19 Oct 2018
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.


This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

It’s constant work—finding each other through the noise.
Hi, folks - just jumping in because this is my wheel house a bit. I have been having an extended discussion with Brad Enslen (so, on our blogs: ramblinggit.com and kickscondor.com) about discovery. We talk a lot about how this is more of a human problem than a technology problem - and that technology has played a negative role in this, perhaps.
(My part in this is: I have been spending time every day for the past six months searching for blogs - to see what the Web looks like outside of social networks. So I have a good perspective on where one can search nowadays - you can’t just type ‘blogs’ into Google. And I’m starting to get a good feel for where I would want to go to find blogs.)
blogrolls didn’t scale. ring blogs just sucked. SEO is just survival-of-the-fittest money pit.
Yes, so - for sure. (See Brad’s comment on Google here.)
In addition, self-promotion has become a dirtier word these days - you can’t just post your blog to Reddit and Instagram - it’s seen as being overly assertive. So there is almost nowhere for blogs to go.
The thing is: no, blogrolls didn’t scale - but I think they are pretty essential. We’ve traded a human-curated list of links for a ‘friends’ list that is really just a number on an individual’s feed. And the best blogrolls had nice descriptions of who was who (see: Chris Aldrich’s following page as a good example) which is a generous way of turning your readers on to other good work.
I guess I just think of it practically: how would we treat our friends and the other ‘writers’/‘artists’ we admire - by making them a number in our list? Or by spelling it out: “Annie writes about her processes as a sci-fi writer and how to improve online relationships. Basically - it’s uplifting to read her.”
Blog clusters are emergent. Fake or not, blogs with posts on similar topics will be mapped to same cluster which can be seen as a place in which a blog belongs to. Once we have that, a blog reader should be able to ‘pop out’ of that blog and see some visual representation of that cluster with neighboring blogs, not unlike a shopper leaving a store will see a street lined with other shops. That’s how discovery is done IRL and I envision that may be possible online.
Sweet - feels practical. One question I have here is: ok, so blogs have also become more topic-based. The most common blogs are recipe blogs, movie blogs, etc. But a great ‘lost’ element of blogs was just the original web journal or meta blog, where a person is just writing about whatever - I think of stuff like the old J-Walk blog or Bifurcated Rivets. Even Boing Boing used to be more this way. (So like an online ‘zine’.)
I think the orderliness of the Internet and the systems for discovery - these blogs were not found through Google, but only because there was more of an ethic of linking to each other among early blogs. A lot of discovery was just being done by bloggers back then - people simply passed links around.
Again, ‘likes’ have drained linking of a lot of its bite. We don’t write so much about why we like something - we like it and move on. And it’s so easy to ‘like’, it is done so vigorously that even we can’t keep up with our own likes - whereas we used to be limited by how much energy we would spend dressing up our links.
I’m with Don on this – whatever is going to have a chance to work has to be emergent, meaning it can’t require any investment on the part of writers.
I think ‘emergent’ can require work - in fact, it might demand work. Yes, too much work will dissuade anyone. But if it’s too easy, then it’s virtually worthless. I think the value of human curation is in its additional care.
An algorithm cannot simulate the care. Chris’ blogroll linked above is done with care - a human can plainly see that another human has taken the time to write about others. And the more time he spends designing it and improving it, the more it shows that care. People can visit my blog and see that it is built with care. (To me ‘care’ can be represented by thoughtful writing and splendid artistry or shaping of the information.)
Ok - sorry to go on so long, I hope you see this as my effort to generously engage in your discussion.
The effort Brad and I are now engaged in is an effort to bring back the link directory and to attempt to innovate it based on what we’ve learned. (Link directories have already evolved several times into: blogrolls, wikis, link blogs, even the App Store’s new ‘magazine’ approach, etc.) The idea is to jump right into discovery and link up with anyone else who wants to get in on it. Thus, my reply today!
Good to meet you all - take care.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A gateway to the Old Web and its sparkling, angelic imagery.
I try not to get too wrapped up in mere nostalgia here—I’m more interested in where the Web is going next than where it’s been. But, hell, then I fumble into a site like this one and I just get sucked up into the halcyon GIFs.
This site simply explores the full Geocities torrent, reviewing and screenshotting and digging up history. The archive gets tackled by the writers in thematic bites, such as sites that were last updated right after 9/11, tracking down construction cones, or denizens of the ‘Pentagon’ neighborhood.
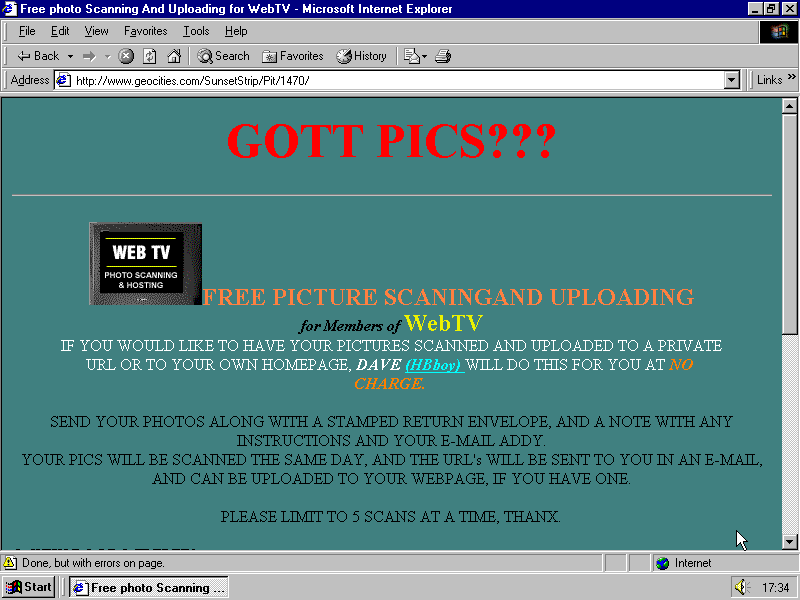
Their restoration of the Papercat is really cool. Click on it. Yeah, check that out. Now here’s something. Get your pics scanned and I’ll mail you back? Oh, krikey, Dave (HBboy). What a time to be alive.
But, beyond that, there is a network of other blogs and sites connected to this one:

oocities.com/username.I was also happy to discover that the majority (all?) of the posts are done by Olia Lialina, who is one of the original net.artists—I admire her other work greatly! Ok, cool.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
While Tumblr is a type of blog, I think it is sufficiently different to categorize differently—microblogging, tumblelogging. Simply because it generally eschews writing. And that appeals to people.
So, question for you: are you satisfied with a blog for your approach? It seems that you post links, essays and announcements generally. However, these three things are not equal. And to see your essays roll off the front page while links take their place—well, I can see myself wanting a directory of those.
Yes, you have an ‘article’ post type that shows me those essays. But even that list is not comprised of equals. I wonder if a wiki might suit these.
I also wonder if there is a new way to structure all of these thoughts that might do justice to what you are doing and assist the reader in navigating what you are doing. A way of mixing and matching the ‘blog’, the ‘wiki’ and the ‘directory’.
To me, the great failing of blogs is that it is difficult to find the beginning and the end—and I don’t think they facilitate the ‘memory’ of a discussion. A blog post is a thought balloon floating alone. You and I can follow it pretty well, because we are juggling some memories to do it—but someone who stumbles across this post will not realize what is really going on.
Anyway, this is a great post—I’ve been pretty stumped about how to preserve the wee ‘web page’ and this is a thread we’ll need to continue over time.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
My dump of blogs, portfolios and personal pages found on Reddit and a few design forums.
If I’ve left your blog or personal site out of my collection, GET A HOLD OF ME IMMEDIATELY. 😘 Let Me Link to You.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Hybrid ‘grid’/‘timeline’ as a directory
Ran across this interesting directory of a certain fellow’s life—seems like this kind of thing could be applied effectively to the personal wiki crowd (h0p3, sphygmus). Anyway, it’s a starting place for a discussion about the visuals that could go into a self-reflexive directory.
Also relevant here: this guy ran the Haddock Directory, which was a link directory by a London-based mailing list—‘a bunch of friends’. It ended up with 27,000 links.
This directory is probably the closest I’ve seen to what I aspire to do—not in its design, but in its effort to catalog the links and web explorations of a small informal group (as opposed to a corporate effort, software team effort.) Look past the design and the categories—the little sentence describing each link is done with care. It’s cool that they also shared book and music reviews on the site.
According to a blog post written about the shuttering of Haddock:
Back in 1997 no one on the list had a weblog — well, the term barely existed — but now plenty of us have them, and plenty of people post links to their own sites or del.icio.us so there’s still plenty of regular material from some of those on the list, should you feel the need for an idea of what people are thinking. Roughly.
The post is from 2007. I wonder where the list meets now. Or if they do.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Yeah, hey, great discussion! Thanks for pointing it out—missed it somehow.
On your points:
We, the little people, need to rebuild the web. […] This is the foundation of everything. Yes, cool—you see this at a football game when things get heated and two guys start fighting. Then another guy stands up and says, “I’ll fix this,” and he starts walking down. Oh boy. Sure.
So, like: not only is another social media site going to solve this, but no one of us is going to have an ‘answer’. TiddlyWiki doesn’t work for me—but h0p3 and sphygmus are doing great things for themselves—and I think there are many people who will be served well by it (as compared to micro.blog).
Someplace to go is actually many places built by us. Sweet! I get really excited at the prospect of more places to go.
Link freely. This has the added benefit of creating a TON of noise for Google. 😘 If the tradeoff on something is “bad for bots, good for humans,” I’ll take that trade.
Discovery, and search, will sort itself out, if we do #1,2, and 3. Trying to decide if I agree with this. I kind of agree with “it’ll all come out in the wash” but I also don’t think discovery gets better than Brad linking to Simon and me reading Simon.
Once I start relying on a bot, what else is it giving me? And do I begin to get lazy with my discovery effort? And then am I isolated again?
We may end up with 5, 6, 10 or more favorite places we go to search and that is good. More and more, I’m finding myself just using Stack Overflow, Pinboard and YouTube search directly. Google just does this anyway. I tend to use Google more as a glorified address bar: ‘indieweb.org author’ and click the first link. I know this will take me to Indieweb wiki’s page on authorship. (So there is a specific page I already know—basically a ‘feeling lucky’.)
Love being a part of this discussion. I am working hard on my directory to finish it—hopefully by end of October. (Again, it’s not a directory people can submit to: it’s my model for the modern Little Web Library. Just trying to get a good amount of links, categories, fun to use, all that.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I don’t think I connect with you and Brad quite as much on search—it’s one thing to search for ‘rotate div 90 degrees’ compared to searching for ‘aesthetically pleasing blog with poetry’. This is why I’m much more bullish on directories (blogrolls, wikis, that ilk)—if we can link to each other and describe each other to each other—that is another way to get somewhere.
Anyway, I’m not trying to convince you of my perspective, just saying that it’s cool: while you are looking for ‘useful’ and I am looking for ‘fascinating’—and in some ways I’m sure we’re both looking for both—we both want the same type of web. A well-lived-in one.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
(Strange that this didn’t show up in my ‘mentions’—wonder what else I am not replying to—)
Even aside from any larger societal impact, I can’t say that anything I have done on social media has been nearly as worthwhile. The past year, since about March, I’ve committed to spending less time on social media, and my creative output is way up.
I think this is so encouraging—maybe the most encouraging thing one can say! Can you point to what is causing this? Is it the feeling of working for yourself, rather than—as you say—giving ‘free labor’ to the CorpASAs?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, trying out an interview here—throwing some questions to the author of a beloved ‘zine’/‘operating system’.
I try to go out looking for links as much as possible.
(God’s sake, man—why?? Who needs more links, I can give you links—don’t toss yourself into the brambles—)
But I love to see the horrors and grotesques—to measure and inspect them. I aspire to be a grotesque and must be very studious about achieving it!
It all pays off when a link like whimsy.space comes a long.
kicks: Daniel, had a few questions about whimsy.space. (I really love glitch, too, of course—and hope it’s doing well, but the zine hits a nerve for me.) So, what ‘works’/‘zines’ inspired whimsy.space?
danielx: I was inspired by sites that have a lot of heart, things like the original Geocities. Also the feeling of personal computing from the mid 90s like win 3.1 and Win95. I’m also a fan of things like Dwarf Fortress and Bennett Foddy’s games.
Not necessarily that they are inaccessible for the sake of being inaccessible, but that if they were simpler they would be something different. Philosophically I’ve read and respect Alan Kay “The real computer revolution hasn’t happened yet” and Bret Victor.
kicks: Yeah, oh man, Foddy. I teach at an elementary school and a favorite activity I do is to play Foddy games with the kids hooked up to wires (Makey Makey-style) so that when they close the loop (by jumping on the floor or slapping hands, for instance) then CLOP hops around. It’s a credit to the simplicity of his design that we can do that.
What do you hope for it now? Was it just a momentary plaything—or is it an obsession?
danielx: It has been an on and off obsession. It depends on what else I’ve got going on in life and work outside of my own esoteric pursuits.
It’s definitely the hobby
that brings me the most joy when I get to dig into it and see where it goes.
Early on I decided that it would be for my own personal enjoyment and I wouldn’t
look for ways to “make it a success” or “turn it into a business”. I want to
keep my work and play separate you could say 
kicks: I like that it doesn’t explain itself. I didn’t even get that it was REALLY a zine the first time I visited. I still don’t really understand how the filesystem and social media inside of it works. And I can’t help but feel that its opacity is symbolic. It feels like a hidden trove - like a person is or maybe like an animal is. You probably don’t care about ease of use - how did you design it?
danielx: I’ve created a lot of different web applications and sites and things over the years. Some of them for fun and some as businesses. With whimsy.space my goal was to have it be a curated collection of all my works along with other things I find interesting. About eight years ago I built an online game development environment at pixieengine.com. Now it’s been simplified to a pixel editor and art community. Whimsy.space is the spiritual successor to that, I want many different applications that can interact and contribute to creating content. To recreate the part of personal computing where the operator of the computer could combine small components in interesting ways to get profound results.
I care some about ease of use, though it’s not been my top priority lately. Similar to Bennett Foddy’s games I want it to be as easy as it can be without losing its essence and becoming something else.
The design and implementation is a lot of custom code and some integrations of existing components. The site itself is serverless/static hosted on AWS with S3 and CloudFront. I use AWS Cognito for the My Briefcase authentication feature and each user can upload to their own S3 subfolder. The UI is all my custom js/css inspired by Win3.1/95. The code editor is Ace. The apps run in iframes and talk to the system over postMessage. I use CoffeeScript for most of the code.
The essence of the zine part came from my tendency to always go too deep on architecture and infrastructure, so by having a periodic release of content it would force me to prioritize only the features that aided the content and not be a system of pure mechanics with nothing to showcase it.
kicks: Jeepers, didn’t expect that. Is this a kind of backend that you would recommend to hobbyists? I’m used to static HTML and JS.
danielx: I wouldn’t recommend going deep into AWS or other Cloud services for hobbyists. Since I do software engineering for my employment I’ve gained a lot of experience on “industrial strength” solutions.
The challenge is finding the subset that actually solve more problems than they cause.
I often feel like I’m crawling around in Jeff Bezos’ spaceship trying to bring alien technology to the people.
kicks: Are handmade ‘blogs’/‘zines’/‘home pages’ dying? Would that be a bad thing - like: is there something else?
danielx: They’re dying in the sense that every living thing is in a constant cycle of death and rebirth. There are probably more handmade blogs and home pages today than ever before (in an absolute sense) but proportionally they make up a smaller part of the internet.
I would like to see more people sharing personal computing and smaller internet communities. Businesses exist to consume consumers, by getting our hands dirty and crafting using technology individuals can gain knowledge and understanding of how these systems work so we might not be so vulnerable to all these forces trying to devour us. The web is a modern marvel, not quite as complex as nature, but it has its own evolution and ecology. I enjoy the first hand experience of digging around in it to see what I can learn about systems as well as myself.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This is an impressive list! Not because these are very good directories—I struggled to find any new links that were of use—but a) because they are actually still there, b) the categorization systems that some of them use are different, c) some of the most interesting parts are not the actual directory (e.g. the editoral guidelines are useful—they’ve been in this game a lot longer.)
I wonder if any web portals still exist. It was such a fad and—while I never got into them—I wonder if the idea is still plunderable. I suppose the current Twitter/Facebook newsfeed is a progeny.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, I did this - this is great, there are some ‘neat’/‘inspiring’ things there. A few other questions for you:
How do I find more hashtags? I would have never found #creativecoding - is it known to be a community or is it just an ad hoc hashtag like #lostinthehashtags (which I just made up - but which has posts!) I guess what I’m saying is - I don’t sense that these hashtags are a community - or are they?
As ‘neat’/‘inspiring’ as these are, they are mostly only (very small) images and (very short) clips. I ultimately can’t see myself using Instagram or Twitter much because you just kind of skim and can’t go deeper. They lack the ‘hypertext’. (This is similarly to the OP’s trouble with this post just being a simple ‘box algorithm’ - where do I go for more?
Most of these look like art I’ve seen on t-shirts or album covers. Dating back even to the seventies. It is still beautiful and remarkable - but I can’t help but wonder: Where is innovation happening in tech+art?
I will say that I do follow a lot of things happening in vaporwave - any idea what else is happening out there? Thank you for your time, HammadB. I am eager.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A ‘steno’ format. A depleted word. A still personal word. A simulation. A read-write simulation. A truncated octahedron.
(This is the first of a new type of post on this blog—a “steno”. This format will house ‘thoughts’/‘discussions’/‘works’—much like an old-time c2-style or everything2-style wiki page that always ended up being an amazing catastrophe. The “steno” acts as hasty notes, links to other places around the blog, recurring nexus, link stations, breathers maybe, between the other articles and notes, revolving around a kind of ‘topic’/‘idea’.)
(In a way, I realize that starting off with an aside is a bad way to get anyone jazzed about some new ultimately pointless post styling—but I purposefully want these pieces to be less heavily edited and focused than all the other things. So, by throwing in a wankery introduction, it acts as a kind of gate you have to get through. So if this is too self-indulgent or tangential then you know to go away and I just continue and we’re all fine—although I think we’re deep into peak self-indulgence now that ‘people’ have evolved into ‘influencers’. Gah, that sounds condescending—and it is—and, worse, I think being condescending—especially in public like this—is probably much, much more destructive than influencing.)
(This isn’t just a gate, though, I want to mark this as the first steno, so that I can point to it later—and have it contain the reasoning behind this. Sure, I could make a separate steno that goes into those ideals, but it’s also kind of tied into the topic of ‘blogging’ anyway, so it’s like: why not just explain the thing and then flow right into it and then let it be for awhile and then come back and build on to it and—this is all just like what h0p3 does on his pages, this whole thing is a chance to have a part of that—and, again, what c2 had, what everything2 had/‘has’—it’s almost as if they were a fad. Like a sudden explosion of truncated octahedrons.)
Blogging simply made the static page seem alive. Then it turned into feeds and streams and the rate of speed was dramatically hiked up.
It’s possible that the word ‘blog’ is depleted. I think it was entirely stupid, but nostalgia has made it kind of neat. Like those little dixie cups dispensers that people used to have stuck on their bathroom walls. How great would it be to brush your teeth with such a companion again?
(This is unrelated, but if we are in a simulation, then we are probably deep into many, many simulations. It seems unlikely that we are only ever one-level removed from ‘reality’. It makes me feel like we’re probably either not in a simulation or that our inability to leave the simulation makes this absolute reality regardless.)
(This IS starting to feel strange. It does feel self-indulgent. It feels like it’s more for me than for you. Because I can’t rightfully expect anyone to read this—much like trying to read all of Wikipedia, there’s a threshold you have to set for yourself, that you’re not going to spend the time to read this kind of tripe. I don’t respect you for this, I don’t respect either of us. Maybe I never should have. And, for myself, it’s good to write carefully—to draw you in with great care and to not act this way. On the other hand, it’s hard for me to possibly know what to do with any of these pages! There are recipe and howto articles. There are anecdotes, punchline type things. You can easily add your two cents to a thought that’s propagating around. But I don’t know—I’ve never lived in a large city, and rarely even been to a really massive city, and I find myself looking at the buildings, just the sound of the air is so strange to me, the feeling of being on a street that is so worn and has fragments of millions of boots and beards and bits of sandwiches. I can see that it is an inverted rock tumbler, where the street is being tumbled by all of the things colliding against it. It is erosion of an industrial strength. But that wouldn’t be interesting to someone in a city, would it?)
(And then there is the experience of swimming—and often when we are swimming, we just wander around and work ourselves, talk and float. But if the pool is empty and you go to the bottom and hold your breath, it is the opposite of the city, it is insanely quiet, or an alien kind of subterranean quiet, and it feels like you have entered another level of the simulation, where you are a different person—you can do advanced yoga things down there that you normally wouldn’t be able to do and you sound differently, the bubbles that burst out in spurts produce loud, spontaneous waves and that’s what we sound like down there. And that, also, might not be interesting to anyone—or it might be interesting for everyone. Revealing that I also don’t know what’s interesting is a poor choice!)
Anyway, there’s about fifty reporters behind that door—real ones, not bloggers.
— Tony Stark, Spiderman: Homecoming, 2017
I like that ‘blog’ has remained a non-corporatized word in many respects. A ‘blogger’ is an ‘amateur’; the ‘blogosphere’ is the peanut gallery. It is a futile endeavor—and this is all good, because it important that some of these words stay personal.
Ok, so:
As for the software behind this particular blog, I call it Homeshade. I moved away from Jekyll the first week of September 2018. It was taking two minutes to generate my blog. That is down to three seconds now. (I’m sure Hugo could have done that, too. But I had other things I wanted to do as well—such as putting it into the Beaker Browser so I can just do everything from there.)
The technical part of this discussion is, fortunately, not that interesting really. The things that excite me out there right now are just being done with plain HYPERTEXT. (There’s another great corporatized word that never even got to be lame!) Homeshade is only a refinement, it is not a big deal. The point is only to utilize those things that we have that are under-utilized—like swimming on the bottom long enough to shut the sound out.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, sorry to be delayed in replying to you, Brad. I’ve had a broken blog for about two weeks. Rest assured, I’ve been reading along—around the time it broke, you wrote that Thank God for The Indieweb post and I couldn’t help but feel similarly, given that I started my blog around the same time.
I think you’ve got a great idea here—basically that Webmentions could be used to negotiate between two websites, to legitimize each other.
Maybe ‘nofollow’ links materialize into bona fide links once they each Webmention each other. I like that it could be started up from either side too. Someone who includes my directory in their blogroll is probably a good candidate to be in the directory.
One thing that I love seriously love about Webmentions is that they can just be easily killfiled. On Webmention.io, I can just nuke a mention and it’ll never come back. This means I don’t need any moderation tools built into my static blog, I can just use WIO directly.
So I think WIO is a great tool for a directory like this, because you could just build it in static HTML. In fact, this is what I’ve been doing with my directory—I am generating static HTML from a list of link descriptions. This allows me to easily host the directory aaaaaand now that you’ve mentioned this idea, I can hook up WIO in a few simple lines and have a built-in submission system!
So, yes, be flattered—I am stealing this/have stole. 😘
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Holy smokes—didn’t realize this was actually how this played out. I now see more what you mean by ‘sucking the fun’ out of Web1. Thankyou for spelling that out. Haha, now I am angry!!
So, is getting rid of the ‘Gates of Marlborodor’ good? I think it’s similar to my feelings about Yahoo!—I don’t miss having to click down seven levels to get to the ‘smoothies’ topic. (Or not finding it in the hierarchy at all!)
The trouble is: only a human can say if the ‘Gates of Marlborodor’ was useful to them. Google may not be able to tell the difference between a link farm and a link boutique, but a human can—and humans are the ones we’re trying to connect here, not the Baidubots!
One interesting thing to me: as I have been digging and scraping around for sites, using all the search engines and feeds I can find, there is one that I am finding surprisingly useful. The search on Pinboard—which is a bookmarking site, the heir to Del.icio.us. If you type in ‘smoothies’ there, you are going to get much more interesting results.
And it strikes me: I think it’s the closest thing we have to a human-edited search engine! Think of that.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The silos did help mainstream users form communities. This is still useful—carriers of rare diseases can organize on Facebook, stuff like the ‘TomNod’ group that coordinates to scan satellite photos. On Twitter, humor and art (pixel art, for instance) communities formed that can be casually observed by other Twitter users—bolstering their exposure.
But even all this traffic has become a bad thing! For instance, there is no ‘surfing’ any more (in the mainstream). For the most part, traffic just shows up. You don’t have to look for blogs because Facebook and Twitter stuff you with whatever they please all day.
My relationship is a lot healthier with blogs that I visit when I please. This is another criticism I have with RSS as well—I don’t want my favorite music blog sending me updates every day, always in my face. I just want to go there when I am ready to listen to something new. (I also hope readers to my blog just stop by when they feel like obsessing over the Web with me.)
Google is a silo too. And I can tell you Google is part of what sucked all the fun out of Web 1.0. Facebook and Twitter were not even around. It was Google. And living under Google dominance is no fun.
This isn’t completely true—mailing lists and forums were a big source of real blog readers. Like Usenet before them. Google was a source of poor, transient traffic. In those days, you could share your writings/findings with fans of a certain band or movie director (if that was your topic) by posting on their forum, just as you would with Reddit. (And links were shared on forums and mailing lists.) However, now you can get algorithmed to death. Your link can get lost in the feed before anyone sees it.
I think the best thing the silos brought was simply the ability to be notified of a reply without needing to check your server logs.
But I appreciate your perspective, Brad. I wish I agreed more on this one! Maybe in time.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Inspired by Brad Enslen’s ‘exit page’ concept, I’ve added a ‘the end’ post to this blog. (I also have to say that many of my upcoming changes are inspired by h0p3’s wiki—moving away from just a blog of recent posts, to a kind of modern home page with updates and Indieweb intertwingliness.) ‘The end’ can be seen right now on /page3, if you scroll to the very bottom. Small, needless things—lovely.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Hey this is up my alley: a webring whose aim is to ‘share personal websites such as diaries, wikis & portfolios’.

Hey this is up my alley: a webring whose aim is to ‘share personal websites such as diaries, wikis & portfolios’. I’m reluctant to add myself—these sites all seem to share a muted minimalist aesthetic. (This is a trove, however.) And it’s odd: I don’t think of webrings as having a sophistication—but here it is, a classy one. Like a precision watch lying on a marble jewelry counter. VERY interesting that this sprung up in the last few months. See, there really are rumblings out there.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I am going to make an effort to read through this dissertation and comment on it. One thing I like about the web is that it’s made of more primitive building blocks—too much orderliness injures flexibility. (Even blogs and aggregators have become too structured and, well, boring in a way.) I will still really enjoy reading this!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, a new list of personal home pages, blogs and such. My point in doing this exercise is to explore sites that aren’t linked to, that failed to launch, that Google won’t take me to. It’s very easy to attempt to advertise your site and have it disappear into the stream. Each time I do this, I discover new, unknown links that are amazing. Keep in mind that this is a raw dump, which I offer up to practice my directory-building skills and to give you a chance to peek as well.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Alexander Cobleigh’s directory to jacking into the decentralized web (dweb?)—no dat:// urls it seems, but useful discussions and howtos. (Appears Alexander also has a directory of links to an assortment of other things.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Looks like I am collecting links again on Hacker News. Anyone else out there? https://news.ycombinator.com/item?id=17673352
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Consider submitting your blog to this, if you are out there reading and have let me link to you before. I like that it’s focused on blogs—the directory I’m building is more general than that. His guidelines are very similar to mine: a few-hundred links with longer descriptions than you’d see on other directories.
Oh, and if you look at this and think: “I want to make my own directory!” Please keep me posted. I’m tracking the rise of these new directories closely.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Mostly, similar to what coldbrain has said, I find blogs when they are casually mentioned on a blog or comment somewhere. Stuff like blogrolls and directories and such just don’t seem to exist. I know, because I’m constantly looking for them!
Now, these things do exist in the small enclave of the Indieweb. There is the Indieweb wiki, which has links all over it. And IndieNews, Indiemap, Blog Snoop and so on. But if I’m looking for blogs and websites that are out there—it’s impossible.
If I’m looking for a specific topic, I’ll Google “quilting blog” or I’ll look on Pinboard under the tag “chess”—and see what blogs come up.
But more often than not, I really want to read someone interesting. Someone’s stories and thoughts. To find all the great writers of our time that are out there. (Most writers I know that write in the literary tradition are lost as to where they should find readers now. It’s terribly ironic when you consider all the reading that is done on the Web in this age.)
This all excites me, though! It seems that there is still a frontier on the web. There is still a chasm to cross between all of us. We have a long way to go.
And I think that’s what drew me to the Indieweb. The answer will start here, in this group, because we’re thinking about it. I think about when Ward Cunningham came out with the wiki—it seemed like such a small, pointless invention. But what a masterstroke! What will be next?
Oh and one more thought about directories: I have a theory that exploring a directory is possibly not directly the best way to discover new things. They can be big and dry and tough to get through. I think they more directly benefit the builder of the directory and, also, those listed in the directory.
The builder of the directory explores and unearths other folks. They then leak into this person’s life in a myriad of ways. (For example, I began by simply linking to you once, in pursuit of new things, but now I follow you very closely.) The initial link begets more. Knotty, twisty—here I think of Sam Ruby’s word intertwingly—vines of links around each other.
And the recipient of the link is possibly motivated to build their own directory, so as to establish (or at least to not forget) their new network. So it can be viral. Blogrolls very much experienced this.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Continuing my discussion from Foundations of a Tiny Directory, I discuss the recent trend in ‘awesome’ directories.
All this recent discussion about link directories and one of the biggest innovations was sitting under my nose! The awesome-style directory, which I was reminded of by the Dat Project’s Awesome list.
An “awesome” list is—well, it isn’t described very well on the about page, which simply says: only awesome is awesome. I think the description here is a bit better:
Curated lists of awesome links around a specific topic.
The “awesome” part to me: these independently-managed directories are then brought together into a single, larger directory. Both at the master repo and at stylized versions of the master repo, such as AwesomeSearch.
In a way, there’s nothing more to say. You create a list of links. Make sure they are all awesome. Organize them under subtopics. And, for extra credit, write a sentence about each one.

Generally, awesome lists are hosted on Github. They are plain Markdown READMEs.
They use h2 and h3 headers for topics; ul tags for the link lists. They are
unstyled, reminiscent of a wiki.
This plain presentation is possibly to its benefit—you don’t stare at the directory, you move through it. It’s a conduit, designed to take you to the awesome things.
Awesome lists do not use tags; they are hierarchical. But they never nest too deeply. (Take the Testing Frameworks section under the JavaScript awesome list—it has a second level with topics like Frameworks annd Coverage.)
Sometimes the actual ul list of links will go down three or four levels.
But they’ve solved one of the major problems with hierarchical directories: needing to click too much to get down through the levels. The entire list is displayed on a single page. This is great.
The emphasis on “awesome” implies that this is not just a complete directory of the world’s links—just a list of those the editor finds value in. It also means that, in defense of each link, there’s usually a bit of explanatory text for that link. I think this is great too!!
The reason why most awesome lists use Github is because it allows people to submit links to the directory without having direct access to modify it. To submit, you make a copy of the directory, make your changes, then send back a pull request. The JavaScript awesome list has received 477 pull requests, with 224 approved for inclusion.
So this is starting to seem like a rebirth of the old “expert” pages (on sites like About.com). Except that there is no photo or bio of the expert.

As I’ve been browsing these lists, I’m starting to see that there is a wide variety of quality. In fact, one of the worst lists is the master list!! (It’s also the most difficult list to curate.)
I also think the lack of styling can be a detriment to these lists. Compare the Static Web Site awesome list with staticgen.com. The awesome list is definitely easier to scan. But the rich metadata gathered by the StaticGen site can be very helpful! Not the Twitter follower count—that is pointless. But it is interesting to see the popularity, because that can be very helpful sign of the community’s robustness around that software.
Anyway, I’m interested to see how these sites survive linkrot. I have a feeling we’re going to be left with a whole lot of broken awesome lists. But they’ve been very successful in bringing back small, niche directories. So perhaps we can expect some further innovations.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

Can the failing, impotent web directory be transformed? Be innovated??
Can we still innovate on the humble web directory? I don’t think you can view large human-edited directories (like Yahoo! or DMOZ) as anything but a failure when compared to Google. Sure, they contained millions of links and, ultimately, that may be all that matters. But a human editor cannot keep up with a Googlebot! So Google’s efficiency, speed and exhaustiveness won out.
But perhaps there is just no comparison. Perhaps the human-edited directory still has its strengths, its charms. After all, it has a human, not a GoogleBot. Could a human be a good thing to have?
We now have an abundance of blogs, news, podcasts, wikis—we have way too much really. Links constantly materialize before your very eyes. Who would even begin, in 2018, to click on Yahoo!'s “Social Science” header and plumb its depths?

Strangely enough, even Wikipedia has a full directory of itself, tucked in a corner. (Even better, there’s a human-edited one hidden in there! Edit: Whoa! And the vital articles page!) These massive directories are totally overwhelming and, thus, become more of an oddity for taking a stroll. (But even that—one usually begins a stroll through Wikipedia with a Google search, don’t they?)
The all-encompassing directory found another way: through link-sharing sites like Del.icio.us and Pinboard. If I visit Pinboard’s botany tag, I can see the latest links—plant of the week the “Night Blooming Cereus” and photos of Mount Ka’ala in Hawaii. Was that what I was looking for? Well at least I didn’t have to find my way through a giant hierarchy.
Where directories have truly found their places is in small topic-based communities. Creepypasta and fan site wikis have kept the directory alive. Although, hold up—much like Reddit’s sub-based wikis—these mostly store their own content. The Boushh page mostly links back to the wiki itself, not to the myriad of essay, fan arts and video cosplays that must exist for this squeaky bounty hunter.
Besides—what if a directory wasn’t topic-based? What if, like Yahoo!, the directory attempted to tackle the Whole Web, but from a specific viewpoint?
You see this in bookstores: staff recommendations. This is the store’s window into an infinite catalog of books. And it works. The system is: here are our favorites. Then, venturing further into the store: this is what we happen to have.

“But I want what I want,” you mutter to yourself as you disgustedly flip through a chapbook reeking of hipster.
Well, of course. You’re not familiar with this store. But when I visit Green Apple in San Francisco, I know the store. I trust the store. I want to look through its directory.
This has manifested itself in simple ways like the blogroll. Two good examples would be the Linkage page on Fogus.me, which gives short summaries, reminiscent of the brief index cards with frantic marker all over them. This is the staff recommendation style blogroll.
Another variation would be Colin Walker’s Directory, which collects all blogs that have sent a Webmention[1]. This serves a type of “neighborhood” directory.[2]
What I want to explore now is the possibility of expanding the blogroll into a new kind of directory.
Likes, upvotes, replies, friending. What if it’s all just linking? In fact, what if linking is actually more meaningful!
When I friend you and you disappear into the number twenty-three—my small collection of twenty-three friends—you are but a generic human, a friendly one, maybe with a tiny picture of you holding a fishing rod. With any luck, the little avatar is big enough that I can discern the fishing rod, because otherwise, you’re just a friendly human. And I’m not going to even attempt to assign a pronoun with a pic that small.

It’s time for me to repeat this phrase: Social Linking. Yes, I think it could be a movement! Just a small one between you and I.
It began with an ‘href hunt’: simply asking anyone out there for links and compiling an initial flat directory of these new friends. (Compare in your mind this kind of treatment of ‘friends’ to the raw name dumps we see on Facebook, et al.) How would you want to be linked to?
Now let’s turn to categories. A small directory doesn’t need a full-blown hierachy—the hierarchy shouldn’t dwarf the collection. But I want more than tags.
---
Link Title
url://something/something
*topic/subtopic format time-depth
Markdown-formatted *description* goes here.
Ok, consider the above categorization structure. I’m trying to be practical but multi-faceted.
topic/subtopic is a two-level ad-hoc categorization similar to a tag.
A blog may cover multiple categories, but I’m not sure if I’ll tackle that.
I’m actually thinking this answers the question, “Why do I visit this site?
What is it giving me?” So a category might be supernatural/ghosts if I go there
to get my fix of ghosts;
or, it could be writing/essays for a blog I visit to get a variety of longform.
An asterisk
would indicate that the blog is a current feature among this topic (and this
designation will change periodically.)format could be: ‘blog’, ‘podcast’, ‘homepage’, a single ‘pdf’ or ‘image’, etc.time-depth indicates the length one can expect to spend at this link. It could
be an image that only requires a single second. It could be a decade worth of blog
entries that is practically limitless.The other items: author, url and description—these are simply metadata that would be collected.
The directory would then allow discovery by any of these angles. You could go
down by topic or you could view by ‘time depth’. I may even nest these structures
so that you could find links that were of short time depth under supernatural/ghosts.
The key distinct between this directory and any other would be: this is not a collection of the “best” links on the Web—or anywhere near an exhaustive set of links. But simply my links that I have discovered and that I want to link to.
I don’t know why, but I think there is great promise here. Not in a return to the old ways. Just: if anyone is here on the Web, let’s discover them.
I should also mention that many of the realizations in this post are very similar to Brad’s own Human Edited vs. Google post, which I cite here as an indication that this topic is currently parallelized. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, a few folks out there let me link to them! Oh, I’m so excited! It’s strange how hard it is to ask a question out on the open Web and to get a reply. If you have any idea how I can find new, unusual personal home pages and blogs—please clue me in.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I am collecting links to anything, anyone. Non-commercial, non-software links. It’s become somewhat difficult to find my way out of my bubble. So I’m wondering if you can just tell me where you are.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.




{kind=link}
Reply:
Pinboard and Indieweb.xyz as clustering tools.
Ok ok, one other thing that has dawned on me: it’s not just the emergent connections between writers that is salient when clustering. It’s the connections between readers as well! (This is one thing that Google cannot possibly capture.)
To akaKenSmith’s point:
The old Delicious was this kind of workspace for readers - a similar effort can be found in Pinboard.
One interesting thing I like to do with Pinboard is to look up a link - say ‘The Zymoglyphic Musem’ (results here) and then look at the other bookmarks for those who found the link. For example, the user PistachioRoux.
All of those links are now related to ‘The Zymoglyphic Museum’ by virtue of being in the realm of interest of PistachioRoux. YouTube uses these sorts of algorithms to find related videos by matching your realms of interest with someone else’s. However, in the process, that person is removed. (Or ‘those people’, more appropriately.) PistachioRoux is removed.
But perhaps PistachioRoux is the most interesting part of the discovery.
Particularly in a world which is becoming dominated by writers rather than readers - maybe the discovery of valuable readers is part of this.
This does sound a lot like Indieweb.xyz, as @jgmac1106 mentioned. The concept is simple:
So the emergence should come from blogs clustering around a given URL.
I’ve been wondering if they could do a similar thing with http://www.adfreeblog.org/ - a ‘general’ blog community could be established around a simple ideal like that.
Might look like this:
The adfreeblog.org home page then becomes a directory of the community. So, kind of like a webring, but actually organized. With Twitter cards and such floating in the metadata, it is probably much easier to extrapolate a good directory entry.
Spam is an issue with this approach - but it’s a start toward discovery. There aren’t a whole lot of ways for a blog to jump out from the aether and say, “I’m over here - blogging about keyboards too!” And, in a way, the efforts to squash abuse and harassment are making it more difficult.
I think it’s important to point out, though, that ‘awesome’ directories are intended to be human-curated, not generative. They feel like a modern incarnation of the old ‘expert’ pages.