasure or other times I may be mentioning “Nouveau Shamanic” acting with him in mind. The index needs to include references to my conversation history, my context for understanding Nicholas Cage, and a many-to-many join between them.
To what degree does that query return every conversation I have? Am I constantly alluding to Nicholas Cage?
If humans have difficulty agreeing on an exact weight for a racist tweet or extracting the true meaning of any given pull-quote from the Mueller Report, how does an omniscient source ultimately mine all possible meanings from a given conversation? Couldn’t it become stuck on one sentence, infinitely paralyzed during indexing?
It seems an insurmountable problem that an omniscience could track everything as time continues. This makes me wonder if the inate desire of an omniscience would be to slow or stop time, rather than to accelerate it out of some voracious appetite.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Slaptrash Editor. This is a little project I’m messing with at the moment. It’s a simple way of creating video + audio + text mashups that you can embed in a webpage. Don’t worry if you feel that this thing is flippant and pointless—I’m well aware of that.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Building three-dimensional voxel-type pottery and maps with Python.
Need to investigate this further for my students—a language for writing LEGO-building algorithms, perhaps inspired by LOGO. There is a real need for more modern tiny languages (and One-Line Languages) that give children a taste of novel, playful creation. (Not the impractical abominations that code.org and such have given us.)
Seems like a dozen fascinating project could spring from this one. Are there similar projects that produce Paint 3D-style output?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
It’s more common to converse with a computer than to just dictate our instructions to it.
I’ve been helping a friend with a Discord bot, which has opened my eyes to the explosion of chatbots in recent years. Yes, there are the really lame chatbots, usually AI-driven—I searched for “lame chatbots” and was guided to chatbot.fail, but there’s also the spoof ‘Erwin’s Grumpy Cat’ on eeerik.com.

We’ve also quietly seen widespread use of sweet IRC-style bots, such as Slack or Twitch or Discord bots. These act like incredibly niche search engines, in a way. My friend’s own bot is for a game—looking up stats, storing screenshots, sifting through game logs and such.
So, yeah, we are using a lot of ‘one-line languages’—you can use words like ‘queries’ or ‘commands’ or whatever—but search terms aren’t really a command and something called a ‘query’ can be much more than a single line—think of ‘advanced search’ pages that provide all kinds of buttons and boxes.
Almost everything has a one-line language of some kind:
Humans push the limits of these simple tools—think of hashtags, which added categorical querying to otherwise bland search engines. Or @-mentions, which allow user queries on top of that. (Similar to early-Web words, such as ‘warez’ and ‘pr0n’ that allowed queries to circumvent filtering for a time.)
It’s very interesting to me that misspellings and symbolic characters became a source of innovation in the limited world of one-liners. (Perhaps similar to micro.blog’s use of tagmoji.)
It seems that these ‘languages’ are designed to approach the material—the text, the tags, the animated GIFs—in the most succinct way.
I wonder, though, if ‘search’ is the most impotent form of the one-liner. It’s clearly the most accessible on the surface: it has no ‘commands’, you just run a few searches and figure out which ‘commands’ work until they succeed. (If they do?)
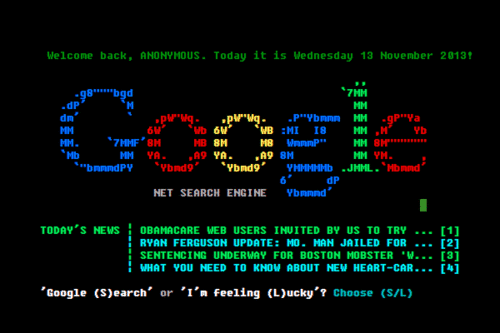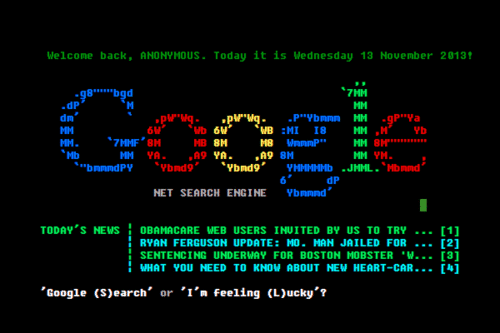
It also seems relevant that less than 1% of Google traffic uses the I’m Feeling Lucky button. Is this an indication that people are happy to have the raw data? Is it mistrust? Is this just a desire to just have more? Well, yeah, that’s for sure. We seem to make the trade of options over time.[1]
Observations:
Some sites—such as yubnub and goosh—play with this, as do most browsers, which let you add various shortcut prefixes.
Oh, one other MAJOR point about chatbots—there is definitely something performative about using a chatbot. Using a Discord chatbot is a helluva lot more fun than using Google. And part of it is that people are often doing it together—idly pulling up conversation pieces and surprising bot responses.
Part of the lameness of chatbots isn’t just the AI. I think it’s also being alone with the bot. It feels pointless.
I think that’s why we tend to anthropomorphize the ‘one-line language’ once we’re using it as a group—it is a medium between us at that point and I think we want to identify it as another being in the group. (Even in chats, like Minecraft, where responses don’t come from a particular name—the voice of the response has an omniscience and a memory.)
It’s also amusing that Google keeps the button—despite the fact that it apparently loses them money. Another related footnote: the variations on I’m Feeling Lucky that Google has had in the past. Almost like a directory attached to a search. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A prototype for the time being.
I’m sorry to be very ‘projecty’ today—I will get back to linking and surfing straightway. But, first, I need to share a prototype that I’ve been working on.
Our friend h0p3[1] has now filled his personal, public TiddlyWiki to the brim—a whopping 21 MEGAbyte file full of, oh, words. Phrases. Dark-triadic memetic, for instance. And I’m not eager for him to abandon this wiki to another system—and I’m not sure he can.
So, I’ve fashioned a doorway.
This is not a permanent mirror yet. Please don’t link to it.

Yes, there is also an archive page. I took these from his Github repo, which appears to go all the way back to the beginning.
Ok, yes, so it does have one other feature: it works with the browser cache. This means that if you load snapshot #623 and then load #624, it will not reload the entire wiki all over again—just the changes. This is because they are both based on the same snapshot (which is #618, to be precise.) So—if you are reading over the course of a month, you should only load the snapshot once.
Snapshots are taken once the changes go beyond 2 MB—though this can be tuned, of course.
Shrunk to 11% of its original size. This is done through the use of judicious diffs (or deltas). The code is in my TiddlyWiki-loader repository.
I picked up this project last week and kind of got sucked into it. I tried a number of approaches—both in snapshotting the thing and in loading the HTML.
I ended up with an IFRAME in the end. It was just so much faster to push a 21 MB string through IFRAME’s srcdoc property than to use stuff like innerHTML or parseHTML or all the other strategies.
Also: document.write (and document.open and document.close) seems immensely slow and unreliable. Perhaps I was doing it wrong? (You can look through the commit log on Github to find my old work.)
I originally thought I’d settled on splitting the wiki up into ~200 pieces that would be updated with changes each time the wiki gets synchronized. I got a fair bit into the algorithm here (and, again, this can be seen in the commit log—the kicksplit.py script.)
But two-hundred chunks of 21 MB is still 10k per chunk. And usually a single day of edits would result in twenty chunks being updated. This meant a single snapshot would be two megs. In a few days, we’re up to eight megs.
Once I went back to diffs and saw that a single day usually only comprised 20-50k of changes (and that this stayed consistent over the entire life of h0p3’s wiki,) I was convinced. The use of diffs also made it very simple to add an archives page.
In addition, this will help with TiddlyWikis that are shared on the Dat network[2]. Right now, if you have a Dat with a TiddlyWiki in it, it will grow in size just like the 6 gig folder I talked about in the last box. If you use this script, you can be down to a reasonable size. (I also believe I can get this to work directly from TiddlyWiki from inside of Beaker.)
And, so, yeah, here is a dat link you can enjoy: dat://38c211…a3/
I think that’s all that I’ll discuss here, for further technical details (and how to actually use it), see the README. I just want to offer help to my friends out there that are doing this kind of work and encourage anyone else who might be worried that hosting a public TiddlyWiki might drain too much bandwidth.
philosopher.life, dontchakno? I’m not going to type it in for ya. ↩︎
The network used by the Beaker Browser, which is one of my tultywits. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
My personal strategy for handling HTML on the distributed Web.
So, HTML is a bit different on the distributed Web (the Dat network which the Beaker Browser uses, IPFS and so on) because your file history sticks around there. Normally on the Web, you upload your new website and it replaces the old one. With all of these other ‘webs’, it’s not that way—you add your new changes on top of the old site.
Things tend to pile up. You’re filing these networks with files. So, with a blog, for instance, there are these concerns:
Ultimately, I might end up delivering a pure JavaScript site on the Dat network. It seems very efficient to do that actually—this site weighs in at 19 MB normally, but a pure JavaScript version should be around 7 MB (with 5 MB of that being images.)
My interim solution is to mimick HTML includes. My tags look like this:
<link rel="include" href="/includes/header.html">
The code to load these is this:
document.addEventListener('DOMContentLoaded', function() {
let eles = document.querySelectorAll("link[rel='include']");
for (let i = 0; i < eles.length; i++) {
let ele = eles[i];
let xhr = new XMLHttpRequest()
xhr.onload = function() {
let frag = document.createRange().
createContextualFragment(this.responseText)
let seq = function () {
while (frag.children.length > 0) {
let c = frag.children[0]
if (c.tagName == "SCRIPT" && c.src) {
c.onload = seq
c.onerror = seq
}
ele.parentNode.insertBefore(c, ele);
if (c.onload == seq) {
break
}
}
}
seq()
}
xhr.open('GET', ele.href);
xhr.send();
}
})
You can put this anywhere on the page you want—in the <head> tags, in a
script that gets loaded. It will also load any scripts inside the HTML fragment
that gets loaded.
This change saved me 4 MB immediately. But, in the long run, the savings are much greater because my whole site doesn’t rebuild when I add a single tag (which shows up in the ‘archives’ box on the left-hand side of this site.)
I would have used ‘HTML imports’—but they aren’t supported by Firefox and are a bit weird for this (because they don’t actally put the HTML inside into the page.)
I am happy to anyone for improvements that can be made to this.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The whole Truttle1 channel is full of videos about esoteric programming languages—but I also find its homemade computer animations to be terribly charming. There seem to be just a few productive kids behind these videos.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I ran across this site while out link hunting. Since I’m not planning to include software-related links in my directory—since business and software already have many directories—I will post it here. There is a discussion of this site on a blog called esoteric.codes, which has been a second fascinating discovery!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Continuing my discussion from Foundations of a Tiny Directory, I discuss the recent trend in ‘awesome’ directories.
All this recent discussion about link directories and one of the biggest innovations was sitting under my nose! The awesome-style directory, which I was reminded of by the Dat Project’s Awesome list.
An “awesome” list is—well, it isn’t described very well on the about page, which simply says: only awesome is awesome. I think the description here is a bit better:
Curated lists of awesome links around a specific topic.
The “awesome” part to me: these independently-managed directories are then brought together into a single, larger directory. Both at the master repo and at stylized versions of the master repo, such as AwesomeSearch.
In a way, there’s nothing more to say. You create a list of links. Make sure they are all awesome. Organize them under subtopics. And, for extra credit, write a sentence about each one.

Generally, awesome lists are hosted on Github. They are plain Markdown READMEs.
They use h2 and h3 headers for topics; ul tags for the link lists. They are
unstyled, reminiscent of a wiki.
This plain presentation is possibly to its benefit—you don’t stare at the directory, you move through it. It’s a conduit, designed to take you to the awesome things.
Awesome lists do not use tags; they are hierarchical. But they never nest too deeply. (Take the Testing Frameworks section under the JavaScript awesome list—it has a second level with topics like Frameworks annd Coverage.)
Sometimes the actual ul list of links will go down three or four levels.
But they’ve solved one of the major problems with hierarchical directories: needing to click too much to get down through the levels. The entire list is displayed on a single page. This is great.
The emphasis on “awesome” implies that this is not just a complete directory of the world’s links—just a list of those the editor finds value in. It also means that, in defense of each link, there’s usually a bit of explanatory text for that link. I think this is great too!!
The reason why most awesome lists use Github is because it allows people to submit links to the directory without having direct access to modify it. To submit, you make a copy of the directory, make your changes, then send back a pull request. The JavaScript awesome list has received 477 pull requests, with 224 approved for inclusion.
So this is starting to seem like a rebirth of the old “expert” pages (on sites like About.com). Except that there is no photo or bio of the expert.

As I’ve been browsing these lists, I’m starting to see that there is a wide variety of quality. In fact, one of the worst lists is the master list!! (It’s also the most difficult list to curate.)
I also think the lack of styling can be a detriment to these lists. Compare the Static Web Site awesome list with staticgen.com. The awesome list is definitely easier to scan. But the rich metadata gathered by the StaticGen site can be very helpful! Not the Twitter follower count—that is pointless. But it is interesting to see the popularity, because that can be very helpful sign of the community’s robustness around that software.
Anyway, I’m interested to see how these sites survive linkrot. I have a feeling we’re going to be left with a whole lot of broken awesome lists. But they’ve been very successful in bringing back small, niche directories. So perhaps we can expect some further innovations.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Mostly I’m posting this to test emoji in posts to Indieweb.xyz. But I also am interested in using hyperdb (or perhaps just discovery-swarm) to further decentralize the previously mentioned Indieweb.xyz.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
It seems that Indieweb is made of these loosely connected pieces that follow as much of the protocol as they individually want to. While this is supposed to make it approachable—I mean you don’t need to adopt any of it to participate—it can be tough to know how much of it you’re obeying. (The whole thing actually reminds me a lot of HTML itself: elaborate, idealistic, but hellbent on leaving all that behind in order to be practical.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Built in three days. The /en/show-xyz sub auto-crossposts when you prefix your title with the phrase above.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Peter Stuifzand passed on this pic in #indieweb-dev on Freenode. Thanks for all the help today!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok — doing some blog modding. Let’s get in on this Indieweb, eh? Yeah, get in. Ping.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Always looking for simple programs to take apart. And Glitch is fantastic. Source code here.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Great idea—using the ESP8266 to hook NTP up to your table clock. I know they sell these, but this is still a great learning project. Would love to see this in Lua or JS for NodeMCU.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Geez I was really hoping the ending would reveal that they were all dead the whole time. Now we’re going to need to band together, in order to resist this intoxicating urge to deify F.A.T.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
First time I’ve seen something like this — a simplified Arduino project to simulate the 302 neurons of a certain worm’s brain. Also led me to the Open Connectome Project — can you imagine loading a ROM of a mouse brain onto a device?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A neural net/A.I. kind of thing writes a Christmas song. I think I like the pop song even better. “I’d seen the men in his life, who guided me at the beach once more.” The vibe reminds me of a sterile, eyes-don’t-close version of The Shaggs.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The brick phone brought into this century! While the hardware design is definitely impressive, the software looks good, too. To come up with a nice UI for a 96x64 pixel screen is something of an accomplishment.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
An incredibly thorough review of JSON specifications and parsers. Fantastic criticism of the RFC, but beyond that: the benchmarking and concise bug hunting here is something every parser project should count themselves lucky to have.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

The thing—the key—the realization that’s needed before you can write shaders. Really, I think this will help.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Oh man this hack is a thrill. This guy does great stuff! Check out the VHF on an ATtiny85, too.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Another one of those vids from the console hackers that inspires true joy — an SNES hacked to bring us Super Mario Maker. Watch what happens when the reins are handed over to Twitch chat.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Complete code and build instructions for a glowing pear-shaped night light. The discovery of this cheap, translucent enclosure is a boon. I am definitely going to build this project with the fourth- and fifth-graders.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

While trying to get JoyLabz Makey Makey 1.2 to work with an iPad, I discovered there is no way to reprogram it.
It seems like this information hasn’t been disclosed quite enough as it should: Makey Makey’s version 1.2, produced by JoyLabz, cannot be reprogrammed with the Arduino software. In previous versions, you could customize the firmware — remap the keys, access the AVR chip directly — using an Arduino sketch.
🙌 NOTE: Dedokta on Reddit demonstrates how to make a Makey Makey.
Now, this isn’t necessarily bad: version 1.2 has a very nice way to remap the keys. This page here. You use alligator clips to connect the up and down arrows of the Makey Makey, as well as the left and right arrows, then plug it into the USB port. The remapping page then communicates with the Makey Makey through keyboard events. (See Communication.js.)
This is all very neat, but it might be nice to see warnings on firmware projects like this one that they only support pre-1.2 versions of the Makey Makey. (I realize the page refers to “Sparkfun’s version” but it might not be clear that there are two Makey Makeys floating about—it wasn’t to me.)
⛺ UPDATE: The text on the chip of the version 1.2 appears to read: PIC18F25K50. That would be this.
Now, how I came upon this problem was while experimenting with connecting the Makey Makey to an iPad. Instructions for doing this with the pre-1.2 Makey Makey are here in the forums—by one of the creators of the MM.
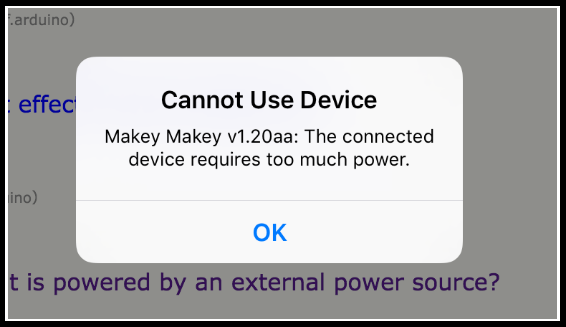
With the 1.2 version, it appears that the power draw is too great. I received this message with both an iPad Air and an original iPad Mini.
Obviously a Makey Makey isn’t quite as interesting with an iPad — but I was messing with potentially communicating through a custom app.
Anyway, without being able to recompile the firmware, the iPad seems no longer an option. (The forum post should note this as well, no?)
If you do end up trying to get a pre-1.2 Makey Makey working with the latest Arduino, I ran into many problems just getting the settings right. The github repos for the various Makey Makey firmwares are quite dated.
One of the first problems is getting boards.txt to find my avr compiler. I had this problem both on Linux and Windows. Here’s my boards.txt that finally clicked for me:
############################################################################
menu.cpu=Processor
############################################################################
################################ Makey Makey ###############################
############################################################################
makeymakey.name=SparkFun Makey Makey
makeymakey.build.board=AVR_MAKEYMAKEY
makeymakey.build.vid.0=0x1B4F
makeymakey.build.pid.0=0x2B74
makeymakey.build.vid.1=0x1B4F
makeymakey.build.pid.1=0x2B75
makeymakey.upload.tool=avrdude
makeymakey.upload.protocol=avr109
makeymakey.upload.maximum_size=28672
makeymakey.upload.speed=57600
makeymakey.upload.disable_flushing=true
makeymakey.upload.use_1200bps_touch=true
makeymakey.upload.wait_for_upload_port=true
makeymakey.bootloader.low_fuses=0xFF
makeymakey.bootloader.high_fuses=0xD8
makeymakey.bootloader.extended_fuses=0xF8
makeymakey.bootloader.file=caterina/Caterina-makeymakey.hex
makeymakey.bootloader.unlock_bits=0x3F
makeymakey.bootloader.lock_bits=0x2F
makeymakey.bootloader.tool=avrdude
makeymakey.build.mcu=atmega32u4
makeymakey.build.f_cpu=16000000L
makeymakey.build.vid=0x1B4F
makeymakey.build.pid=0x2B75
makeymakey.build.usb_product="SparkFun Makey Makey"
makeymakey.build.core=arduino
makeymakey.build.variant=MaKeyMaKey
makeymakey.build.extra_flags={build.usb_flags}
I also ended up copying the main Arduino platform.txt straight over.
Debugging this was difficult: arduino-builder was crashing (“panic: invalid memory address”) in create_build_options_map.go. This turned out to be a misspelled “arudino” in boards.txt. I later got null pointer exceptions coming from SerialUploader.java:78 — this was also due to using “arduino:avrdude” instead of just “avrdude” in platforms.txt.
I really need to start taking a look at using Ino to work with sketches instead of the Arduino software.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

Sometimes your PWM pin is tied up doing SPI. You can still salvage the PWM timer itself, though.
Right now the spotlight is stolen by lovely chips like the ESP8266 and the BCM2835 (the chip powering the new Raspberry Pi Zero). However, personally, I still find myself spending a lot of time with the ATtiny44a. With 14 pins, it’s not as restrictive as the ATtiny85. Yet it’s still just a sliver of a chip. (And I confess to being a sucker for its numbering.)
My current project involves an RF circuit (the nRF24l01+) and an RGB LED. But the LED needed some of the same pins that the RF module needs. Can I use this chip?
The LED is controlled using PWM — pulse-width modulation — a technique for creating an analog signal from code. PWM creates a wave — a rise and a fall.
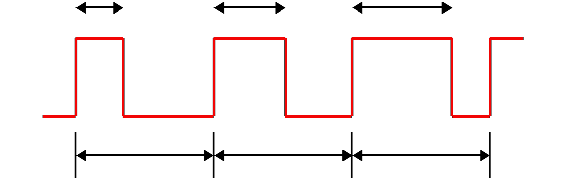
This involves a hardware timer — you toggle a few settings in the chip and it begins counting. When the timer crosses a certain threshold, it can cut the voltage. Change the threshold (the OCR) and you change the length of the wave. So, basically, if I set the OCR longer, I can get a higher voltage. If I set a lower OCR, I get a lower voltage.
I can have the PWM send voltage to the green pin on my RGB LED. And that pin can be either up at 3V (from the two AA batteries powering the ATtiny44a) or it can be down at zero — or PWM can do about anything in between.
My problem, though, was that the SPI pins — which I use to communicate with the RF chip — overlap my second set of PWM pins.
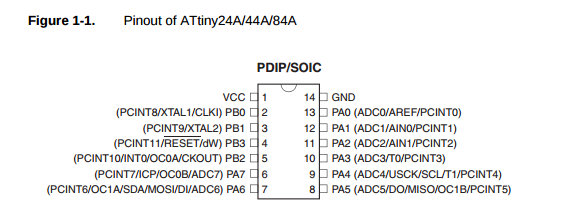
You see — pin 7 has multiple roles. It can be OC1A and it can also be DI. I’m already using its DI mode to communicate with the RF module. The OC1B pin is similarly tied up acting as DO.
I’m already using OC0A and OC0B for my green and blue pins. These pins correspond to TIMER0 — the 8-bit timer used to control those two PWM channels on OC0A and OC0B. To get this timer working, I followed a few steps:
// LED pins
#define RED_PIN PA0
#define GREEN_PIN PB2
#define BLUE_PIN PA7
Okay, here are the three pins I want to use. PB2 and PA7 are the TIMER0 pins I was just talking about. I’m going to use another one of the free pins (PA0) for the red pin if I can.
DDRA |= (1<<RED_PIN) | (1<<BLUE_PIN);
DDRB |= (1<<GREEN_PIN);
Obviously I need these pins to be outputs — they are going to be sending out this PWM wave. This code informs the Data Direction Register (DDR) that these pins are outputs. DDRA for PA0 and PA7. DDRB for PB2.
// Configure timer0 for fast PWM on PB2 and PA7.
TCCR0A = 3<<COM0A0 | 3<<COM0B0 // set on compare match, clear at BOTTOM
| 3<<WGM00; // mode 3: TOP is 0xFF, update at BOTTOM, overflow at MAX
TCCR0B = 0<<WGM02 | 3<<CS00; // Prescaler 0 /64
Alright. Yeah, so these are TIMER0’s PWM settings. We’re turning on mode 3 (fast PWM) and setting the frequency (the line about the prescaler.) I’m not going to go into any detail here. Suffice to say: it’s on.
// Set the green pin to 30% or so.
OCR0A = 0x1F;
// Set the blue pin to almost the max.
OCR0B = 0xFC;
And now I can just use OCR0A and OCR0B to the analog levels I need.
Most of these AVR chips have multiple timers and the ATtiny44a is no different — TIMER1 is a 16-bit timer with hardware PWM. Somehow I need to use this second timer to power th PWM on my red pin.
I could use software to kind of emulate what the hardware PWM does. Like using delays or something like that. The Make: AVR Programming book mentions using a timer’s interrupt to handcraft a hardware-based PWM.
This is problematic with a 16-bit timer, though. An 8-bit timer maxes out at 255. But a 16-bit timer maxes out at 65535. So it’ll take too long for the timer to overflow. I could lower the prescaler, but — I tried that, it’s still too slow.
Then I stumbled on mode 5. An 8-bit PWM for the 16-bit timer. What I can do is to run the 8-bit PWM on TIMER1 and not hook it up to the actual pin.
// Setup timer1 for handmade PWM on PA0.
TCCR1A = 1<<WGM10; // Fast PWM mode (8-bit)
// TOP is 0xFF, update at TOP, overflow at TOP
TCCR1B = 1<<WGM12 // + hi bits
| 3<<CS10; // Prescaler /64
Okay, now we have a second PWM that runs at the same speed as our first PWM.
What we’re going to do now is to hijaak the interrupts from TIMER1.
TIMSK1 |= 1<<OCIE1A | 1<<TOIE1;
Good, good. OCIE1A gives us an interrupt that will go off when we hit our threshold — same as OCR0A and OCR0B from earlier.
And TOIE1 supplies an interrupt for when the thing overflows — when it hits 255.
Now we manually change the voltage on the red pin.
ISR(TIM1_COMPA_vect) {
sbi(PORTA, RED_PIN);
}
ISR(TIM1_OVF_vect) {
cbi(PORTA, RED_PIN);
}
And we control red. It’s not going to be as fast as pure PWM, but it’s not a software PWM either.
I probably would have been better off to use the ATtiny2313 (which has PWM channels on separate pins from the SPI used by the RF) but I needed to lower cost as much as possible — 60¢ for the ATtiny44a was just right. This is a project funded by a small afterschool club stipend. I am trying to come up with some alternatives to the Makey Makey — which the kids enjoyed at first, but which alienated at least half of them by the end. So we’re going to play with radio frequencies instead.
I imagine there are better other solutions — probably even for this same chip — but I’m happy with the discovery that the PWM’s interrupts can be messed with. Moving away from Arduino’s analogWrite and toward manipulating registers directly is very freeing — in that I can exploit the chip’s full potential. It does come with the trade off that my code won’t run on another chip without a bunch of renaming — and perhaps rethinking everything.
Whatever the case, understanding the chip’s internals can only help out in the long run.
If you’d like to see the code in its full context, take a look through the Blippydot project.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.








{kind=link}