11 Mar 2019
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.


This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

I don’t know what it is—but this blog has stuck with me. I can’t even trace the links I went through to get here. (I think I started at either Nannygoat Hill or jill/txt—which are also very interesting blogs that I’m still trying to sort out.) I originally started at the post where a guest author talks about seeing Cocteau Twins for the first time—and then I just started occasionally stopping in to read back. There are some really cool video shorts linked throughout this blog.
I don’t know what you call it when you were nostalgic for times and places that you never experienced—sometimes I can feel this the minute I start some old Russian sci-fi flick or whatever Iranian ‘slice of life’-type footage I happen upon. But this blog has that kind of sensation. (I’m also wondering why I’m just linking to blogs and Tumblrs like these rather than commenting on them and trying to strike up a chat. I’m short on time lately—I need to remedy this.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
h0p3’s wife does a mic check.
(This is sooo cool—to get a response from h0p3’s wife on her own personal wiki. I just can’t believe we’re having these conversations. This was not what I intended to do on this blog. I actually didn’t have any intentions really—I just wanted to mess with hypertext again—which I guess opened me up to reading random TiddlyWikis and having these delightful, possibly pointless, just-for-funsies conversations. It’s better than anything that I could have intended to do.)
k0sh3k! First off, I love ILL, too. I am a massive cheapskate and I try to avoid clutter—but mostly I just like the weird editions that show up. And I like to see where the books come from. (I give a shoutout to this in my Stories/Novels page.)
My favorite was when Denton Welch’s Maiden Voyage came in. It was an ancient hardback from the 1950s. (It was the first book I read by him—I love him now.) As I read, I began to realize that this edition had been published right after he died (at age 33) and it really transported me to that age. I had a hard time giving that one back.
I actually should read The Educated Mind again before I recommend it. I went back and read my review—and some of my perspectives have changed since then. A lot has happened in four years. I still think I would love that the book bows before the visage of Socrates… (I am not a fast reader.)
My favorite poet is e.e. cummings, and if you haven’t read his work, you should.
I loved him in high school—I guess I have forgotten so much about him. I think I liked him at the time for gimmicky reasons. I know I saw past the mere shape of his poems. I thought he was funny. But to hear about ‘anti-industrialist poems’—you shouldn’t have lost that paper.
You’ll have to excuse the place - I only started keeping this to make h0p3 happy and to be a good example to the kiddos, although I’ve started keeping things here just for fun, too.
I am not nearly as good at keeping a wiki as h0p3 is; I haven’t gotten much better on any of this web stuff since the early days of chat rooms.
I think it’s charming. Your worries about organization or curating—sure, it’s fun to spend time on that stuff—but you’ve put a lot of work into what you’ve got already and it’s already very amusing and interesting to idly search and click around. I like that it’s informal. I like that it’s off-the-cuff.
I feel I should apologize for reading. It feels voyeuristic. Or like a robot eating up feelings. (CAN DESPISING AYN RAND REALLY FEEL THIS GOOD.) And maybe I am just scoping up anecdotes and recommendations in slapdash—this is just my own librarian way. It is shameful, it is noble—it is just a way to pass the time.
I think education, across the board, including college level, has hit a rough patch. It’s no longer about helping individuals become good, ethical human beings; it’s about shaping individuals into efficient little workers and consumers. I’m glad we have the chance to raise our kiddos to be good persons, and to recognize the systemic evils that use others as mere means for wealth accumulation.
Most of the teachers I’ve met and worked with are aware of this and frustrated by it, too. It’s strange to me that this awareness has been around since at least the 1970s—yet it’s only gotten worse, I’d hazard.
There was a conversation between Seymour Papert and Paulo Freire back then that really—well, it might have gone too far in places, but I think it’s mostly right on:
Now there comes a time when the infant is seeing a wider world than can be touched and felt. So the questions in the child’s mind aren’t only about this and this and this that I can see, but about something I heard, saw a picture of, or imagined. And I think here the child enters into a precarious and dangerous situation because not necessarily, but, I think, in point of fact in our societies, there is now a shift from experiential learning—learning by exploring—to another kind of learning, which is learning by being told: you have to find adults who will tell you things. And this stage reaches its climax in school.
And I think it’s an exaggeration, but that there’s a lot of truth in saying that when you go to school, the trauma is that you must stop learning and you must now accept being taught. That is stage two: it’s school, it’s learning by being taught, it’s receiving deposits of knowledge. I think many children are destroyed by that, strangled. Some, of course, survive it, and all of us survived it, and that’s one reason it’s often dangerous discussing these questions among intellectual people. In spite of the school what happened to us was that in the course of this stage two we learned certain skills. We learned to read, for example; we learned to use libraries; we learned how to explore directly a much wider world.
Now I think that there’s an important sense in which stage three is going back to stage one for those who’ve survived stage two—creative people in any field, whether in a laboratory or in philosophy—whether artists, businessmen, journalists—all the people in the world who are able, despite all the restrictions, to find a way of living creatively. We are very much like the baby again. We explore; it’s driven from inside; it’s experiential; it’s not so verbal; it’s not about being told.
To me, I agree that the scaffolding is important—but I think we tend to make the whole thing about scaffolding and public school tends to be all scaffolding all the time. But I think of scaffolding as being rough-shod. You hammer together a few planks and then get back to the building itself. The scaffolding goes away with time. You forget it was ever there.
(In case this is too vague—I tend to make ‘scaffolding’ synonymous with ‘adult assistance’, Vygotsky’s meaning, rather than the other meanings that float about from time to time.)
Of course, I think the above goes wrong a bit because I view reading as experiential and driven from inside—and I think even “telling” can be this way. Teaching can be very immersive and very improvisational. It’s difficult to know if it can ever be prescribed. (I don’t often watch television, but I think this is one thing that has kept me watching The Good Place—the main character is provided with a personal philosopher, a man who finds himself given an Herculean chore to try to prescribe his wisdom to her, even though it all is completely applicable. It simply cannot be told I think.)
Thank you for all the books and links—I will always be on the lookout for more and I am glad to know you and your family. While I’m interesting in the pioneering work you all are doing with wikis and such, I think it’s eclipsed by the effort you make among your two children. These words might be, at their height, a ‘model’ of us.
But they are only artifacts compared to the humans behind them. This j3d1h and kokonut seem like great additions to our reality. (Just from things they pop off with in h0p3’s writings.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Some notes on how I am using crawlers as I’m collecting links.
I’ve started dabbling in crawlers with two simple prototypes—these may not even be considered crawlers, but simple web fetchers or something like that—but I think of them as being (or becoming) fill crawlers. Most crawlers are out exploring the Web, discovering material and often categorizing them, given some kind of algorithm that determines relevancy. Here, I’m the one discovering and categorizing; the fill crawler only does the work of watching those pages, keeping me aware of other possibly relevant sites and notifying me when I need to update that link.
So, these crawlers are filling in the blanks for certain links. Filling in missing parts that aren’t editorial. This isn’t a crawler that is feeding the site’s visitors—it’s there for my utility.
For href.cool, the crawler isn’t really a crawler, given that it doesn’t do any exploring yet. It just updates screenshots, lets me know when links are broken and tracks changes over time. Eventually, I hope that it will keep snapshots of some of those pages and help me find neighboring links.
Anyway, I’ve had that crawler since the beginning and it will stay rather limited since it’s for personal use.
For indieweb.xyz, I’ve started a crawler that’s also for keeping the links updated. Yeah, I want to know when something is 404 and keep the comment counts updated. But I also want to get better comment counts by spidering out to see the links that are in the chain. This crawler allows indieweb.xyz to stay updated even if Webmentions don’t continue to come in from that link.
I think the thing that excites me the most about this crawler is that I’d like it to start understanding hypertext beyond the Indieweb. I’m hoping it can begin to index TiddlyWikis or dat:// links, so that they can participate. I’d really like TiddlyWiki users to have more options to broadcast that doesn’t require plugins or much effort—they should remain focused on writing.
Both of these projects are focused on trying to help the remaining denizens of straight-up Web hypertext find each other, without it functioning like another social network that becomes the center of attention. To me, rather than giving the crawler the power to filter and sort all these writings, it simply acts as a voracious reader that looks for key signifier that all of normal readers/linkers are looking for anyway. (Such as links in a comment chain or tags that reveal categories.)
That’s all I have to say at the moment. I mostly put this out here so that people out there will know how these sites work—and to connect with other people (like Brad Enslen and Joe Jennett) who are doing cataloging work, to keep that discussion going.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
So, as a result of the work Chris has been doing in Wordpress, making it easier to post to Indieweb.xyz, I’ve started “rolling up” all the posts by each user on the home page. I’m just trying this to see how it feels. I’m going to try quite a lot of things over the next few months. Let me know what works for you.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Heyo—‘My purpose is to curate a living map of the world’s knowledge.’
I’m fresh into this link—so I don’t quite have a clear picture of this fellow (Michael E. Karpeles)—but I see a kind of h0p3-like thing going on here. A huge, straight-up link directory that is definitely in the public self-modeling vein.
Related project: fromscrat.ch done in the same fashion. This is a rabbithole, no doubt about it. See what you can find.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, interesting—yeah, I’d agree, hunting can suck up hours of time. And, yeah, if you are spending four hours per day, I’m not going to keep up, since I’m lucky to get in four hours per week.
Glad for your honest reason. Very glad for ‘brutal’ honesty—to just have your thoughts succinctly, rather than to beat around the bush for three months.
What I mean to say is that I’m not looking to combine my efforts with yours (or vice-versa). We’ve already shared knowledge and our enthusiasm for the medium and our love for linking—that’s sure to be an ongoing (enjoyable) thing. But pooling our knowledge, or collaborating between sites on some type of joint effort is different than simply communicating between sites, and between us, in my mind.
Right—I don’t mean to say that we’re going to just merge our sites together—although I did discuss trying to be clear about link-finding strategies, which borders on a trade secret I suppose. (Especially where you’ve been doing this for several decades.) And I am happy to rescind that request—I’m not trying to steal your strategy, even if I am planning to clearly lay out mine.
But let’s back up: I think we must have a fundamentally different view of where the Web is today. (imho) Link-finding has changed dramatically from the early days of the Web. Back then, everything was a link. The whole landscape was personal home pages, web comics, and niche forums. Magellan-level exploration.
Today, the Web we’re inhabiting is a niche. There is very little growth out here by comparison. Surely, there is still an infinite landscape to explore, but much of it is ad-ridden, startup- or software-focused. ‘Bloggers’ are moving toward ‘influencers’. When people talk about ‘the blogs’, they think about pundits, TMZ-type Paparazzi and minor celebrities. The rest of blogging has become an extension of Pinterest: personal recipe and home decor blogs dominate.
The ‘Indieweb’/‘Indie Web’ is a niche like vinyl collectors. It won’t ever achieve mainstream significance again. When I talk to meatspace friends about The Web, they look at it as a quaint little city that doesn’t really offer them anything new. And the only thing I can appeal to is a type of idealism: aesthetic and political idealism.
So, whereas link-finding use to be the essential task of mapping out the frontier, our new task is different: to broadcast the location of our outpost so that the holdouts who are still blogging and the wanderers, who happen to be drawn to experiment with a blog, know where we are.
I really think that an important part of our work will be to lay out how we link-find—not so that newcomers can just copy the technique—but so that they know where we’re looking. If we’re looking at tags on Pinboard, then they know where to post on Pinboard. If we’re sharing on certain hashtags on Twitter, then they know. In the past, this might have caused those channels to be oversatured—but I really don’t think spam will be our problem. Our problem is survival.
Of course, we wish the old days would return. But the future will be better, somehow. I just don’t think it will inhabit The Web again.
If you disagree or roll your eyes at any of this—no problem, no problem whatsoever. The invitation is soft—no need to get involved with anything. Focus on your work. (Fantastic work!) I just hope that my efforts won’t be upsetting you in some way. I’d rather be of a benefit, if that can possibly be the case.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This has been cool to watch—you’ve managed to bring over all your old links, everything looks good—and we can now crosstalk directly on your pointers pages and blog entries. This is great!
It’s funny—I stumbled across the VISUAL OBSERVER link around the same time as you. I think we’re both plundering a lot of the same tags and users on Pinboard. This has made me want to pool our link-finding knowledge, in the hopes of discovering where we’re being redundant and where we might want to venture out further. (I need to make a list of my main discovery avenues.)
To what degree do you grind away, looking for links? Or do you wait for them to come to you?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
There was a similar train of thought in the thread we were having with Dave Weiner, Don Park and Greg McVerry some time ago. It kind of got lost, but I had a similar webring-like idea for the Ad-Free Blog website. (Which is no longer around, as of last month, it seems.)
I’ve been wondering if they could do a similar thing with http://www.adfreeblog.org/ - a ‘general’ blog community could be established around a simple ideal like that.
Might look like this:
- A blog links to adfreeblog.org on their home page.
- Adfreeblog.org notices visitors coming from that page and checks that page for the link and the image.
- If found, it adds the blog to a directory, using the meta description and keyword tags.
The adfreeblog.org home page then becomes a directory of the community. So, kind of like a webring, but actually organized. With Twitter cards and such floating in the metadata, it is probably much easier to extrapolate a good directory entry.
As you say, the “mandatory reciprocal link” is not something you’re comfortable with—but I think it has its uses. I have no care in the world whether any of the sites I link to at href.cool ever link back to me (in fact, I’d prefer if they would just keep doing what they’re doing) but I think a directory that’s trying to provide a more census-like approach could really use this strong, two-way link.
I think it would be really cool to have an emergent directory where everyone self-categorizes. You get to be in one category—where do you put yourself? And, yeah, have a bit of moderation in there to weed out spam. It would likely be very difficult to sort through its problems—but it would be fun to try. (The Indieweb.xyz blog directory is as close as I’m going to get to that effort for the present.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Some poems, some surrealists, some nicer margins, who cares.
Quite a few new links and poems added today:
The Tragedy of GJ237b, an unusual role-playing game added to Games/Imagined.
Bukowski’s “16-bit Intel 8088 chip” poem added to Stories/Poems. I’m not an enormous Bukowski fan, but this fits so well. I’d like to highlight it, for now. (Also, I really like the beginning of the Michael Longley poem quoted by @vasta today—although, at some point, I hope to rotate out popular poets for the more underground ones.)
“Hope”, another poem. A section on just simple, uplifting kinds of poems.
“The Book of My Enemy Has Been Remaindered”. A section on angry, tear-your-face-off poems.
The House of Mysticum, a surrealist blog—I think this could become a major subgenre of blogging, if it isn’t already. Added to Supernatural/Texts.
Smash TV—a vaporwave miniseries. Added to Tapes/Vaporwave.
Eleven-Minute Painting. I’m not sure why I’m drawn to this—I also found a number of derivative works and listed them under Visuals/Motion.
Reality Carnival. A long-running link log, along the lines of the links that Joe and Brad are collecting. Added to Web/Links.
I’ve also been improving the themes—trying to get them as nice as possible on all the various browsers and devices out there.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Matthias Pfefferle asked for a German edition of Indieweb.xyz and it is ready now.
Since Indieweb.xyz seems to be useful to some of you, I’m working through a list of updates that will clean it up and make it more versatile.
The first major change is to add another language, German, at the request of Matthias Pfefferle. (The German edition is at indieweb.xyz/de.) The Github project that I am linking here is where new languages and translated text can be submitted.
I’ve also hidden the hottubs sub from the home page. This will allow you to
test the system without broadcasting to everyone.
These are all the changes for today, but I wanted to let you all know out there that I have got my hands in the code again, in case you have any requests you want to call out.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Haha! This is a very thoughtful and generous review! I am very grateful that you took the time to look through the cigar box and write down your impressions like this.
Normally I would be disappointed that you had no criticism or suggested improvements—however, in your case, I designed the thing very much with you (and our conversations) in mind. It’s a reaction to Indieseek and influenced by many of the web directories you’ve worked on in the past. So I really wanted to impress you—definitely.
I have been trying to consider what to write about the months I spent building it. One thing that is very unusual about Href.cool (under the hood) is that it only loads once. So if someone links you to the Bodies/Adventure category—it’ll load the HTML for that category and it will also load the rest of the directory (but not the images) using JavaScript, so that you can browse it without any delay. The directory isn’t very big—and I thought I’d take advantage of that.
At the same time, the directory can be easily browsed with JavaScript off. No problem there.
My reasons for taking this approach:
I wanted someone to have the ability to download a single page of the directory and that would save a local FULL copy of the directory. (This doesn’t work completely yet on all browsers, but I am almost there.)
This makes it easier for me to share a single-file version of the directory on decentralized web networks (like the Dat network and IPFS.) I want it to be simple to back up.
TiddlyWiki is currently the only software I know of that keeps everything on one page. But it’s showing its age. I wanted to start playing around with alternatives to TiddlyWiki that can be single-page but still work with the Indieweb.
To me, this aspect of the directory is the most exciting part. And since it’s all static HTML, I don’t need to install Wordpress or some other server software to manage it. I’ve noticed that you’ve had some server errors showing up on Indieseek and I’d really like to help prevent that kind of thing. (I’m getting errors on the listings pages on both Indieseek and the ‘Nodes’ directory.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Webmentions and five new links.
Okay, so I’ve added outgoing Webmentions to Href.cool. This means that sites will be notified if they are linked in any of my categories.
Incidentally, the directory itself has also has Webmentions. So, if you have an Indieweb blog and you want to recommend a link to the directory: make a post containing the link you want to submit and a link to the category page you think it belongs on and I will get the message. I may also choose to list submitted links at the bottom of the page. Or, yeah, you tell me if this is useful to you.
A few new links have been added:
Carlos and Adrián’s Top Gear: Vietnam Special: I discovered this blog in one of my previous HrefHunt! and thought it was relevant to my Bodies/Adventure. The entire Bodies category needs a lot of work.
“The Accidental Room” (2018): Also added to Bodies/Adventure. I felt I should definitely cover camping in strange areas.
“Afternoon of the Sex Children” (2006): This essay was previously a smaller citation in the Bodies/Human area and, after revisiting it, I felt it warranted a quote.
“I Was a Cable Guy” (2018): This recently published article is perfect for the Real/Society page. It’s astonishing and absorbing and helps flesh out an aspect of society that is not well-covered in that section: the private homes of people.
Simon Griffee: Another one from the same HrefHunt!. Linked under Visuals/Images. I love that these links will bubble up as I continue to ponder them as time passes.
I also linked to notepin.co as a possible blogging option.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
My new directory.
Krikey—I’ve been working on this directory for five months! I am not quite happy with all of it. But it functions mostly like I want it to. And the links are fine, as a start.
I will discuss it more over the next few weeks—mostly I just want to get it started so that I can start connecting with Joe, Brad and the rest of the world. Hope you find something you like!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Huh: search engine that peeks through the cracks.
I’ve decided to exclude this from my directory for now, but I think this search engine raises some interesting questions. It indexes any video that is public, but not listed in YouTube’s searches. I’m not going to comment on whether these should be indexed—but I think this is a valuable tool in a surfer’s kit. (Continuation of the Searching the Creative Internet thread from the other day.)
Take this. Take Pinboard search. Take Million Short, Wiby.me, maybe take /r/InternetIsBeautiful—these start to give a good picture of the web we’re a part of. Oh, snarfed’s Indieweb search, perhaps.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
(Joe’s full article is here.)
Yes, here we are again—I think what you’re saying is that even a single-line annotation of a link, even just a few words of human curation do wonders when you’re out discovering the world. (Perhaps even more than book recommendations—where we know that at least we can rely on certain publishers and editors to vet their publications—I’m a big fan of the Dalkey Archive[1], for instance—but we have no idea the quality of writings out on the Internet at large and are desperately reliant on these annotations in the field.)
Pinboard is doing everything right in that regard—of course, it cribs from Delicious before it—giving hyperlinkers an appropriate amount of meta-dressing to put around their link: tags, description, search tools. However, it misses out on the kind of visual styling and layouts that you, Joe, get to enjoy. (I really like how you batch up links for the day, similar to how h0p3 does it.)
I think another of my lingering questions is: what are we really doing here? When I look at h0p3’s links, he’s trying to catalog his discoveries for the day completely—at least, I don’t think he edits this list. You also mention in your essay that you ‘curate links for my own ongoing use’. Whereas I tend to ‘advertise’ links more, to bring attention to the parts of the web that I want to survive.
So it’s more natural for me to work towards a final directory of links, a hub of all the nodes that I want to see connected. I want these individuals to be aware of each other. I see your Linkport as being a type of directory; I wonder to what extent you are doing this as well—and I wonder what kinds of collaborations we could get going between our directories. You do say that ‘people finding me and finding some of my links enjoyable’ is a secondary goal. I guess another angle I keep alluding to is the benefit you give to the authors behind the links you’re publishing—this type of work is a tremendous gift to them.
Along these lines: I see link duplication as being an interesting thing—clearly we don’t all just want the same links, but I think it will be interesting to see how much overlap there is. I also really like, for example, when David Crawshaw’s article last week got linked by h0p3, Brad, Eli, other microbloggers—it made me feel like we were trying to send some kind of concentrated transmission to the author—linking as a greeting, links as an invitation.
With time, many personal sites and blogs disappeared from the web as people flocked to the big silos where their content became a heavily monitized commodity. To me, the web had lost much of its soul as people gathered in just a few, huge noise chambers. […]
Current trends and a rebirth of personal blogging certainly make the type of curation I do much easier, thank you. Had it not been for that stimulating conversation, I probably would not have been writing this.
It’s interesting to me that the corpypastas had this kind of effect. Because they actually eased publishing and participation for so many people. Facebook is a type of gated community—so I see why it had this kind of effect. But it’s interesting that Twitter and Instagram also dampened the growth of the web. I hazard that perhaps this was simply because their game was best played by their rules—an external link to Twitter wouldn’t show up in your ‘likes’ whereas a like from another tweet was fully realized by the author and the… err… liker.
And I don’t want to chalk this up to mere ego—the author and the liker could see each other from across the Internet. And that is valuable. This is also what micro.blog is assisting us with—we have our blogs, but it is a useful capsule pipeline, so that we can get to each other clearly. (This is why I’m not just linking to your blog post and waiting for you to notice somehow—this communication structure that we’re using here is very useful to us, even if I can almost guarantee that this post is going to be flattened into a massive paragraph by micro.blog. No problemo—I’m just glad to have a direct line to you, Joe!)
Regarding another thing Kicks asked about: Aside from evolving html, accessibility, and design standards and practices, I’m really not sure if linking, in general, has changed over the years. I’ve been doing it the same since day one. But that’s just me.
For me, I do find that Webmentions are really enhancing linking—by offering a type of bidirectional hyperlink. I think if they could see widespread use, we’d see a Renaissance of blogging on the Web. Webmentions are just so versatile—you can use them to commment, you an form ad-hoc directories with them, you can identify yourself to a wider community. I really feel like they are a useful modernization.
But I like that you are true to the linking you’ve always done. It still works. It’s an ideal that we fell away from I guess.
The Third Policeman, of course! But also: Heartsnatcher by Boris Vian (just my kind of meandering, vexing thing), Writers by Antoine Volodine. And soon I will get into Impressions of Africa by Raymond Roussel. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Oh and yeah—can you pass along this link trove? I do a monthly ‘href hunt’, asking everyone out there for personal URLs—one of the problems is where to go to notify the world of one’s nascent blog or wiki? I can write up your collection—or link your write-up. Anything to help.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A self-catalog—tho this format could fly as an outgoing directory.
I mostly cover obscure writers. James is a widely published author (The Atlantic, Playboy, Aeon) but this is a neat personal directory to his writing—very homespun and lightly annotated, with asterisks and highlighting used to nice effect.
Articles such as How I Reverse Engineered Google Docs To Play Back Any Document’s Keystrokes are a festive hybrid of code, anecdote and sundry links—found in paragraphs festooned with blue underlines that act like surprising miniature directories nested in the article. (This is an approach that I feel I need to cover in Foundations of a Tiny Directory.)
I also think it’s interesting that he catalogs all of his individual blog entries. This whole page very much fits in with my definition of Hypertexting—these scattered essays and posts become a body of work here. And the quality is excellent: generally well-considered and well-executed.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This article is in my dept, man—great stuff. I am writing a blog that covers obscure websites, interviews unknowns, etc. Although I am advocating a return to (dun dun) web directories: https://www.kickscondor.com/foundations-of-a-tiny-directory
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
More thoughts on moving beyond Google.
I’ve been saying for awhile that Google doesn’t work for me—but I think this essay crystalizes the thought in a much better way than I’ve been able to.
If you click through all 14 pages of results Google returns for [disney], nothing I could conceive of as interesting appears. Corporate website this, chewing-gum news article that. But if you refine it a little and search for [disney blog], then by result Page 7 things start to get interesting.
I’m not sure I agree yet with the idea that we can solve this with better search engines—I am really focused on trying to bring humans back in: as editors, as librarians, as explorers—we can do this kind of stuff really well, this is our strength! But I’m warming up to the idea that search engines could be a tool for these surfers.
What is clear to me is that it is time for separate tools. A search engine designed to be used by billions of people every day to do daily tasks is not one that will be appropriate for weekend meanderings though obscure topics. A content-sharing site like Reddit that encourages links to the New York Times will not generate thoughtful discussion.
See, to me the issue is that ANY algorithm involves encoding a ruleset that strictly describes what it is looking for. So by the time you encode your crate-digging behavior as an algorithm—it has lost its flavor.
Imagine a computer writing jokes. Not that that can’t work—but I think computers are far away from making jokes that aren’t inadvertant. So only by being nearly random does it become evasive enough to avoid malignant behavior. But a human is subject to its own evasive manuevers—it can get fatigued with sameness, it can become bored, it can become sensitive to the fashions of its time, it has its own ineffable subjectiveness. So it is capable of leaving its encoding—of evolving, or of returning to its roots, discovering something forgotten or uniquely nostalgic. (I think the algorithms are great for discovering the answer to a technical question—you want that search to be predictable.)
This is a great article and it describes a longing for the kind of thing that we’re all trying to build here—I know it sounds like I’m wrapping all of you out there—and those I’m communicating with regularly—in a blanket statement—if I am, then certainly push back—but I think this is what ties us: to preserve humanity on the Web, perhaps to find more meaning in this work. So I hope to see this Crawshaw person around here at some point.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Wow, you hand-check the whole thing?? Ok, wow, so if you don’t mind I have a few more questions—actually, quite a few more, but I’ll constrain myself!
Also, if you’d rather post your answers as a blog post, I can link to that. Great to meet you—I’m immediately a huge fan!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Cool thread. Getting myself in here. Hi, folks!
Joe, amazing site—Linkport. How on earth have you kept the links all intact? I couldn’t seem to find a broken one.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Joe Jenett’s link collection—been going strong for decades.
Oh boy, the micro.blog surf club is really coming together: Joe Jenett has said ‘hello’ by dropping a link to this directory of fantastic obscure blogs and things. (I think he and Brad Enslen met through Pinbard? Does that happen??)
Linkport goes back to 2000. But Joe has been collecting links since 1997:
I thought of pulling the plug (on the daily pointers) for the same reasons but decided to keep it going with a combination of new links and repeat links to sites with recent updates, along with working hard to keep it clean of bad links. Yes, it all takes a lot of time but fortunately, I enjoy doing it - it’s in my blood.
Even the oldest links in the directory still seem to work. I bow in humble deference.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
It’s more common to converse with a computer than to just dictate our instructions to it.
I’ve been helping a friend with a Discord bot, which has opened my eyes to the explosion of chatbots in recent years. Yes, there are the really lame chatbots, usually AI-driven—I searched for “lame chatbots” and was guided to chatbot.fail, but there’s also the spoof ‘Erwin’s Grumpy Cat’ on eeerik.com.

We’ve also quietly seen widespread use of sweet IRC-style bots, such as Slack or Twitch or Discord bots. These act like incredibly niche search engines, in a way. My friend’s own bot is for a game—looking up stats, storing screenshots, sifting through game logs and such.
So, yeah, we are using a lot of ‘one-line languages’—you can use words like ‘queries’ or ‘commands’ or whatever—but search terms aren’t really a command and something called a ‘query’ can be much more than a single line—think of ‘advanced search’ pages that provide all kinds of buttons and boxes.
Almost everything has a one-line language of some kind:
Humans push the limits of these simple tools—think of hashtags, which added categorical querying to otherwise bland search engines. Or @-mentions, which allow user queries on top of that. (Similar to early-Web words, such as ‘warez’ and ‘pr0n’ that allowed queries to circumvent filtering for a time.)
It’s very interesting to me that misspellings and symbolic characters became a source of innovation in the limited world of one-liners. (Perhaps similar to micro.blog’s use of tagmoji.)
It seems that these ‘languages’ are designed to approach the material—the text, the tags, the animated GIFs—in the most succinct way.
I wonder, though, if ‘search’ is the most impotent form of the one-liner. It’s clearly the most accessible on the surface: it has no ‘commands’, you just run a few searches and figure out which ‘commands’ work until they succeed. (If they do?)
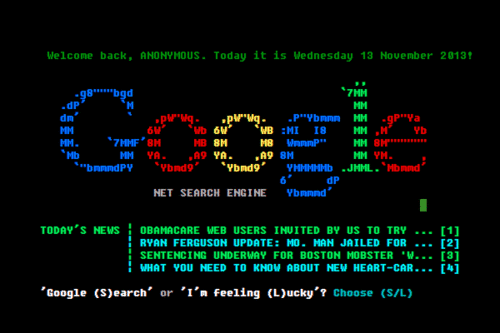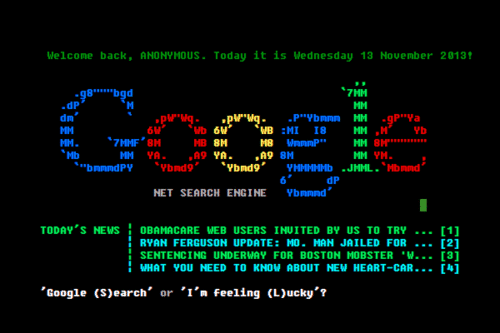
It also seems relevant that less than 1% of Google traffic uses the I’m Feeling Lucky button. Is this an indication that people are happy to have the raw data? Is it mistrust? Is this just a desire to just have more? Well, yeah, that’s for sure. We seem to make the trade of options over time.[1]
Observations:
Some sites—such as yubnub and goosh—play with this, as do most browsers, which let you add various shortcut prefixes.
Oh, one other MAJOR point about chatbots—there is definitely something performative about using a chatbot. Using a Discord chatbot is a helluva lot more fun than using Google. And part of it is that people are often doing it together—idly pulling up conversation pieces and surprising bot responses.
Part of the lameness of chatbots isn’t just the AI. I think it’s also being alone with the bot. It feels pointless.
I think that’s why we tend to anthropomorphize the ‘one-line language’ once we’re using it as a group—it is a medium between us at that point and I think we want to identify it as another being in the group. (Even in chats, like Minecraft, where responses don’t come from a particular name—the voice of the response has an omniscience and a memory.)
It’s also amusing that Google keeps the button—despite the fact that it apparently loses them money. Another related footnote: the variations on I’m Feeling Lucky that Google has had in the past. Almost like a directory attached to a search. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A directory of ‘federated’ communities.
A list of all of the various blogging and messaging services that are connected to each other by way of ‘federation’ (e.g. Mastodon). This is impressive—user statistics and lists of smaller communities within each group. I’ve thought that the Indieweb was ‘ahead’ of the Fediverse, but it’s much easier to find each other with this kind of centralized directory.
I also generally advocate human-curated directories. But, in the case of examining the offerings of a network, this kind of entirely machine-constructed catalog makes perfect sense. A stat-based and rather spreadsheet-like view is the whole point.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A religious satire crossed with a home page. This is also covered in this episode of a show called Deep Web Browsing. Just linking this in case I want to follow the trail further.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Indices, catalogs and maps of the hypertext ‘body’.
I am discovering more and more of these—what I am calling ‘link maps’, perhaps there is another name—collections of links that act like an index or a topical guide to a large ‘body’ produced by Hypertexting. You might want to conflate these with wikis—most wikis do act like ‘link maps’—but I am specifically looking at a ‘link map’ and a ‘body’ as being seperate entities. Much like a map and the dungeon or landscape that it maps are separate.
A very similar word is ‘sitemap’—perhaps ‘external sitemap’ is a better term—but I tend to think of a ‘sitemap’ as a complete map, whereas a link map might be limited or contain duplicates (like an index). (For comparison, see the sitemap for Purdue’s writing guidelines or the SuperMemo sitemap as standard examples. Though, I’m not sure how these would differ from a ‘table of contents’. Or a ‘home page’—such as Paul Burgess’ home page, which is a directory to itself.)
Some of my collection:
The Mother Horse Eyes index, which maps the stories, background, chronology created by Reddit user _9MOTHER9HORSE9EYES9. (Reddit wikis do function more like ‘link maps’ usually, because they are attached to an arbitrarily-shaped body of discussion.)
The story index for Alice and Kev, the story of being homeless in The Sims 3. This one interests me because it is a completed blog that has been organized by the writer.
The Mencius Moldbug topical archive and chronology. Please don’t make me comment on what ‘toxic’ or ‘enlightened’ substance might be in these papers—I have no idea. I am just looking at the layout and possible uses of the link map. (Related: Yvain’s posts on Less Wrong.)
Index of users banned from the ‘slate star codex’ reddit.
QAnon Map, it’s crazy to me this polished, almost military-grade skin over a 4Chan. I think this is sufficient proof that the underlying technology doesn’t matter—and it may even be a benefit to be plain, easy to copy-paste—when building a hypertext ‘body’.
_why’s Estate, collected writings of a programmer who abandoned all of his work.
Gwern’s home page is a topical guide to the site.
These all seem to follow the collapse or completion of a work—very few maps seem to be made while the ‘body’ is underway. I also wonder to what degree these misrepresent the ‘body’.
This document, however, isn’t a ‘link map’ because I am just linking to a bunch of separate ‘maps’ rather than focusing my links on a single ‘body’ of work.
I will add to this list over time, who knows where it’s going.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I spent about a week playing with Federated Wiki and was initially extremely excited about it—I’ve always admired Ward Cunningham’s work, there was a recent blog post called The Garden and the Stream that promoted Fed Wiki as a way to do Hypertexting (‘the garden’) and I had hoped to integrate my hypertext with it.
However, it simply did not function for me and I could not seem to find useful protocol documents. I didn’t even feel like it was worth posting about yet. I will continue to keep an eye on it to see if it becomes something practical. (Even as a reader, I find fedwiki.org really neat but difficult to use—I feel that it is more opaque than TiddlyWiki even.)
If you chose to go with a search feature, I was going to add you to the search engines at the bottom of Indieseek’s SERP like I did with Wiby.me. That way I could share traffic – like someday when I have traffic, with your directory.
Yeah, so—I think we start talking about federating our directories. Here are some basic starting points:
A central search engine that we can use to index our directories. I will work on this at some point. Or maybe sites like Wiby.me could collaborate with us. I may require microformats for the directory entries and maybe there will be a novel way to use Webmentions.
And, possibly, a directory using the same index—the question is how to find matches between our categorization systems. Perhaps we could treat categories like tags—or to provide a mapping to another category system.
Perhaps a way of collecting submissions from a central bucket? Maybe we could publish our submissions on a page, regardless of whether they’re included—this could also be useful for establishing a spam list.
It would be cool to syndicate entries—like I may want to take an entry from yours and embed it in mine. People may want to syndicate entries elsewhere—maybe as Twitter cards. And, most importantly, I may want to periodically ‘guest’ a directory and highlight that directory’s activity for a month.
I think it’s also useful to acknowledge that this is all different from Pinboard because our directories:
Are heavily filtered. We don’t include stuff that is ‘to-be-read’ or not (in our view at least) of very high quality or interest.
Entries generally have thorough commentary.
There is kind of a team thing going on—you and I are working separately, but there is a lot of collaboration and linking going on—I see this being good long-term because we can rope in others who cover other topics and act like a decentralized DMOZ. We could even safely double-up on the same topics because people will have different takes.
Interesting point about using comments and stars yourself. Sounds cool!
I will definitely add a query string search and will look at doing what you do on your results page. Cool, so far, so good.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I didn’t much care about search when you said this, but using h0p3’s search and your directory and Pinboard—there’s no doubt that it’s useful. It warps you to a place in the collection that’s workable.
I’ve worked out a search index that’s entirely done in JavaScript—it’s the same one I’m now using on my blog. Thanks to TiddlyWiki for helping me realize that this could be a great way forward!
When I publish, it updates the search index. (Right now my blog’s search index is 300k. Raw text of my blog is 1.2 megs. The index is loaded when a search is performed and cached for further searches.) I haven’t decided where to place it in the directory yet.
In 20 years I’ll either be dead or so old I won’t care. My time horizon is a good 10 years, which is forever in Internet time and is part of why I’m doing this now rather than dithering. You are right this is a long term game.
Hah! I laughed when you wrote this and I might as well voice it now. See you in
ten years, brother. 
This is all good. The Indieweb folks are taking care of the social aspect, which is blogcentric sorta by definition. We can aid in discovery for the blogs and the non-blog sites. If there is to be an Independent Web X.0 somebody has to help map it.
I think one of my primary questions these days is: will the future be blogcentric? I feel like things are going to change. Although they could get more hyperactive. Thought streaming? Let’s hope not.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Normally I wouldn’t link to a large magazine, but this is relevant to the ‘hypertexting’ discussion.
My friend Nate first told me about this fellow—Karl Ove Knausgaard—who has become a substantial literary figure, which would normally qualify him to be ignored by me. Surely he has enough attention, what with every major magazine taking time out to heap praise on his work. Which bears striking similarity to h0p3’s wiki[1] and to my definition of Hypertexting—the creation of a massive ‘body’ of text, often as an avatar for one’s self. (I, too, am building a ‘body’ but I’m not sure that it’s of myself. No indictment to ‘self’ intended.)
Knausgaard’s six-volume My Struggle has concluded and so folks are internalizing it. In the book, the author attempts to lay bare every particle of his mind, life, relationships and—where do I stop?—it’s an autobiographical work that purports to leave nothing private (nothing? I haven’t started the first volume yet) and, so far, Oprah Winfrey hasn’t made him take anything back.
In violating prevailing standards of appropriate personal disclosure, “this novel has hurt everyone around me, it has hurt me, and in a few years, when they are old enough to read it, it will hurt my children,” he writes. “It has been an experiment,” he continues, "and it has failed because I have never even been close to saying what I really mean and describing what I have actually seen, but it is not valueless, at least not completely, for when describing the reality of an individual person, when attempting to be as honest as possible is considered immoral and scandalous, the force of the social dimension is visible and also the way it regulates and controls individuals.
I don’t know if this article is hyperbolizing the whole thing or what—I read around some other thoughts on the series and found other similar reactions.
From Literary Fundamentalism Forever:
At the end, in the last line, he says he’s no longer a writer, something he’s since disproven. But there’s something about this that’s like he’s put it all out, eviscerated himself and stretched the entrails out like Keroauc’s unfurled scroll along a shuffleboard table. He’s exhausted his capacities. And I’m sure that’s something that many writers have wanted to do at one point but never come close to achieving.
I’ve (and we’ve) been very busy having the meta-discussion about writing and cataloguing and relentless thought collection—we have kinship with this guy’s work. It might be that everyone is dealing with this, with the rise of an ‘automatic’ writing culture all around. I think the interesting thing that Knausguard offers is the moment of a ‘completion’. His six-volumes are up, but his life isn’t—and he’s gone on to write a four book cycle.
So, homework:
When can a ‘body’ be called done—what are the utilities of this moment, how do you see it coming?
For my own sake, I wonder how I might foment a reaction to the logorrheic approach that offers restraint—my Tuesdays and Fridays, for one—although I still end up feeling thoroughly logorrheic and I think I do exhaust anyone passing through. But: I feel to question this approach (hardly to demonize it) but what could a Reverse Knausguard ‘body’ style itself as?
What does the non-linear hypertext bring to the table?
For some reason, this work does help me really enjoy modern times.
Surely by now you know the link. And, anyway, after yesterday’s discussion of hypertext ‘entry points’, I’m not even sure how to appropriately link to h0p3. Go make your own doorway. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Cool—I am working on consolidating my bookmarks into a single directory (much like Brad has done at Indieseek.xyz, but it’s interesting to see you go with the approach of keeping links housed differently based on their purpose. It’s cool and your very thorough explanation is convincing!
I do like when people use Pinboard—and might consider double-posting there—mostly because I love that I can browse pinboard.com/t:toread to find interesting things. I keep looking for a common tag that means: ‘I don’t know what to think about this link.’
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘I didn’t really see it as being about anything…’
Man, I try to do interviews, but this is really good!
OL: Why and why in Heartland neighborhoods?
SS: Well, when I was thinking about putting a page on GeoCities there were various neighborhoods that were about specific things, and I didn’t really see it as being about anything, And Heartland seemed like sort of a friendly catch-all one, they called it the family neighborhood I think. So that seemed the best place for me.
I think there’s a temptation to call it ‘about nothing’ if it’s a page that’s not ‘about anything’. I love finding pages that just meander with no particular aim. Though it’s harder to name pages that are like that in the present.
OL: Let’s go though your home page. When I saw it for the first time it immediately attracted my attention, because you stroked through the Welcome to My Home Page
Welcome to My PageHere’s the Page
In the next sentence you explained that you strike it through because
“One of the books I looked at on how to code HTML said “Don’t put ‘Welcome to my page’ on your page”, because people already know they’re welcome, so I tried to think how to start this without putting that on first, and really, it seems sort of stark without some kind of greeting. So my second idea was just to say “Here’s the page”, as an homage to my seven-year-old son, who has started saying “Bon appetit” at mealtimes, and I discovered that he thought it meant “Here’s the food.”
This is such a sweet thing—and it reminds me that this sort of thing is still alive when people share the things kids say or fragments of overheard conversation and there is no stigma around those things. But I think there was some backlash against LiveJournal and the initial ‘meaningless’ Twitter status updates—but perhaps Susan was able to do this artfully. (I genuinely think her page is still great to read. It reminds me of a blog called Murrmurrs that I came across recently that I have been enjoying for similar reasons.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A discussion of portals into a large hypertext.
Ok, this is rich—this point is on fire. We agree, yeah, oh hell yeah we agree. This is what I’m saying every third paragraph about how our technology is underutilized. This is a great example of the ‘social’ overemphasis of the single ‘post’ or ‘link’ or ‘article’ as opposed to the hypertext ‘body’.
(For anyone just joining this conversation, h0p3’s link in the quote above loads about 10 pieces of hypertext that represent his current ‘place’ in this massive [20 megabyte] ‘body’ he’s creating—so the ‘link’ he’s sent doesn’t represent a single ‘article’ or ‘tweet’, which is what we’re trained to think of a ‘link’ representing. And I wonder—beyond h0p3’s twenty megs—how can I ‘link’ to the ten related tabs I might have open so that you can see them together? How can you create your own ‘link’ that puts me into the center of a hypertext perspective you have?)
(In some ways, this reminds me of heavily cross-referenced and footnoted texts like religious scripture—which are hyperlinked in a fashion—and folks have long batched together references to these works through verse-chapter or page citations, and most often through quotes. The amazing feature of the link above is that it isn’t just a set of quotes—it is the definitive source material, connected to the live author. Is it possible that citation could be improved by allowing one to construct a link of views to many definitive hypertexts?)
I won’t even touch Reddit [and it’s spidering onto the rest of the web] without half a dozen tweaks and tools; it’s not worth my time.
I like to say that all our problems are human problems at this point—but I think I am starting to see that every site needs good search, some kind of indexing and a way of positioning it within the whole landscape outside of it. I wonder what tools you find most useful—are they just useful within Reddit or should they be available to you and I somehow?
I grant, however, that some methods are better than others. What counts as finding relevance in our hyperreading in general is some ridiculously hard problem. It’s probably fair to say most people will quickly run out of things they find worth reading on this wiki (if they found anything).
Yeah, I think if we start to get too ‘hyper’ we get lost in the linkage and things get blurry. I mean when it comes down to it, I just want to do some very basic things: meet people, connect thoughts, really dig into a concept, see neat things—and try to route around the armchair arrogance that seems to be plaguing the world.
I don’t plan to read your whole wiki—I plan to use it to research your takes as we correspond and to consult it while I’m studying, to see what other directions I can go. (I wonder if you’ll agree with this:) I think the point isn’t to make your wiki the Penn Station of philosophy—I just think some valuable things will bubble up out of your project that will connect to Penn Station bidirectionally. Just like I might draw from Vigoleis or Dr. Strangelove from time to time—philosopher.life is in there, too.
I’m not sure if I can say that they are manipulating the feed.
Manipulators treat the minds of others as mere means; they do not respect your dignity. Satya Nadella is a manipulator. Does that mean he and cabal of powerful deep state actors have conspired to control every little detail of your mind? No. But, the science of rhetoric, mass manipulation, and our ability as a species to produce increasingly effective apex predators only continues to rise. Power centralizes at any cost, including moral ones.
I guess I try to manipulate the feed, too, so yeah, of course he’s manipulating the feed. Why I’m reluctant to just pin the award on him: I’m not sure he’s actually accomplishing what he claims to be. I love that he’s put all of this work into influencing Hacker News, but his boasting about it could clearly undo all that work—so what kind of master manipulator are we really dealing with here?
The short-term efforts undermine the long-term—his infrastructure is not nearly as sound as it seems.
What are games except for sets of rules we play by to win?
Yeah, man, good questions. I think the trolls are way ahead in this effort—I think they see that they can create games that are honeypots. And I do think that the Internet still holds the power to flip the structure so that it is the powerful who get caught in these games that they think they can play. (Thus, the meme warfare centers.) I think the trouble is that trolls are chaotic and can align anyway they like—evil, neutral and good—are even ‘neutral’ and ‘good’ more likely to turn out to be ‘evil’ than vice versa? On the other hand, chaotics have been the Robin Hoods, the Guy Fawkeses, the Snowdens perhaps. I think we benefit by tapping into that subversive light-heartedness.
As you point out, we are still going to need a standard for when we define something as cooperating. If I respond to your letters with one word answers, I’m offering a token. You cannot escape measuring reality to some very large extent. I think this is part of our plight. Yet, the goal is to not be overly quantitative (where, unfortunately, “overly” is quantitative).
Oh—I like your arguments, answers and agreements on the T42T outlines. I think this also goes in with my thoughts on what I called ‘pluralism’ (but which really just means ‘a multimodal system of thinking’)—just as one needs to both ‘quantify’ and restrain from such a thing, just as one must respond in kind, respond with a token, respond with a tome (and never know precisely if one is doing it ‘right’)—it is always a constant balancing in a battle of extremes and competing ideals. Much like a relationship is a balance between what I am looking for and you are looking for.
So also I look at socialism and capitalism as arrows in my quiver; left and right as sides of myself more than two religions at war. This is overly simplistic—but so is T42T, it is a useful starting place for me. It is not the end, it is the curated entry point. It is the self-made doorway.
(The remainder of your letter—the part that essentially argues for staking a position—I am going to digest and figure out how to respond. I don’t have any problem with what you’re saying in a general sense; it is principled. I, personally, cannot get myself to ratchet down to anything concrete, for some reason. I think part of it is that I really do enjoy human beings—I am hard-staked against misanthropy—and that puts me in a really weird place wrt to modern culture and forming an alliance with a group rather than an individual. But if the mindset is totally bereft, then I am willing to abandon it.)
(As far as the TiddlyWiki loader: I am also waiting for more inspiration there. I think of that prototype as ‘chapter one’—I usually have to batch up ideas and code fragments in order to realize them. But glad it got the conversation going. I am thinking a lot about versioning—for example, can the timestamp also be part of the curated doorway that is the undercurrent of this exchange?)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I am very tied up trying to finish mine, but you’re doing a lot of good writing and I wish I was done so I we could be synced up on this.
I think the other question we need to ask is: how do we make a directory that’s not a directory? Like: is there a new kind of directory that is an evolution of the tried format? And I think the main point of pain is having to enter this giant catalog through a straw.
Just like Google is ‘entered into’ through a few search words—terms that rarely hit the mark and need to be gamed—could the directory widen the straw somehow? This is what is done by providing a hierarchy—but I also wonder if there are other novel forms. Like: say the directory changed day-by-day to suggest common categories or to show where I’ve been editing or to suggest a few categories.
I also wonder if a ‘pinned post’ might be useful: here are a few suggested categories, here’s one I added recently that’s kind of sweet, here are a few links that I’m considering throwing out.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, wow—yeah I actually did browse ‘The Griddle’ from Kottke’s list he put out. I am really into Cryptics and mazes, so we have a lot of crossover there. And, yeah, tacos, sure sure.
Your nostalgia post REALLY excites me, though. Your writings on these links are great and it seems like you’ve seen a lot of spots on the Web that I haven’t seen yet. Do you happen to have more of your links collected like this elsewhere?
As for your projects and sites, I like a lot of what you are doing and I will include you in my next installment of href hunt—thank you for poking your head out. Let me know if this reply is an okay way to reach you or what you prefer. Take care, David.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Pinboard and Indieweb.xyz as clustering tools.
Ok ok, one other thing that has dawned on me: it’s not just the emergent connections between writers that is salient when clustering. It’s the connections between readers as well! (This is one thing that Google cannot possibly capture.)
To akaKenSmith’s point:
Having found each other, kindred parties need a work space where they can develop shared understandings.
The old Delicious was this kind of workspace for readers - a similar effort can be found in Pinboard.
One interesting thing I like to do with Pinboard is to look up a link - say ‘The Zymoglyphic Musem’ (results here) and then look at the other bookmarks for those who found the link. For example, the user PistachioRoux.
All of those links are now related to ‘The Zymoglyphic Museum’ by virtue of being in the realm of interest of PistachioRoux. YouTube uses these sorts of algorithms to find related videos by matching your realms of interest with someone else’s. However, in the process, that person is removed. (Or ‘those people’, more appropriately.) PistachioRoux is removed.
But perhaps PistachioRoux is the most interesting part of the discovery.
Particularly in a world which is becoming dominated by writers rather than readers - maybe the discovery of valuable readers is part of this.
Say a post tagged with #how_to #mk #fix_stabs could be crawled and collected into a single mechanical keyboard maintenance page. All that really calls for is emergent keywords from communities and tagging posts which bloggers can do and automations can assists with.
This does sound a lot like Indieweb.xyz, as @jgmac1106 mentioned. The concept is simple:
So the emergence should come from blogs clustering around a given URL.
I’ve been wondering if they could do a similar thing with http://www.adfreeblog.org/ - a ‘general’ blog community could be established around a simple ideal like that.
Might look like this:
The adfreeblog.org home page then becomes a directory of the community. So, kind of like a webring, but actually organized. With Twitter cards and such floating in the metadata, it is probably much easier to extrapolate a good directory entry.
Spam is an issue with this approach - but it’s a start toward discovery. There aren’t a whole lot of ways for a blog to jump out from the aether and say, “I’m over here - blogging about keyboards too!” And, in a way, the efforts to squash abuse and harassment are making it more difficult.
This can become an important component in the new discovery system like how awesome-blahblah github repos are playing a key role in open source discovery.
I think it’s important to point out, though, that ‘awesome’ directories are intended to be human-curated, not generative. They feel like a modern incarnation of the old ‘expert’ pages.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Mild automation alongside hypertexting in the Indieweb.
Oh yes—I quite agree! I didn’t when I started this blog—I was pretty burned out on algorithms. But I’ve calmed down and, yeah, I think your word of ‘automation’ is more friendly to me than ‘algorithm’.
I’m really getting a lot of good stuff out of Pinboard—it is better than Google, DDG, Million Short or any directory at finding interesting stuff. And it is due to its balance between machine and human: the humans find the link and tag it; the machine collates everything for the researcher. You can do pretty complex queries with it, which I am using every day now. (As an example: /u:krudd/t:links/t:web shows me all links tagged ‘web’ and ‘links’ under the user ‘krudd’.)
However, it is still totally underutilized. I would be surprised if there were five other people on the Earth mining it like I am. (This wasn’t true of the old Delicious—it was a golden age for this kind of mining of bookmarks.)
One great thing to automate would be Webmentions for Pinboard. Think of it: when you (Brad) mention me, I put a link to you at the bottom of that page. You are another writer, so if someone likes your comment, they can visit you to see more of your writings.
But if I had Webmentions from Pinboard, you could go to the bottom of my page and see what readers are mentioning my page. And those readers can be visited—not to see what they are writing, but to see what else they are reading. There is a temptation to remove the reader’s name and just inline their relevant links at the bottom of my post. But I think that removing the human possibly destroys the most valuable piece of information.
I’m beginning to think single author wiki’s are way under utilized. Blogs are cool but relentless about pushing down older posts.
I’m starting to categorize the ‘blogging’ and ‘wiki-ing’ actions under the superset called ‘hypertexting’. Both are about simply writing hypertexts, but blogs arrange those texts in a linear summary and wikis arrange them as a web which starts from a single entry point. (And a self-contained hypertext book or directory would be a tree.)
I think that if we could retreat to mere ‘hypertexting’ and then give people a choice of entry points, we could marry the ephemeral and the permanent and do exciting things with the entire body of the ‘hypertext’. This is where my blog is moving toward and it’s obviously inspired by h0p3’s system and the Indieweb as a whole.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Brad’s directory is coming together!
Boy oh boy—this is great! So you have done a great job writing descriptions, trimming the list down to your essential set and coming up with a good category structure and all that. (And I mean: who am I to tell you this—you’re the directorymeister around here.)
I wish that /links was the home page. I like being right in the middle of things and that page has tons of useful information. However, I can see why you’d want to take the Google approach.
I also wonder about starring things. I like that it’s an invitation to participate. (As are ‘commenting’ and ‘reporting’.) I’ve left this kind of stuff out of my directory, in part because I’d rather that they create their own directories if they disagree. I think ‘reporting’ is a really cool idea—I can see the value there, possibly. With starring: how valuable has this kind of feature been to you in the past?
I really like that you’ve highlighted categories like ‘Fiction’ and ‘City Planning’—in a massive directory, these would be deeply buried, but they are key to your experience on the Web, so they are near the top. This is a really cool advantage to a smaller directory: finding niches that aren’t ever nearby—except here.
I think, at this point, you will learn what works and what doesn’t. I’m going to browse around and announce this on my site soon once I have a chance to take it in completely. Man—this is so fun!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A corporeal directory to another world.
In my travels about the hypertext kingdom, I happened upon a rare portal[1] to a so-called ‘Zymoglyphic’ world—islands of Earth ‘formed by the upwelling of molten magma from the underworld.’
I had not ever known of the creatures of this land! We talk of museums, libraries, cataloging and labeling here, do we not? Therefore, I awkwardly flailed out in my typical shock-curiosity to Jim Stewart—the Museum’s curator.
kicks: I recently discovered an interesting local museum a few blocks from my neighborhood after being unaware of it for five years. I drove behind it all the time and would have immediately spotted it had I driven on the other, parallel street. It took me five years to drive on that other, parallel street.
So what are your visitors like? Unsuspecting tourists? Neighbors that happen to drive by? Pilgrims?
jim: All of the above. Probably the majority of visitors are tourists and locals looking for “offbeat” things to see and do.[2] Some are specifically interested in personal museums, natural history, curiosity cabinets, or a rust-and-dust aesthetic. I do get a fair share of people just passing by as well and have met a lot of neighbors this way.
kicks: So, did you have any idea in mind of who you were looking for when you started the museum or were you just glad to have anyone and everyone?
jim: At first I was just doing it for myself, then when I went public I was happy to have anyone appreciate it. Nowadays (after 2000 visitors) I’m mostly looking for the people interested in a more in-depth connection with the museum.
kicks: I love the guide[3] you have, advice for curating your own museum. In a way, I took it as advice for the blog-hunting I do. You even have a section on ‘outreach’—I have a little group of online friends where we call this ‘find the others’—the pejorative word here might be ‘self-promotion’—to what degree do you engage in this kind of thing for the Zymoglyphic?
jim: Very little at his point. The blog has not seen an entry in years and the twitter account is inactive. Events are announced on Facebook and I have a mailing list that gets used 3 or 4 times a year. People who visit leave reviews on review sites and photos on Instagram, and I am on a lot of “quirky things to do in Portland” lists. The place is small and can’t really accommodate many people. Also, I think the fact that this is a physical place and not just an online presence puts it in a category that generates its own publicity.
kicks: Perhaps the museum is ‘complete’ and has no need of updates? Or is it in constant flux—are you always cooking up new exhibits?
jim: The basic format seems pretty stable. I’m working on a lot of different but related projects, such as a library and computer-generated aquarium.
kicks: You also have this profound quote in the book: “Once the museum is complete, it could become a private sanctuary for contemplation, since the museum will be like being inside your own subconscious mind.” This reminds me of the work at philosopher.life—where a fellow is cataloging his life and correspondence in a huge singular oracular HTML file. So when someone visits, are they able to absorb you through this portal—almost as if it is a stand-in for you—or is it as mysterious to you as it is to them?
jim: Very hard to say exactly what other people get out of it. Many are quite enthusiastic I think mostly they are finding something in themselves that they had not been able to express in just that way. I know from personal experience that it is possible to get a lot out of a work of art and not be able to relate to the artist as a person.
kicks: Haha, I love the idea that someone could relate more to the
Zymoglyphic Mermaid[4] than to you.  Well—and you say on the website that you
like to give the visitors their space to peruse and not be badgered or guided
through. (Have I got that right?) Does it matter to you what the effect of the
museum would be on somebody?
Well—and you say on the website that you
like to give the visitors their space to peruse and not be badgered or guided
through. (Have I got that right?) Does it matter to you what the effect of the
museum would be on somebody?
jim: Yes, the museum is on the second floor and I just send people up when they come in (even if they want a quick introduction). When they come back down is when I engage them about their reactions (if they seem open to it) and answer questions. I’m definitely interested in what their take on it is, and what it means to them. I keep track on the web site of all the reviews, blog mentions, etc. It’s especially meaningful if someone gets inspired to do something similar.
kicks: Having lived in towns with small museums, junk art houses, religious shrines—you have given your city and the world a great gift.
The Zymoglyphic Museum. ‘The Zymoglyphic Museum’s primary mission is the preservation of the unique natural and cultural heritage of the Zymoglyphic region. In addition, the museum hosts a variety of special collections and online exhibits related to zymoglyphic themes of natural art, celebration of decay, and museums as curiosity cabinets.’ ↩︎
Creating and Curating Your Own Personal Museum. Furthermore, the publications contains a myraid of other enchanting documents, such as the Museum’s Manifesto and A Guide to the Collections. All very worth your time. ↩︎
‘Somewhat of a spokesmodel for the museum […] its sinuous body and delightful smile grace the museum shop’s drinkware, clocks, and clothing.’ More. (See also: Jenny Haniver.) ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
It’s constant work—finding each other through the noise.
Hi, folks - just jumping in because this is my wheel house a bit. I have been having an extended discussion with Brad Enslen (so, on our blogs: ramblinggit.com and kickscondor.com) about discovery. We talk a lot about how this is more of a human problem than a technology problem - and that technology has played a negative role in this, perhaps.
(My part in this is: I have been spending time every day for the past six months searching for blogs - to see what the Web looks like outside of social networks. So I have a good perspective on where one can search nowadays - you can’t just type ‘blogs’ into Google. And I’m starting to get a good feel for where I would want to go to find blogs.)
blogrolls didn’t scale. ring blogs just sucked. SEO is just survival-of-the-fittest money pit.
Yes, so - for sure. (See Brad’s comment on Google here.)
In addition, self-promotion has become a dirtier word these days - you can’t just post your blog to Reddit and Instagram - it’s seen as being overly assertive. So there is almost nowhere for blogs to go.
The thing is: no, blogrolls didn’t scale - but I think they are pretty essential. We’ve traded a human-curated list of links for a ‘friends’ list that is really just a number on an individual’s feed. And the best blogrolls had nice descriptions of who was who (see: Chris Aldrich’s following page as a good example) which is a generous way of turning your readers on to other good work.
I guess I just think of it practically: how would we treat our friends and the other ‘writers’/‘artists’ we admire - by making them a number in our list? Or by spelling it out: “Annie writes about her processes as a sci-fi writer and how to improve online relationships. Basically - it’s uplifting to read her.”
Blog clusters are emergent. Fake or not, blogs with posts on similar topics will be mapped to same cluster which can be seen as a place in which a blog belongs to. Once we have that, a blog reader should be able to ‘pop out’ of that blog and see some visual representation of that cluster with neighboring blogs, not unlike a shopper leaving a store will see a street lined with other shops. That’s how discovery is done IRL and I envision that may be possible online.
Sweet - feels practical. One question I have here is: ok, so blogs have also become more topic-based. The most common blogs are recipe blogs, movie blogs, etc. But a great ‘lost’ element of blogs was just the original web journal or meta blog, where a person is just writing about whatever - I think of stuff like the old J-Walk blog or Bifurcated Rivets. Even Boing Boing used to be more this way. (So like an online ‘zine’.)
I think the orderliness of the Internet and the systems for discovery - these blogs were not found through Google, but only because there was more of an ethic of linking to each other among early blogs. A lot of discovery was just being done by bloggers back then - people simply passed links around.
Again, ‘likes’ have drained linking of a lot of its bite. We don’t write so much about why we like something - we like it and move on. And it’s so easy to ‘like’, it is done so vigorously that even we can’t keep up with our own likes - whereas we used to be limited by how much energy we would spend dressing up our links.
I’m with Don on this – whatever is going to have a chance to work has to be emergent, meaning it can’t require any investment on the part of writers.
I think ‘emergent’ can require work - in fact, it might demand work. Yes, too much work will dissuade anyone. But if it’s too easy, then it’s virtually worthless. I think the value of human curation is in its additional care.
An algorithm cannot simulate the care. Chris’ blogroll linked above is done with care - a human can plainly see that another human has taken the time to write about others. And the more time he spends designing it and improving it, the more it shows that care. People can visit my blog and see that it is built with care. (To me ‘care’ can be represented by thoughtful writing and splendid artistry or shaping of the information.)
Ok - sorry to go on so long, I hope you see this as my effort to generously engage in your discussion.
The effort Brad and I are now engaged in is an effort to bring back the link directory and to attempt to innovate it based on what we’ve learned. (Link directories have already evolved several times into: blogrolls, wikis, link blogs, even the App Store’s new ‘magazine’ approach, etc.) The idea is to jump right into discovery and link up with anyone else who wants to get in on it. Thus, my reply today!
Good to meet you all - take care.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.





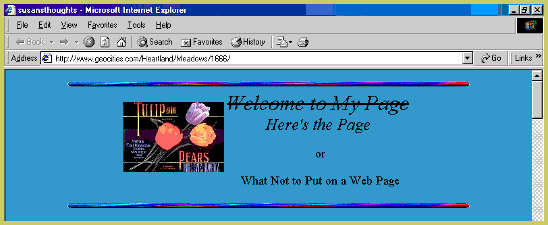


Reply: Link to a Kid?
Haha, well—“don’t do much”—first off, you have hundreds of wiki pages under your personal belt at this point… and I know damn well that you are one of the ghost-architects of h0p3’s wiki. You work on scripts and CSS for him—it’s all right there in the logs, j3d1h! For hell’s sake, you set up Windows 8 VMs for him!
I’m sorry that I know all this. I do apologize. I am just a random guy.[1] And I have no idea how to offer you any advice or suggestions as to your wiki—I like that you are just doing your own thing, you seem perfectly capable to me, of writing your own thoughts and following some of your dad’s practices—and establishing some of your own.
I just h0p3 it is encouraging that you have a reader out there who thinks your Social Studies Log is awesome—as a window into your young reactions to history. Or your Deep Reading Log—since I am an avid reader and your words remind me of what it was to read The Chosen at your age—which I probably did! (Although I can only guess at your age and am very impressed at the things you say to h0p3 which he quotes—your words strike like a queen’s sceptre of supreme sarcasm[2]!)
But I do wonder why you write. In a way, I don’t wonder—to be young is to explore so avidly—I am sure that your writing is so exciting to you, is it?? Do you keep your logs so that you don’t forget? Or so that we might know you? I don’t know that I can answer these questions for myself; maybe you can, though.
Please write me any time. Oh and your Python scripts are looking good.
Oh, in fact, recently, I went to a formal event for a friend—the friend was getting ‘inducted’ and there was a small group there. All the people at this event knew each other—but I just kind of float around the area, so I didn’t really know anyone.
My friend hadn’t arrived yet. So when I walked in, people kind of stopped talking and laughing—and there was just a moment of unease. I said, “Oh, I know R—I’m just a random guy who knows R. Sorry to interrupt.”
One of the people then said, “I’ve seen you around. You are a random guy.”
“Yes,” someone else said, “That’s the perfect description. You are a ‘random guy’!”
And so now when I see these people, I am the “random guy” to them and I somehow find it very endearing—just to be a kind of anonymous everyman placeholder—a person who can’t be explained, perhaps. And I hope that you, too, j3d1h, will think of me as the “random guy” who reads your wiki. There can simply be no explanation for this. ↩︎
And yet, I know assuredly that you love him very much too. ↩︎