03 Apr 2019
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.


This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

this is a very messy and unstructured inpsiring personal site no actualy it’s more of a collection of txts and links and sometimes it uses html other times it just uses a basoc json file no it’s a blog this person is also on other sites but i’m not going to tell you where becau i have just bought a lettuce form a door to door saleswoman tell me you wouldn’t focus on that if you were it too
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Raw blog/website links to look through.
I’ve stumbled across the link above (a list of personal portfolios compiled by Martin Pitt) and, well, this has been a bit of a recent trend:
A Twitter thread by Jon Kuperman, looking for personal blogs (particularly personal “tech” blogs.)
An ‘awesome’ directory combed from the above thread.
‘awesome-lite-websites’—might as well add this.
I am not going to look through the tech blogs, because I’m not as interested in those. (Except ones like ameyama.com which blends a greater portion of assorted personal thoughts alongside the tech tutorial-type things.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Idea: gang up to cache classic websites.
This is just a zygotic bit of a thought that I’ve been having. A group that would band together to share classic websites (likely on the ‘dat’ network), perhaps as if they were abandonware or out-of-print books. Many of the early net.art sites have been kept up because they have university support; many other sites disappear and simply don’t function on The Internet Archive.
(To illustrate how even a major art piece can go down, Pharrell’s 24 Hours of Happy interactive music video—yeah. that link is broken. You can see kind of see it on YouTube, but… the hypertext enthusiast in me wants to see it live on in its original form.)
Some sites that I really need to reconstruct:
Room of 1,000 Snakes. This game hasn’t been playable for a year or two now. I promised a friend I would work on this. (This is an issue with Unity Web Player going defunct.)
The Woodcutter. Careful, redirects. This site was a huge deal for me when I was younger. When I started href.cool, it was fine—and had been fine for like fifteen years!—and then it suddenly broke. I think it can be reconstructed from The Internet Archive.
Fly Guy. Moved to the App Store??
SARDINE MAGOZINE. Charlie is gone now—so I’ve already started doing this.
SMASH TV. This suddenly disappeared recently, but I think it’s been restored to YouTube now—I need my copies.
Sites I need to back up; feels like their day is nigh:
1080plus. I’ve already been through losing this once.
Bear Stearns Bravo. Yeah, I think so. (This Is My Milwaukee could be recreated too.)
“Like a Rolling Stone.” Similar story to “24 Hours of Happy”—this kind of disappears for months at a time, but seems to work as of March 2019.
Frog Fractions. This one is probably too adored to disappear—still.
Everything in my Real/Person category. These personal pages can easily float away suddenly.
Of course, I’d love to get the point where I have a cached copy of everything at href.cool—there are several Tumblrs in there and Blogspots. I’m not as worried with those, because The Internet Archive does a fine job of keeping them relatively intact. But if a YouTube channel disappears, it’s gone to us.
Along similar lines, I have been trying to message the creators of the Byte app—not the hyped Vine 2, but the original Byte that was basically like an underground vaporwave social network from 2014-2016. I want to secure a dump of the public Bytes from that era. It was sick.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Some notes on how I am using crawlers as I’m collecting links.
I’ve started dabbling in crawlers with two simple prototypes—these may not even be considered crawlers, but simple web fetchers or something like that—but I think of them as being (or becoming) fill crawlers. Most crawlers are out exploring the Web, discovering material and often categorizing them, given some kind of algorithm that determines relevancy. Here, I’m the one discovering and categorizing; the fill crawler only does the work of watching those pages, keeping me aware of other possibly relevant sites and notifying me when I need to update that link.
So, these crawlers are filling in the blanks for certain links. Filling in missing parts that aren’t editorial. This isn’t a crawler that is feeding the site’s visitors—it’s there for my utility.
For href.cool, the crawler isn’t really a crawler, given that it doesn’t do any exploring yet. It just updates screenshots, lets me know when links are broken and tracks changes over time. Eventually, I hope that it will keep snapshots of some of those pages and help me find neighboring links.
Anyway, I’ve had that crawler since the beginning and it will stay rather limited since it’s for personal use.
For indieweb.xyz, I’ve started a crawler that’s also for keeping the links updated. Yeah, I want to know when something is 404 and keep the comment counts updated. But I also want to get better comment counts by spidering out to see the links that are in the chain. This crawler allows indieweb.xyz to stay updated even if Webmentions don’t continue to come in from that link.
I think the thing that excites me the most about this crawler is that I’d like it to start understanding hypertext beyond the Indieweb. I’m hoping it can begin to index TiddlyWikis or dat:// links, so that they can participate. I’d really like TiddlyWiki users to have more options to broadcast that doesn’t require plugins or much effort—they should remain focused on writing.
Both of these projects are focused on trying to help the remaining denizens of straight-up Web hypertext find each other, without it functioning like another social network that becomes the center of attention. To me, rather than giving the crawler the power to filter and sort all these writings, it simply acts as a voracious reader that looks for key signifier that all of normal readers/linkers are looking for anyway. (Such as links in a comment chain or tags that reveal categories.)
That’s all I have to say at the moment. I mostly put this out here so that people out there will know how these sites work—and to connect with other people (like Brad Enslen and Joe Jennett) who are doing cataloging work, to keep that discussion going.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
(Joe’s full article is here.)
Yes, here we are again—I think what you’re saying is that even a single-line annotation of a link, even just a few words of human curation do wonders when you’re out discovering the world. (Perhaps even more than book recommendations—where we know that at least we can rely on certain publishers and editors to vet their publications—I’m a big fan of the Dalkey Archive[1], for instance—but we have no idea the quality of writings out on the Internet at large and are desperately reliant on these annotations in the field.)
Pinboard is doing everything right in that regard—of course, it cribs from Delicious before it—giving hyperlinkers an appropriate amount of meta-dressing to put around their link: tags, description, search tools. However, it misses out on the kind of visual styling and layouts that you, Joe, get to enjoy. (I really like how you batch up links for the day, similar to how h0p3 does it.)
I think another of my lingering questions is: what are we really doing here? When I look at h0p3’s links, he’s trying to catalog his discoveries for the day completely—at least, I don’t think he edits this list. You also mention in your essay that you ‘curate links for my own ongoing use’. Whereas I tend to ‘advertise’ links more, to bring attention to the parts of the web that I want to survive.
So it’s more natural for me to work towards a final directory of links, a hub of all the nodes that I want to see connected. I want these individuals to be aware of each other. I see your Linkport as being a type of directory; I wonder to what extent you are doing this as well—and I wonder what kinds of collaborations we could get going between our directories. You do say that ‘people finding me and finding some of my links enjoyable’ is a secondary goal. I guess another angle I keep alluding to is the benefit you give to the authors behind the links you’re publishing—this type of work is a tremendous gift to them.
Along these lines: I see link duplication as being an interesting thing—clearly we don’t all just want the same links, but I think it will be interesting to see how much overlap there is. I also really like, for example, when David Crawshaw’s article last week got linked by h0p3, Brad, Eli, other microbloggers—it made me feel like we were trying to send some kind of concentrated transmission to the author—linking as a greeting, links as an invitation.
With time, many personal sites and blogs disappeared from the web as people flocked to the big silos where their content became a heavily monitized commodity. To me, the web had lost much of its soul as people gathered in just a few, huge noise chambers. […]
Current trends and a rebirth of personal blogging certainly make the type of curation I do much easier, thank you. Had it not been for that stimulating conversation, I probably would not have been writing this.
It’s interesting to me that the corpypastas had this kind of effect. Because they actually eased publishing and participation for so many people. Facebook is a type of gated community—so I see why it had this kind of effect. But it’s interesting that Twitter and Instagram also dampened the growth of the web. I hazard that perhaps this was simply because their game was best played by their rules—an external link to Twitter wouldn’t show up in your ‘likes’ whereas a like from another tweet was fully realized by the author and the… err… liker.
And I don’t want to chalk this up to mere ego—the author and the liker could see each other from across the Internet. And that is valuable. This is also what micro.blog is assisting us with—we have our blogs, but it is a useful capsule pipeline, so that we can get to each other clearly. (This is why I’m not just linking to your blog post and waiting for you to notice somehow—this communication structure that we’re using here is very useful to us, even if I can almost guarantee that this post is going to be flattened into a massive paragraph by micro.blog. No problemo—I’m just glad to have a direct line to you, Joe!)
Regarding another thing Kicks asked about: Aside from evolving html, accessibility, and design standards and practices, I’m really not sure if linking, in general, has changed over the years. I’ve been doing it the same since day one. But that’s just me.
For me, I do find that Webmentions are really enhancing linking—by offering a type of bidirectional hyperlink. I think if they could see widespread use, we’d see a Renaissance of blogging on the Web. Webmentions are just so versatile—you can use them to commment, you an form ad-hoc directories with them, you can identify yourself to a wider community. I really feel like they are a useful modernization.
But I like that you are true to the linking you’ve always done. It still works. It’s an ideal that we fell away from I guess.
The Third Policeman, of course! But also: Heartsnatcher by Boris Vian (just my kind of meandering, vexing thing), Writers by Antoine Volodine. And soon I will get into Impressions of Africa by Raymond Roussel. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A self-catalog—tho this format could fly as an outgoing directory.
I mostly cover obscure writers. James is a widely published author (The Atlantic, Playboy, Aeon) but this is a neat personal directory to his writing—very homespun and lightly annotated, with asterisks and highlighting used to nice effect.
Articles such as How I Reverse Engineered Google Docs To Play Back Any Document’s Keystrokes are a festive hybrid of code, anecdote and sundry links—found in paragraphs festooned with blue underlines that act like surprising miniature directories nested in the article. (This is an approach that I feel I need to cover in Foundations of a Tiny Directory.)
I also think it’s interesting that he catalogs all of his individual blog entries. This whole page very much fits in with my definition of Hypertexting—these scattered essays and posts become a body of work here. And the quality is excellent: generally well-considered and well-executed.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Wow, you hand-check the whole thing?? Ok, wow, so if you don’t mind I have a few more questions—actually, quite a few more, but I’ll constrain myself!
Also, if you’d rather post your answers as a blog post, I can link to that. Great to meet you—I’m immediately a huge fan!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Hot takes aside, I thought Universe was a pretty neat tool when I last looked at it. These kinds of things can have really poor money strategies and still have novel ideas inside.
So, yeah, I thought the editor was a nice, simple tool for building little web pages with blocks of text and pictures. I’m planning to use it for a project at the elementary school to see how the kids use it. (This seems like the rare technology that has enough color and expressiveness to be useful to me there—especially now that Byte is defunct.)
If we can learn from the good tools, they can help us figure out how to craft the Indieweb. We will need more than just protocols.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Part one of thirty-five.
Sweet letter—I’m going to dig into this further over the next while, I’m going not to say much here, because h0p3 has many things to do and I don’t want there to be any timer started just yet, in fact, let’s suppose that I’ve already written a very lengthy reply, but am just sitting on it, to let the wide variety of worthwhile non-hyperconversation things transpire. Just want to mop a few fallen fruits off the floor.
TW defeats a number of frictions like a champion. I posit that TW is radically more decentralization-capable than Dat. Legions of analog and digital systems can move one file, but it is possible only few will speak Dat.
Oh, for sure—its resilience is proven. I side with TiddlyWiki in the long-term, no doubt. In fact, I am siding with its powers of adaptation. It runs on Node, it runs on Beaker—let’s push that adaptation further. (Perhaps this means that Dat is less resilient and will fall—but I think the protocol has to be narrow/simple to see widespread use.)
My money is on WASM-Web 3.0 taking further down that rabbithole.
I’m great with this, so long as we don’t lose hypertext in the process.
To my eyes, Dat is competing with IPFS, Syncthing, Resilio Sync, mutable torrents, etc. For now, I just use Resilio Sync for the functional Dat-properties I need.
Try to keep in mind that it’s not even Dat that excites me about Beaker. It’s that you can read-write entire locally synced folders from the same languages ‘for which every computer has a virtual machine’. With Beaker, I can make an editable copy of your wiki—even if it was split into tiddlers, even if it was in a thousand pieces.
This is clearly an innovation that we follow. Take the rock-solid v.machine and let it create, babe.
I’m a P2P idealist who agrees there are classes of problems which can only efficiently be federated.
Mmmm, yes—same here. One of my fave networks was Soulseek. You could connect to people and see all the files they were sharing. I ended up just raiding people’s shelves rather than trying to track down Pavement b-sides. But that required some kind of cohesive network where you can ‘see’ everyone.
Wowowow-it’s still there! Just installed. There is a lot of good stuff still on here. How has it stayed so obscure and devout?
A starting place for the opposite style seems like poetry or crystallized summation. It only shows semblances, outlines, glimpses, fragments, and impressions on purpose. I think it must be antipleonasmic.
Yeah, this is a sweet letter. I hope there’s a worthy reply somewhere in my timeline.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A directory of ‘federated’ communities.
A list of all of the various blogging and messaging services that are connected to each other by way of ‘federation’ (e.g. Mastodon). This is impressive—user statistics and lists of smaller communities within each group. I’ve thought that the Indieweb was ‘ahead’ of the Fediverse, but it’s much easier to find each other with this kind of centralized directory.
I also generally advocate human-curated directories. But, in the case of examining the offerings of a network, this kind of entirely machine-constructed catalog makes perfect sense. A stat-based and rather spreadsheet-like view is the whole point.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
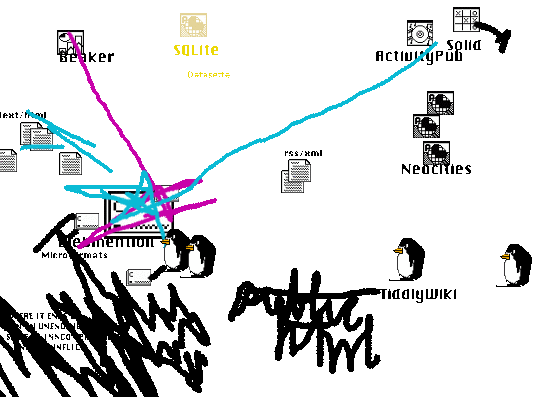
Will your .pizza domain survive?
Beaker vs TiddlyWiki. ActivityPub against Webmentions. Plain HTML hates them all.
I step back and, man, all the burgeoning technology out there is at complete odds with the other! Let’s do a run down. I’m not just doing this to stir up your sensibilities. Part of it is that I am lost in all of this stuff and need to sort my socks.
(I realize I’m doing a lot of ‘versus’ stuff below—but I don’t mean to be critical or adversarial. The point is to examine the frictions.)
At face value, Beaker[1] is great for TiddlyWiki[2]: you can have this browser that can save to your computer directly—so you can read and write your wiki all day, kid! And it syncs, it syncs.
No, it doesn’t let you write from different places yet—so you can’t really use it—but hopefully I’ll have to come back and change these words soon enough—it’s almost there?

Big problem, though: Beaker (Dat[3]) doesn’t store differences. And TiddlyWiki is one big file. So every time you save, it keeps the old one saved and the network starts to fill with these old copies. And you can easily have a 10 meg wiki—you get a hundred days of edits under your belt and you’ve created some trouble for yourself.
Beaker is great for your basic blog or smattering of pages. It remains to be seen how this would be solved: differencing? Breaking up TiddlyWiki? Storing in JSON? Or do I just regenerate a new hash, a new Dat every time I publish? And use the hostname rather than the hash. I don’t know if that messes with the whole thing too much.
Where I Lean: I think I side with Beaker here. TiddlyWiki is made for browsers that haven’t focused on writing. But if it could be tailored to Beaker—to save in individual files—a Dat website already acts like a giant file, like a ZIP file. And I think it makes more sense to keep these files together inside a Dat rather than using HTML as the filesystem.
While we’re here, I’ve been dabbling with Datasette[4] as a possible inductee into the tultywits and I could see more sites being done this way. A mutation of Datasette that appeals to me is: a static HTML site that stores all its data in a single file database—the incomparable SQLite.
I could see this blog done out like that: I access the database from Beaker and add posts. Then it gets synced to you and the site just loads everything straight from your synced database, stored in that single file.
But yeah: single file, gets bigger and bigger. (Interesting that TorrentNet is a network built on BitTorrent and SQLite.) I know Dat (Hypercore) deals in chunks. Are chunks updated individually or is the whole file replaced? I just can’t find it.
Where I Lean: I don’t know yet! Need to find a good database to use inside a ‘dat’ and which functions well with Beaker (today).
Ok, talk about hot friction—Beaker sites require no server, so the dream is to package your raw posts with your site and use JavaScript to display it all. This prevents you from having HTML copies of things everywhere—you update a post and your index.html gets updated, tag pages get updated, monthly archives, etc.
And TiddlyWiki is all JavaScript. Internal dynamism vs Indieweb’s external dynamism.

But the Indieweb craves static HTML—full of microformats. There’s just no other way about it.
Where I Lean: This is tough! If I want to participate in the Indieweb, I need static HTML. So I think I will output minimal HTML for all the posts and the home page. The rest can be JavaScript. So—not too bad?
ActivityPub seems to want everything to be dynamic. I saw this comment by one of the main Mastodon developers:
I do not plan on supporting Atom feeds that don’t have Webfinger and Salmon (i.e. non-interactive, non-user feeds.)
This seems like a devotion to ‘social’, right?
I’ve been wrestling with trying to get this blog hooked up to Mastodon—just out of curiosity. But I gave up. What’s the point? Anyone can use a web browser to get here. Well, yeah, I would like to communicate with everyone using their chosen home base.
ActivityPub and Beaker are almost diametrically opposed it seems.
Where I Lean: Retreat from ActivityPub. I am hard-staked to Static: the Gathering. (‘Bridgy Fed’[5] is a possible answer—but subscribing to @[email protected] doesn’t seem to work quite yet.)

It feels like ActivityPub is pushing itself further away with such an immense protocol. Maybe it’s like Andre Staltz recently told me about Secure Scuttlebutt:
[…] ideally we want SSB to be a decentralized invite-only networks, so that someone has to pull you into their social circles, or you pull in others into yours. It has upsides and downsides, but we think it more naturally corresponds to relationships outside tech.
Ok, so, perhaps building so-called ‘walled gardens’—Andre says, “isolated islands of SSB networks”—is just the modern order. (Secure Scuttlebutt is furthered obscured by simply not being accessible through any web browser I know of; there are mobile apps.)
This feels more like a head-to-head, except that ‘Bridgy Fed’[5:1] is working to connect the two. These two both are:
I think the funny thing here goes back to ‘Fed Bridgy’: the Indieweb/Webmention crowd is really making an effort to bridge the protocols. This is very amusing to me because the Webmention can be entirely described in a few paragraphs—so why are we using anything else at this point?
But the Webmention crowd now seems to have enough time on its hands that it’s now connecting Twitter, Github, anonymous comments, Mastodon, micro.blog to its lingua franca. So what I don’t understand is—why not just speak French? ActivityPub falls back to OStatus. What gives?
Beaker Browser. A decentralized Web browser. You share your website on the network and everyone can seed it. ↩︎
TiddlyWiki. A wiki that is a single HTML page. It can be edited in Firefox and Google, then saved back to a single file. ↩︎
Beaker uses the Dat protocol rather than the Web (HTTP). A ‘dat’ is simply a zip file of your website than can be shared and that keeps its file history around. ↩︎
Datasette. If you have a database of data you want to share, Datasette will automatically generate a website for it. ↩︎
fed.brid.gy. A site for replying to Mastodon from your Indieweb site. ↩︎ ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A religious satire crossed with a home page. This is also covered in this episode of a show called Deep Web Browsing. Just linking this in case I want to follow the trail further.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Indices, catalogs and maps of the hypertext ‘body’.
I am discovering more and more of these—what I am calling ‘link maps’, perhaps there is another name—collections of links that act like an index or a topical guide to a large ‘body’ produced by Hypertexting. You might want to conflate these with wikis—most wikis do act like ‘link maps’—but I am specifically looking at a ‘link map’ and a ‘body’ as being seperate entities. Much like a map and the dungeon or landscape that it maps are separate.
A very similar word is ‘sitemap’—perhaps ‘external sitemap’ is a better term—but I tend to think of a ‘sitemap’ as a complete map, whereas a link map might be limited or contain duplicates (like an index). (For comparison, see the sitemap for Purdue’s writing guidelines or the SuperMemo sitemap as standard examples. Though, I’m not sure how these would differ from a ‘table of contents’. Or a ‘home page’—such as Paul Burgess’ home page, which is a directory to itself.)
Some of my collection:
The Mother Horse Eyes index, which maps the stories, background, chronology created by Reddit user _9MOTHER9HORSE9EYES9. (Reddit wikis do function more like ‘link maps’ usually, because they are attached to an arbitrarily-shaped body of discussion.)
The story index for Alice and Kev, the story of being homeless in The Sims 3. This one interests me because it is a completed blog that has been organized by the writer.
The Mencius Moldbug topical archive and chronology. Please don’t make me comment on what ‘toxic’ or ‘enlightened’ substance might be in these papers—I have no idea. I am just looking at the layout and possible uses of the link map. (Related: Yvain’s posts on Less Wrong.)
Index of users banned from the ‘slate star codex’ reddit.
QAnon Map, it’s crazy to me this polished, almost military-grade skin over a 4Chan. I think this is sufficient proof that the underlying technology doesn’t matter—and it may even be a benefit to be plain, easy to copy-paste—when building a hypertext ‘body’.
_why’s Estate, collected writings of a programmer who abandoned all of his work.
Gwern’s home page is a topical guide to the site.
These all seem to follow the collapse or completion of a work—very few maps seem to be made while the ‘body’ is underway. I also wonder to what degree these misrepresent the ‘body’.
This document, however, isn’t a ‘link map’ because I am just linking to a bunch of separate ‘maps’ rather than focusing my links on a single ‘body’ of work.
I will add to this list over time, who knows where it’s going.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I didn’t much care about search when you said this, but using h0p3’s search and your directory and Pinboard—there’s no doubt that it’s useful. It warps you to a place in the collection that’s workable.
I’ve worked out a search index that’s entirely done in JavaScript—it’s the same one I’m now using on my blog. Thanks to TiddlyWiki for helping me realize that this could be a great way forward!
When I publish, it updates the search index. (Right now my blog’s search index is 300k. Raw text of my blog is 1.2 megs. The index is loaded when a search is performed and cached for further searches.) I haven’t decided where to place it in the directory yet.
In 20 years I’ll either be dead or so old I won’t care. My time horizon is a good 10 years, which is forever in Internet time and is part of why I’m doing this now rather than dithering. You are right this is a long term game.
Hah! I laughed when you wrote this and I might as well voice it now. See you in
ten years, brother. 
This is all good. The Indieweb folks are taking care of the social aspect, which is blogcentric sorta by definition. We can aid in discovery for the blogs and the non-blog sites. If there is to be an Independent Web X.0 somebody has to help map it.
I think one of my primary questions these days is: will the future be blogcentric? I feel like things are going to change. Although they could get more hyperactive. Thought streaming? Let’s hope not.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Cool—I am working on consolidating my bookmarks into a single directory (much like Brad has done at Indieseek.xyz, but it’s interesting to see you go with the approach of keeping links housed differently based on their purpose. It’s cool and your very thorough explanation is convincing!
I do like when people use Pinboard—and might consider double-posting there—mostly because I love that I can browse pinboard.com/t:toread to find interesting things. I keep looking for a common tag that means: ‘I don’t know what to think about this link.’
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘I didn’t really see it as being about anything…’
Man, I try to do interviews, but this is really good!
OL: Why and why in Heartland neighborhoods?
SS: Well, when I was thinking about putting a page on GeoCities there were various neighborhoods that were about specific things, and I didn’t really see it as being about anything, And Heartland seemed like sort of a friendly catch-all one, they called it the family neighborhood I think. So that seemed the best place for me.
I think there’s a temptation to call it ‘about nothing’ if it’s a page that’s not ‘about anything’. I love finding pages that just meander with no particular aim. Though it’s harder to name pages that are like that in the present.
OL: Let’s go though your home page. When I saw it for the first time it immediately attracted my attention, because you stroked through the Welcome to My Home Page
Welcome to My PageHere’s the Page
In the next sentence you explained that you strike it through because
“One of the books I looked at on how to code HTML said “Don’t put ‘Welcome to my page’ on your page”, because people already know they’re welcome, so I tried to think how to start this without putting that on first, and really, it seems sort of stark without some kind of greeting. So my second idea was just to say “Here’s the page”, as an homage to my seven-year-old son, who has started saying “Bon appetit” at mealtimes, and I discovered that he thought it meant “Here’s the food.”
This is such a sweet thing—and it reminds me that this sort of thing is still alive when people share the things kids say or fragments of overheard conversation and there is no stigma around those things. But I think there was some backlash against LiveJournal and the initial ‘meaningless’ Twitter status updates—but perhaps Susan was able to do this artfully. (I genuinely think her page is still great to read. It reminds me of a blog called Murrmurrs that I came across recently that I have been enjoying for similar reasons.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A discussion of portals into a large hypertext.
Ok, this is rich—this point is on fire. We agree, yeah, oh hell yeah we agree. This is what I’m saying every third paragraph about how our technology is underutilized. This is a great example of the ‘social’ overemphasis of the single ‘post’ or ‘link’ or ‘article’ as opposed to the hypertext ‘body’.
(For anyone just joining this conversation, h0p3’s link in the quote above loads about 10 pieces of hypertext that represent his current ‘place’ in this massive [20 megabyte] ‘body’ he’s creating—so the ‘link’ he’s sent doesn’t represent a single ‘article’ or ‘tweet’, which is what we’re trained to think of a ‘link’ representing. And I wonder—beyond h0p3’s twenty megs—how can I ‘link’ to the ten related tabs I might have open so that you can see them together? How can you create your own ‘link’ that puts me into the center of a hypertext perspective you have?)
(In some ways, this reminds me of heavily cross-referenced and footnoted texts like religious scripture—which are hyperlinked in a fashion—and folks have long batched together references to these works through verse-chapter or page citations, and most often through quotes. The amazing feature of the link above is that it isn’t just a set of quotes—it is the definitive source material, connected to the live author. Is it possible that citation could be improved by allowing one to construct a link of views to many definitive hypertexts?)
I won’t even touch Reddit [and it’s spidering onto the rest of the web] without half a dozen tweaks and tools; it’s not worth my time.
I like to say that all our problems are human problems at this point—but I think I am starting to see that every site needs good search, some kind of indexing and a way of positioning it within the whole landscape outside of it. I wonder what tools you find most useful—are they just useful within Reddit or should they be available to you and I somehow?
I grant, however, that some methods are better than others. What counts as finding relevance in our hyperreading in general is some ridiculously hard problem. It’s probably fair to say most people will quickly run out of things they find worth reading on this wiki (if they found anything).
Yeah, I think if we start to get too ‘hyper’ we get lost in the linkage and things get blurry. I mean when it comes down to it, I just want to do some very basic things: meet people, connect thoughts, really dig into a concept, see neat things—and try to route around the armchair arrogance that seems to be plaguing the world.
I don’t plan to read your whole wiki—I plan to use it to research your takes as we correspond and to consult it while I’m studying, to see what other directions I can go. (I wonder if you’ll agree with this:) I think the point isn’t to make your wiki the Penn Station of philosophy—I just think some valuable things will bubble up out of your project that will connect to Penn Station bidirectionally. Just like I might draw from Vigoleis or Dr. Strangelove from time to time—philosopher.life is in there, too.
I’m not sure if I can say that they are manipulating the feed.
Manipulators treat the minds of others as mere means; they do not respect your dignity. Satya Nadella is a manipulator. Does that mean he and cabal of powerful deep state actors have conspired to control every little detail of your mind? No. But, the science of rhetoric, mass manipulation, and our ability as a species to produce increasingly effective apex predators only continues to rise. Power centralizes at any cost, including moral ones.
I guess I try to manipulate the feed, too, so yeah, of course he’s manipulating the feed. Why I’m reluctant to just pin the award on him: I’m not sure he’s actually accomplishing what he claims to be. I love that he’s put all of this work into influencing Hacker News, but his boasting about it could clearly undo all that work—so what kind of master manipulator are we really dealing with here?
The short-term efforts undermine the long-term—his infrastructure is not nearly as sound as it seems.
What are games except for sets of rules we play by to win?
Yeah, man, good questions. I think the trolls are way ahead in this effort—I think they see that they can create games that are honeypots. And I do think that the Internet still holds the power to flip the structure so that it is the powerful who get caught in these games that they think they can play. (Thus, the meme warfare centers.) I think the trouble is that trolls are chaotic and can align anyway they like—evil, neutral and good—are even ‘neutral’ and ‘good’ more likely to turn out to be ‘evil’ than vice versa? On the other hand, chaotics have been the Robin Hoods, the Guy Fawkeses, the Snowdens perhaps. I think we benefit by tapping into that subversive light-heartedness.
As you point out, we are still going to need a standard for when we define something as cooperating. If I respond to your letters with one word answers, I’m offering a token. You cannot escape measuring reality to some very large extent. I think this is part of our plight. Yet, the goal is to not be overly quantitative (where, unfortunately, “overly” is quantitative).
Oh—I like your arguments, answers and agreements on the T42T outlines. I think this also goes in with my thoughts on what I called ‘pluralism’ (but which really just means ‘a multimodal system of thinking’)—just as one needs to both ‘quantify’ and restrain from such a thing, just as one must respond in kind, respond with a token, respond with a tome (and never know precisely if one is doing it ‘right’)—it is always a constant balancing in a battle of extremes and competing ideals. Much like a relationship is a balance between what I am looking for and you are looking for.
So also I look at socialism and capitalism as arrows in my quiver; left and right as sides of myself more than two religions at war. This is overly simplistic—but so is T42T, it is a useful starting place for me. It is not the end, it is the curated entry point. It is the self-made doorway.
(The remainder of your letter—the part that essentially argues for staking a position—I am going to digest and figure out how to respond. I don’t have any problem with what you’re saying in a general sense; it is principled. I, personally, cannot get myself to ratchet down to anything concrete, for some reason. I think part of it is that I really do enjoy human beings—I am hard-staked against misanthropy—and that puts me in a really weird place wrt to modern culture and forming an alliance with a group rather than an individual. But if the mindset is totally bereft, then I am willing to abandon it.)
(As far as the TiddlyWiki loader: I am also waiting for more inspiration there. I think of that prototype as ‘chapter one’—I usually have to batch up ideas and code fragments in order to realize them. But glad it got the conversation going. I am thinking a lot about versioning—for example, can the timestamp also be part of the curated doorway that is the undercurrent of this exchange?)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I am very tied up trying to finish mine, but you’re doing a lot of good writing and I wish I was done so I we could be synced up on this.
I think the other question we need to ask is: how do we make a directory that’s not a directory? Like: is there a new kind of directory that is an evolution of the tried format? And I think the main point of pain is having to enter this giant catalog through a straw.
Just like Google is ‘entered into’ through a few search words—terms that rarely hit the mark and need to be gamed—could the directory widen the straw somehow? This is what is done by providing a hierarchy—but I also wonder if there are other novel forms. Like: say the directory changed day-by-day to suggest common categories or to show where I’ve been editing or to suggest a few categories.
I also wonder if a ‘pinned post’ might be useful: here are a few suggested categories, here’s one I added recently that’s kind of sweet, here are a few links that I’m considering throwing out.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘Constructing a body of hypertext over time—such as with blogs or wikis—with an emphasis on the strengths of linking (within and without the text) and rich formatting.’
‘Constructing a body of hypertext over time—such as with blogs or wikis—with an emphasis on the strengths of linking (within and without the text) and rich formatting.’
A superset of blogging and wiki creation, as well as movements like the Indieweb and, to some degree, federated networks.
Does it include social networks like Twitter and Mastodon? Sure, depends on what you’re doing. If that network is helping you build a body of hypertext, is keeping you sufficiently ‘linked’ and gives you enough of an ability to format the text, then ‘super’—you are hypertexting in your way.
Although:
Ton Zijlstra:
At some point social software morphed into social media, and its original potential and value as informal learning tools was lost in my eyes.
I hope it goes without saying that Twitter is a limited form of hypertexting. It underutilizes the tech—that’s its whole point, right?
You can compartmentalize your various writings, though.
Jennifer Hill:
And you’re probably all sitting there and you’re like, “This girl wants me to delete Facebook, Instagram, Twitter… I got a following! I got a brand!”No, that’s not what I’m saying. You have two selves. You have a career self, who—I’m pretty sure all of us have to use Facebook, Instagram and Twitter for work or Medium or whatever other platform in the world you want to use—and then you have your personal self that knows the things that they’re doing. And what I’m speaking to right know is your personal self. You know, I understand you gotta make money, gotta make that dime…
But the point of the term is not to disqualify a certain technology or to try to channel disgust or disdain into something new—that’s exactly why the term is envisioned as a superset. I am extracting this term from what I am seeing develop on the Web.
A superset is the inversion of a subset. So, rather than dividing a topic into further subtopics—we combine related topics into a new ‘super’ topic. By redrawing the lines of the topic, it is possible to discover new subsets within the superset or to work with folks across the topic as a whole.
In this case, the superset seems superuseful since the division lines between the hypertext niches are almost entirely structural. (This isn’t entirely true: some structures imply, for example, centralization. A feed of interleaved user ‘stuff’ is done most simply by a single network housing that data—at least at first.)
I’m not even sure the subsets actually exist. It is already all hypertext that conforms to a variety of possible structures:

The blog (feed) and the wiki (ad-hoc) might not actually be different—despite that we think of wikis as being multi-writer (the original wikis anyone could edit, without respect to any record of permanent trolling demerits) and using a simplified markup that made linking fluid while writing—a blog can do what a wiki can do and vice versa.
By decoupling the hypertext from the implied structure of a wiki or blog, I can now look at these structures as mere arrangements of my hypertextual body.
I think it’s worth repeating the criteria of ‘hypertexting’ so that it can be either corrected or remain crystal clear.
There is nothing new at all here—in fact, it’s all becoming very old—but the superset distinction allow us to draw attention to the ‘body’ rather than the blog ‘post’ or the wiki ‘page’ and to ask: ‘what are we creating here?’ The body itself is a superset—and ‘hypertexting’ calls into focus what the work as a whole can be from a higher vantage point.
These three attributes imply an effort that goes beyond writing alone. The first creates a body whose length is practically infinite—no reader will likely consume it all. The second indicates that much research (both external and self-research) is required. And the third gives a sense of bottomless innovation to the publishing interface—in fact, as long as the body is able to remain intact, it can be published by anyone exactly as it is intended, as long as the browser remains compatible, which it has done remarkably well so far.
In addition, this gives us the impetus to preserve the browser’s life and compatibility, such that these bodies are kept alive.
Creating a body this large demands the ability to shape the structure. This is the problem: how do I begin to approach your giant monolith of hypertext beyond just reading your two or three latest posts?
What I would like to highlight is the ability of the author to use the ‘body’, its linking and formatting, to shape the structure. To infoshape.[1]
Link directories are clearly a part of this superset. Delicious and Pinboard themselves act as hypertexting swarms that work to connect the bodies. Maybe these connections fill holes in the body—maybe they act as introductions between bodies. They are a way to shape the info and annotate it slightly.
h0p3: I’m actually annoyed when people call my wiki a blog, since it is obviously not that to me. Of course, the fool in me starts wondering what exactly on the web doesn’t count as hypertexting? What doesn’t have a single entry point?
The home page is definitely the curated entry point. But it’s not just that entry point that’s important—the points that go deeper from there are important. h0p3’s home page was initially the most important thing to me. But now it’s the ‘recent changes’ page and the bookmarks I have that indicate where I intend to next explore further. Sometimes he is a blog, sometimes he is a wiki. Sorry, man!
So, (tentatively,) let’s look at three aspects of your hypertext:
To bring this into practice, here are a few interesting ways I’ve seen this play out:
Zylstra.org: This blog builds on itself day to day. In a way, posts become redundant because Ton is very careful to rewrite the same idea in different ways—to be sure it’s understood. I have read articles from 2008 that are only subtly different from others in 2018. But this makes sense—his message hasn’t been received yet. On top of this, he has a small directory for reading through his writings. I found this perfectly useful. You can do this kind of thing by hand, if you need to.
h0p3: I guarantee you’ve never seen a wiki used this way—as a backup for physical letters, as a way of messaging people, of writing drafts in public, of keeping detailed link logs, chat logs—it’s all in there. Links are used liberally throughout everything, so that you can track h0p3’s growing nomenclature.
More than half of hypertexting is the reading behind it—because if you are hypertexting in isolation, then you are missing out on a world of links.
Ton:
I treat blogging as thinking out loud and extending/building on others blogposts as conversation. Conversations that are distributed over multiple websites and over time, distributed conversations.
What you might think of as ‘advanced hypertexting’ simply allows the shaping of the hypertext. Could we go beyond that?
To me, this is a great advantage of the superset. If the platform could see itself less as being a blog or a wiki or a directory, but as a collection of hypertexts that can be shaped, perhaps by hypertexts themselves. (Wikis—and TiddlyWiki in particular—have long had this abililty to make a page that displays the other pages as a blog. And some wikis allow you to include pages in other pages.)
The advanced hypertexting doesn’t end with the wiki—it’s just one way. I think Tumblr was initially on to something—aesthetic and piece layout are important here. Now add the ‘advanced’ hypertexting and what do you have?
(This is an unfinished steno—it could use a survey of the hypertexting field here. And it will be interesting to see where things go over the next six months. I will have to revisit this after I learn more.)
(I think the other missing discussion is how ‘ephemeral’ fragments fit into this. See also: Blogging.)
The other side of this coin is Infostrats—the reading of hypertext. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Pinboard and Indieweb.xyz as clustering tools.
Ok ok, one other thing that has dawned on me: it’s not just the emergent connections between writers that is salient when clustering. It’s the connections between readers as well! (This is one thing that Google cannot possibly capture.)
To akaKenSmith’s point:
Having found each other, kindred parties need a work space where they can develop shared understandings.
The old Delicious was this kind of workspace for readers - a similar effort can be found in Pinboard.
One interesting thing I like to do with Pinboard is to look up a link - say ‘The Zymoglyphic Musem’ (results here) and then look at the other bookmarks for those who found the link. For example, the user PistachioRoux.
All of those links are now related to ‘The Zymoglyphic Museum’ by virtue of being in the realm of interest of PistachioRoux. YouTube uses these sorts of algorithms to find related videos by matching your realms of interest with someone else’s. However, in the process, that person is removed. (Or ‘those people’, more appropriately.) PistachioRoux is removed.
But perhaps PistachioRoux is the most interesting part of the discovery.
Particularly in a world which is becoming dominated by writers rather than readers - maybe the discovery of valuable readers is part of this.
Say a post tagged with #how_to #mk #fix_stabs could be crawled and collected into a single mechanical keyboard maintenance page. All that really calls for is emergent keywords from communities and tagging posts which bloggers can do and automations can assists with.
This does sound a lot like Indieweb.xyz, as @jgmac1106 mentioned. The concept is simple:
So the emergence should come from blogs clustering around a given URL.
I’ve been wondering if they could do a similar thing with http://www.adfreeblog.org/ - a ‘general’ blog community could be established around a simple ideal like that.
Might look like this:
The adfreeblog.org home page then becomes a directory of the community. So, kind of like a webring, but actually organized. With Twitter cards and such floating in the metadata, it is probably much easier to extrapolate a good directory entry.
Spam is an issue with this approach - but it’s a start toward discovery. There aren’t a whole lot of ways for a blog to jump out from the aether and say, “I’m over here - blogging about keyboards too!” And, in a way, the efforts to squash abuse and harassment are making it more difficult.
This can become an important component in the new discovery system like how awesome-blahblah github repos are playing a key role in open source discovery.
I think it’s important to point out, though, that ‘awesome’ directories are intended to be human-curated, not generative. They feel like a modern incarnation of the old ‘expert’ pages.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Mild automation alongside hypertexting in the Indieweb.
Oh yes—I quite agree! I didn’t when I started this blog—I was pretty burned out on algorithms. But I’ve calmed down and, yeah, I think your word of ‘automation’ is more friendly to me than ‘algorithm’.
I’m really getting a lot of good stuff out of Pinboard—it is better than Google, DDG, Million Short or any directory at finding interesting stuff. And it is due to its balance between machine and human: the humans find the link and tag it; the machine collates everything for the researcher. You can do pretty complex queries with it, which I am using every day now. (As an example: /u:krudd/t:links/t:web shows me all links tagged ‘web’ and ‘links’ under the user ‘krudd’.)
However, it is still totally underutilized. I would be surprised if there were five other people on the Earth mining it like I am. (This wasn’t true of the old Delicious—it was a golden age for this kind of mining of bookmarks.)
One great thing to automate would be Webmentions for Pinboard. Think of it: when you (Brad) mention me, I put a link to you at the bottom of that page. You are another writer, so if someone likes your comment, they can visit you to see more of your writings.
But if I had Webmentions from Pinboard, you could go to the bottom of my page and see what readers are mentioning my page. And those readers can be visited—not to see what they are writing, but to see what else they are reading. There is a temptation to remove the reader’s name and just inline their relevant links at the bottom of my post. But I think that removing the human possibly destroys the most valuable piece of information.
I’m beginning to think single author wiki’s are way under utilized. Blogs are cool but relentless about pushing down older posts.
I’m starting to categorize the ‘blogging’ and ‘wiki-ing’ actions under the superset called ‘hypertexting’. Both are about simply writing hypertexts, but blogs arrange those texts in a linear summary and wikis arrange them as a web which starts from a single entry point. (And a self-contained hypertext book or directory would be a tree.)
I think that if we could retreat to mere ‘hypertexting’ and then give people a choice of entry points, we could marry the ephemeral and the permanent and do exciting things with the entire body of the ‘hypertext’. This is where my blog is moving toward and it’s obviously inspired by h0p3’s system and the Indieweb as a whole.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
It’s constant work—finding each other through the noise.
Hi, folks - just jumping in because this is my wheel house a bit. I have been having an extended discussion with Brad Enslen (so, on our blogs: ramblinggit.com and kickscondor.com) about discovery. We talk a lot about how this is more of a human problem than a technology problem - and that technology has played a negative role in this, perhaps.
(My part in this is: I have been spending time every day for the past six months searching for blogs - to see what the Web looks like outside of social networks. So I have a good perspective on where one can search nowadays - you can’t just type ‘blogs’ into Google. And I’m starting to get a good feel for where I would want to go to find blogs.)
blogrolls didn’t scale. ring blogs just sucked. SEO is just survival-of-the-fittest money pit.
Yes, so - for sure. (See Brad’s comment on Google here.)
In addition, self-promotion has become a dirtier word these days - you can’t just post your blog to Reddit and Instagram - it’s seen as being overly assertive. So there is almost nowhere for blogs to go.
The thing is: no, blogrolls didn’t scale - but I think they are pretty essential. We’ve traded a human-curated list of links for a ‘friends’ list that is really just a number on an individual’s feed. And the best blogrolls had nice descriptions of who was who (see: Chris Aldrich’s following page as a good example) which is a generous way of turning your readers on to other good work.
I guess I just think of it practically: how would we treat our friends and the other ‘writers’/‘artists’ we admire - by making them a number in our list? Or by spelling it out: “Annie writes about her processes as a sci-fi writer and how to improve online relationships. Basically - it’s uplifting to read her.”
Blog clusters are emergent. Fake or not, blogs with posts on similar topics will be mapped to same cluster which can be seen as a place in which a blog belongs to. Once we have that, a blog reader should be able to ‘pop out’ of that blog and see some visual representation of that cluster with neighboring blogs, not unlike a shopper leaving a store will see a street lined with other shops. That’s how discovery is done IRL and I envision that may be possible online.
Sweet - feels practical. One question I have here is: ok, so blogs have also become more topic-based. The most common blogs are recipe blogs, movie blogs, etc. But a great ‘lost’ element of blogs was just the original web journal or meta blog, where a person is just writing about whatever - I think of stuff like the old J-Walk blog or Bifurcated Rivets. Even Boing Boing used to be more this way. (So like an online ‘zine’.)
I think the orderliness of the Internet and the systems for discovery - these blogs were not found through Google, but only because there was more of an ethic of linking to each other among early blogs. A lot of discovery was just being done by bloggers back then - people simply passed links around.
Again, ‘likes’ have drained linking of a lot of its bite. We don’t write so much about why we like something - we like it and move on. And it’s so easy to ‘like’, it is done so vigorously that even we can’t keep up with our own likes - whereas we used to be limited by how much energy we would spend dressing up our links.
I’m with Don on this – whatever is going to have a chance to work has to be emergent, meaning it can’t require any investment on the part of writers.
I think ‘emergent’ can require work - in fact, it might demand work. Yes, too much work will dissuade anyone. But if it’s too easy, then it’s virtually worthless. I think the value of human curation is in its additional care.
An algorithm cannot simulate the care. Chris’ blogroll linked above is done with care - a human can plainly see that another human has taken the time to write about others. And the more time he spends designing it and improving it, the more it shows that care. People can visit my blog and see that it is built with care. (To me ‘care’ can be represented by thoughtful writing and splendid artistry or shaping of the information.)
Ok - sorry to go on so long, I hope you see this as my effort to generously engage in your discussion.
The effort Brad and I are now engaged in is an effort to bring back the link directory and to attempt to innovate it based on what we’ve learned. (Link directories have already evolved several times into: blogrolls, wikis, link blogs, even the App Store’s new ‘magazine’ approach, etc.) The idea is to jump right into discovery and link up with anyone else who wants to get in on it. Thus, my reply today!
Good to meet you all - take care.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I feel a connection to the original Occupy ethos outside of the topic of class. I like to think that the work on my blog has a similar aim. 1% of the humans have the attention. I want to spend my time, though, looking at the work of the other ninety-nine.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A hypertext book underway for ten years.
No idea if this link has already made it around many times over. Seems relevant to the TiddlyWiki crowd. It’s a ‘book’/‘wiki’/‘whatever’.
Couple things;
Drafts are clearly marked with a nice pickaxe icon. And the whole article is flocked in gray. (See above.)
Cool hierarchy at the bottom of the page. Explains the book and gets you around. Kind of like this stuff being at the bottom so the article can take up the top.
Comments on each page are hidden.
Found this by way of the article on the death of subcultures. Don’t know about anyone else here but I’ve wondered about this for the past several years. I still consider myself a ‘mod’. And I mean there are still ‘hipsters’ and insane clown posses around—doesn’t feel the same.
See also: giant chart that explains everything. I’m really starting to collect these. Peace out there, my clan.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
What an astounding post—this feels like the situation today. (And sure enough—FOAF, XML-RPC and SOAP all went their way.) It is pretty surprising that Microformats have somewhat survived—the u- and p- prefixes, figuring out how to nest elements, complex rules like you see on the Indieweb authorship page.
I wonder what drives the complexity of something like ActivityPub. Is it a kind of premature future-proofing? Is it just a desire to load the thing with features? I especially wonder about something like FOAF, which should be conceptually simple.
Really appreciate the conversation, Manton.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The name is odd; the campiness is tuned in.
So this thing starts off as a kind of old-school banner ad but—scroll, scroll—it’s a link directory! Pretty sweet—I like that it’s just a bunch of tiles and you have to wonder what’s behind them. (And wondering about its creator.)
Like here’s a personal homepage that was crammed in there. The counter says only 40 people have been there. And you might say, “What is even there? Why would I even spend time here?” Is bouncy text not enough for you? Is being the 41ST PERSON not enough??
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ran across this note from 2013 that hates on ‘content’. From net.artist Olia Lialina. Relevant.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A gateway to the Old Web and its sparkling, angelic imagery.
I try not to get too wrapped up in mere nostalgia here—I’m more interested in where the Web is going next than where it’s been. But, hell, then I fumble into a site like this one and I just get sucked up into the halcyon GIFs.
This site simply explores the full Geocities torrent, reviewing and screenshotting and digging up history. The archive gets tackled by the writers in thematic bites, such as sites that were last updated right after 9/11, tracking down construction cones, or denizens of the ‘Pentagon’ neighborhood.
Their restoration of the Papercat is really cool. Click on it. Yeah, check that out. Now here’s something. Get your pics scanned and I’ll mail you back? Oh, krikey, Dave (HBboy). What a time to be alive.
But, beyond that, there is a network of other blogs and sites connected to this one:

oocities.com/username.I was also happy to discover that the majority (all?) of the posts are done by Olia Lialina, who is one of the original net.artists—I admire her other work greatly! Ok, cool.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A prototype for the time being.
I’m sorry to be very ‘projecty’ today—I will get back to linking and surfing straightway. But, first, I need to share a prototype that I’ve been working on.
Our friend h0p3[1] has now filled his personal, public TiddlyWiki to the brim—a whopping 21 MEGAbyte file full of, oh, words. Phrases. Dark-triadic memetic, for instance. And I’m not eager for him to abandon this wiki to another system—and I’m not sure he can.
So, I’ve fashioned a doorway.
This is not a permanent mirror yet. Please don’t link to it.

Yes, there is also an archive page. I took these from his Github repo, which appears to go all the way back to the beginning.
Ok, yes, so it does have one other feature: it works with the browser cache. This means that if you load snapshot #623 and then load #624, it will not reload the entire wiki all over again—just the changes. This is because they are both based on the same snapshot (which is #618, to be precise.) So—if you are reading over the course of a month, you should only load the snapshot once.
Snapshots are taken once the changes go beyond 2 MB—though this can be tuned, of course.
Shrunk to 11% of its original size. This is done through the use of judicious diffs (or deltas). The code is in my TiddlyWiki-loader repository.
I picked up this project last week and kind of got sucked into it. I tried a number of approaches—both in snapshotting the thing and in loading the HTML.
I ended up with an IFRAME in the end. It was just so much faster to push a 21 MB string through IFRAME’s srcdoc property than to use stuff like innerHTML or parseHTML or all the other strategies.
Also: document.write (and document.open and document.close) seems immensely slow and unreliable. Perhaps I was doing it wrong? (You can look through the commit log on Github to find my old work.)
I originally thought I’d settled on splitting the wiki up into ~200 pieces that would be updated with changes each time the wiki gets synchronized. I got a fair bit into the algorithm here (and, again, this can be seen in the commit log—the kicksplit.py script.)
But two-hundred chunks of 21 MB is still 10k per chunk. And usually a single day of edits would result in twenty chunks being updated. This meant a single snapshot would be two megs. In a few days, we’re up to eight megs.
Once I went back to diffs and saw that a single day usually only comprised 20-50k of changes (and that this stayed consistent over the entire life of h0p3’s wiki,) I was convinced. The use of diffs also made it very simple to add an archives page.
In addition, this will help with TiddlyWikis that are shared on the Dat network[2]. Right now, if you have a Dat with a TiddlyWiki in it, it will grow in size just like the 6 gig folder I talked about in the last box. If you use this script, you can be down to a reasonable size. (I also believe I can get this to work directly from TiddlyWiki from inside of Beaker.)
And, so, yeah, here is a dat link you can enjoy: dat://38c211…a3/
I think that’s all that I’ll discuss here, for further technical details (and how to actually use it), see the README. I just want to offer help to my friends out there that are doing this kind of work and encourage anyone else who might be worried that hosting a public TiddlyWiki might drain too much bandwidth.
philosopher.life, dontchakno? I’m not going to type it in for ya. ↩︎
The network used by the Beaker Browser, which is one of my tultywits. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Along with a discussion of personal encyclopedias.
There has been a small, barely discernable flurry of activity lately[1] around the idea of personal knowledge bases—in the same vicinity as personal wikis that I like to read. (I’ve been a fan of personal encyclopedias since discovering Samuel Johnson and, particularly, Thomas Browne, as a child—and am always on a search for the homes of these types of individuals in modernity.)
Nikita’s wiki is the most established of those I’ve seen so far, enhanced by the proximity of Nikita’s Learn Anything, which appears to be a kind of ‘awesome directory’[2] laid out in a hierarchical map.

Another project that came up was Ceasar Bautista’s Encyclopedia, which I installed to get a feel for. You add text files to this thing and it generates nice pages for them. However, it requires a bunch of supporting software, so most people are probably better served by TiddlyWiki. This encyclopedia’s main page is a simple search box—which would be a novel way of configuring a TiddlyWiki.
I view these kinds of personal directories as the connecting tissue of the Web. They are pure linkage, connecting the valuable parts. And they, in the sense that they curate and edit this material, are valuable and generous works. To be an industrious librarian, journalist or archivist is to enrich the species—to credit one’s sources and to simply pay attention to others.
I will also point you to the Meta Knowledge repo, which lists a number of similar sites out there. I am left wondering: where does this crowd congregate? Who can introduce me to them?
Mostly centering around these two discussion threads:
↩︎Discussed at The Awesome Directories. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, great start to our discussion about styling citations from each other in matching CSS.
I am sending this reply with a musky pork pie smell. See the attached WIFF file.
Yet again to my ignorance: I clearly do not appreciate Art as well as others. I’m an uncouth pig here. I love consuming it as a drug, and I’ve (very poorly) made plenty of it before. Trying to emotionally communicate the cognitively ineffable is something I do take seriously (enough to be very particular about it). Forgive me for being the joyless buzzkill rhetoric-hawk.
Ha-ha! Well, you are becoming very endeared to me, hawk. And you are right to keep us all in check. The buzz that you do kill—and it’s certainly not a buzzard-sized buzz—is not any buzz that was killed just 'cause.
I’m especially interested in form as it relates to function; I want something productive (pleasant workspaces help me work, of course). I don’t think I’m obsessed with minimalism (though I appreciate it), but rather plainness irwartfrr. If it works and it looks good enough: cool, I like that. I’m the kind of dude that will buy 5 identical shirts if I know they are cheap and comfortable. I want the majority of expressive work in my wiki to be in my words. Ideally, I want my words to carry as much of their meaning as possible without relying upon appearance (which I think can be nearly all of it), and only then do I want to work on appearance beyond as function as the delicious bonus.
Oh, I see this in you and I applaud it—loudly, standing—an ovation which goes in a great arc, knocking over the drinks of everyone else standing around me. (Part of this ovation is a simple appreciation of your last epic missive, which is due.)
I only side more toward art because I get so much out of it. I can’t think of a reasoned argument that has transfixed me as much as “Starry, Starry Night” has. And I don’t reach for a reasoned argument when life has fallen apart, but for Neil Young. (I am not arguing with you here—I know you have these things, too, and that you love cartoons and songs and shows and all that. And, come on—you are nuts for ASCII art, amirite? Alas, I also do fall into the trap you’re talking about of form over function.)
Alright, so with all those caveats in mind, we may end up doing this all by hand and passing tiddlers around—I’m also going to play with some styled RSS tonight and see what happens. And we’ll toss some ideas around.
One thing I know for sure: I don’t want to go too crazy on fonts, because I don’t want readers to have to load ten Web Fonts to make this work. That would be EXACTLY fonts over functions. But the basic colors and stuff—worth a try, yeah?
(One time you asked if you should read Vigoleis—no, don’t. He’s mine. And it’s like Infinite Jest, it will take you way too long to read and you’ll never want to read it again. Infinite Jest also wasn’t for me.)
Oh, also, from the footnote:
In a blind, stripped-down test, I’d prefer to make it so even a paraphrase of something I’ve said would evoke: ‘that sounds like h0p3’ or ‘h0p3 would like that’ or ‘you know who probably wouldn’t stop blathering on about this if he were reading this with me right now?..h0p3’ or ‘omg, this sounds like that asshole h0p3, lol.’
I feel this way about the words, too, for sure—but also the appearance. It’s like remembering The Three Stigmata of Palmer Eldritch for both the chitinous foreheads inside and the orange-red cover of the bug-eyed man with the robotic hands. It all comes flooding back like that.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Another promising introspective TiddlyWiki appears on the horizon of the network.
What excites me about sphygmus is: first, that she’s confronting this fear and we get to see what happens. (We out on the Old Web all have to confront this: that we might not find anyone here without the self-advertising infrastructure that the big networks have.) It’s uncertain why we are reading each other, why we are writing, who we are—there is a lot of uncertainty that I’m feeling, too, and I have this strange belief that someone else might have the answer. (In a way, OF COURSE SOMEONE ELSE HAS THE ANSWER—you out there are the ones who choose to ‘ignore’ or ‘respect’ or ‘dismiss’. Or to ‘jump right in’.)
But I am running a blog with comments—it’s easier to get feedback. A TiddlyWiki is genuinely on someone else’s turf. It is AT ODDS with the Indieweb. The ‘Indieweb’ is attempting to solve personal interaction with additional technology. But a TiddlyWiki like this is attempting to solve personal interaction by—well, it’s not trying to solve personal interaction. It expects you to learn its system and, in a way, the technology works against you, because it has a learning curve.
In other words, it’s all on us to understand and read each other. (The entire Twitter network is built on the idea that you can take someone’s 140 characters on its own, out of any context, as an independent statement—there is no need to read back on the history there. But with a TiddlyWiki, the system requires you to dig—it is possibly the literal opposite.)
We must bear in mind that, fundamentally, there’s no such thing as color; in fact, there’s no such thing as a face, because until the light hits it, it is nonexistent. After all, one of the first things I learned in the School of Art was that there is no such thing as a line; there’s only the light and the shade.
— Alfred Hitchcock
On the Web, we are the light to each other’s faces.
Second, sphygmus’ entrance adds to our midst another person really thinking about how visual style is a non-verbal form of personality. That it can augment our discussion—maybe even be necessary!
I don’t think of it as part of my artistic practice but I think you are right to see a connection. My relationship with my digital spaces is deeply connected to what suits my visual eye - I’m on an absurdly out-dated version of Chrome simply because I hate the way the new Material Design Chrome looks […]
She has already made the innovation of posting all of her material in her own dark-gray-and-cornflower-blue CSS styling. When she posts h0p3’s replies, however, they are in his dark black style and narrow monospace font. (See the screenshot above.) This conjures him in that moment when we read!! (I address this in Things We Left in the Old Web, where one of my criticisms of RSS is that it cruelly strips our words of their coloring. Cruel!)
So: I am interested in how we can cement this. I want to style my h0p3 quotes and my sphygmus quotes similarly—can we come to an accord on how to do this so that I can give YOU control over how these things look? Perhaps we could share CSS fragments on our respective sites?
I covered this a bit in Static: the Gathering, that this HTML might actually be us, might be a model of our soul. But, let’s tilt on the topic a bit.
We are all more or less public figures, it’s only the number of spectators that varies.
— Jose Saramago, The Double
So, yeah, thirdly—what h0p3 and sphygmus are tackling is an approach for being a
fully exposed, well, let’s just say: a human. A wikified human.
There have been attempts to do this in video or blog form—to keep the
camera on a person. In this case, though, the camera feels to be focused on the
mind, the internal dialogue. (In h0p3’s case: the family meetings, the link histories, the
organizational workings—all the behind-the-scenes discussion—maybe it’s ALL
behind-the-scenes discussion. I confess that I’ve also started a personal
TiddlyWiki to store all these same kinds of materials.)
So, what is ‘oversharing’ and what is just ‘sharing’? Oh, GENEROUS ‘SHARING’—what would that be? What is ‘public’ and what is designated ‘private’? Are these pointless distinctions?
Might it be time to pause all the needless labelling of information and to just read?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A little directory of personal directories—sweet!
Ok, this is seriously insane! What a ton of work. Serious respect for your past lives in directory building!
Couple questions:
How much fanfic did you read while building these? I guess I’m wondering how much of this job bordered on literary critique or editing.
Scifimatter refers to ‘HipRank’ in the links—what was that? It seems that you used this to order the links.
You say on Scifimatter that you want to help ‘the surfer’, the ‘amateur and semipro websites’ and—most importantly, perhaps—to ‘encourage fans of SF/F to start their own website’—did this play out? (These are definitely my goals, too—I wonder how to accomplish them.)
Also, I’m a pretty big Godzilla (and monster movie, Kaiju, Biollante) fan, so I loved looking through those links on the Planets Doom. Also, I have to say: it’s impressive that many of the outgoing links in the directory STILL work thanks to the thoroughness of the Wayback Machine! Another benefit of static HTML—even if these directories are static versions of the original dynamic ones.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Tremendous ‘search engine’ discovery!
What a tremendous discovery! I’m really impressed with this and am already finding it useful. I think this is the first search engine that I’ve been excited about in a decade.
You’re doing fantastic work, Brad. New discoveries all the time. Way to surf!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Your blog has been a big inspiration to me because of its design. Part of it is that you’ve used color and photography to craft a unique place. It’s nothing like a ‘a revenue box’—it’s like a lovely novel that stands out on the shelf.
And it goes beyond aesthetics and colors—it’s well-structured. (I really like the metadata section you have on each post. The layout is appealing and it makes me want to explore your site.) Sure, if I’m posting all pictures all day, then Instagram might have everything I need. But what if I’m writing essays and conducting interviews—I want to have the freedom to structure that data so people can find their way around. (In a way, I’m saying that I want to own the ‘algorithm’—I want to just do it by hand.)
And, yeah, I was using Jekyll, too—and left it partly because I want to start doing more blogging outside of the console. I think the Indieweb toolset is still so far behind social media’s—this is why people generally don’t hang out here.
I don’t know what existed before hashtags outside of planets but those two concepts were ways to find people and content on things you were interested in. Reddit’s plumbing is built around this notion. Twitter is compartmentalized around this notion too. Even platforms built on the notion of decentralization and federation uses a centralizing tactic of federating hashtag content to build community. It’s a bit inevitable.
Really great observation here. You’re right—we don’t have a way of tagging and community forming in the Indieweb. I have been building Indieweb.xyz as a way to kind of do this—but it’s hard to know if the approach is right, it hasn’t managed to draw people in. Maybe we need a crawler you can sign up for that will index all your tags and hook us all together.
This thought of yours also brought me to the rel=tag page, which I hadn’t seen before. Not sure what to do with it. Perhaps brid.gy could start adding these hashtags to syndicated posts? Don’t really know.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The text of my second private reply to h0p3’s ‘hyperconversations’—I am saving my own copy of this here after many days have passed.
(This letter was previously sent privately to h0p3, since I felt that I had bungled up a productive discussion. Now that I can see the overall waveform of our discussion, I think there are many things I’m learning about conversing through writing and reading—in fact, I really think my failures so far are more the failures of input rather than out!—and this immense dialogue is becoming a satisfying start to all the dialogues I would love to have with more of you out there!)
(Apologies in advance that I do so much talking here—I swear I’ll never write anything this long again. No one should feel compelled to read this. I will shut up and go back to silent, stoic reading for the rest of the weekend.)
Hi h0p3-
So I am going to try to rewind and do as you say: to take a better shot at
addressing your part of our ‘hyperconversation’. I am sending you this as a
private letter so that you can censor it if you like. I feel like I am starting
to border on a troll of some type  and feel like the nature of my blog would
turn this into a type of ‘broadcast’ that can still receive ‘thumbs up’ and such
sordid things. (Ed.: You can comment on this post, but ‘likes’ and ‘mentions’
are disabled to respect this sentiment!)
and feel like the nature of my blog would
turn this into a type of ‘broadcast’ that can still receive ‘thumbs up’ and such
sordid things. (Ed.: You can comment on this post, but ‘likes’ and ‘mentions’
are disabled to respect this sentiment!)
I hope I can preface these remarks—even if it seems like a bad idea, because it can perceived as changing the topic, taking time away from the ‘meat’. I will get to the topic(s)—but I wonder if some other items might be more pressing (might even be the ‘meat’) because it seems they might be preventing the main discussion from occurring fruitfully.
Ok, so stepping back—I’ve jumped headlong into a discussion with you. (And might I just add: this is a rare opportunity for me and I feel fortunate to have the chance to converse—for you to respect my communications enough that you will give them the thought you have. I have NEVER had the opportunity to correspond in a strictly written way with anyone ever before—to attempt to come to an understanding with them—hmm, well, maybe once, but not to this extent—and this whole time I am wondering if the medium has its limits. I guess this is where Socrates chimes in. Well, of course it does—but I am probably the largest of those limitations—and that feels good. Perhaps my ability to write will strain under the pressure, perhaps yours—and it requires even more of our abilities to read and internalize each other’s writings! For this reason, I would like the conversation to remain written and for us to find some kind of resolution this way.)
This correspondence has had about three major episodes from each of us. I saw this encounter as a foray into a ‘pen pal’ type thing—which is to say: ‘informal’, ‘inconsequential’ and ‘probably frivolous’. (I hope you will let me say all three of those things in good ways, very good ways. I also admire that you are reaching out through/with your autism to speak with me—I do worry about aggravating your own pain, of putting you under unreasonable expectations of my own and of not seeing the full picture of ‘you’—who you are past ‘h0p3’. But only if you need it—I would rather just see ‘h0p3’ for now—this creation is by design and I intend to take it in.) I don’t feel that I want to ‘wrestle’ —I want to ‘pen pal’. After all, this is a work of fiction. The contents of this letter are products of the reader’s imagination. This letter is for entertainment purposes only. Although the form of this letter is autobiographical, it is not. Although this letter may appear authentic, it is not. What appears to be ‘wrestling’ may actually be a new type of sophisticated ‘pal’ engagement maneuver.
Now, I am not an intellectual by any stretch—I have idea no who Kierkegaard is and I can’t keep Kant and Hume straight. I do read a lot—fiction by a wide margin. I do read Vygotsky and Piaget and, sometimes, Jung. Of all the philosophers, I am most fond of Socrates—and feel a brotherhood with you through him. But the writers that I spend my time on are fiction writers - Albert ‘Vigoleis’ Thelen is someone I speak to in my mind very often. To call out to him: ‘Vigoleis’ when I see his place in the world. Denton Welch and Robert Walser are like this for me. But even these closest—I cannot speak intellectually about them, only romantically.
So yes—I think you want to have a philosophical debate with me, but I am not
equipped to do it. And I wonder if it is possible at all. I can’t read all those
guys and read your wiki and read the things I want to read and pursue my current
ambitions. I don’t think you want to have this discussion unless I am an
equipped intellectual. We are both trying to sing and shatter a glass—but your
voice is trained. So while I might still be the one to shatter the glass here
and there, it’s a hell of a lot more painful having to hear my notes along the
way. So this is my opening question: am I misrepresenting what this discussion
is—and what do you want out of it? (In a way, I feel I can almost ‘steel’ this
because of the statement: “There is a lack of fairness in the dialectic here;
I’ve had way more practice thinking about the nitty-gritty, and I must be
extremely cautious not to assume others can or will see what I do.”—I agree
with this and I feel like I am only fleshing it out further above. And this: “I
can’t see far enough to know if he can see what I’m saying (which is a fairly
technical claim in moral philosophy).”—I don’t see it, I had no idea there was
some central claim to ‘hyperconversations’—I thought it was a series of
different claims with some riddles mixed in—which is, I think, where the
central claim is nestled? “I am failing this man.”—Dude, I don’t rely on you—I
have my own system of living—I’m not just an imbalanced pinball lost in your
machine!  )
)
And this: “Hedonic Kierkegaardian Aestheticism is here; it’s inaccurately
factored into the eudaimonic calculation.” I’m not going to even try to parse
this—if I tried, my reaction would be: I don’t feel like my aestheticism is
hedonic at all, but quite virtuous! So I think your phrase is going to be
misunderstood by me and I am just going to sound ridiculous. Perhaps this
comment is not meant for me but for the audience, k0sh3k included. (Hey kid! If
you exist! Hey! I /will/ you to exist for a single ‘Hey there!’)
Some classic Romanticism in here. Reminds me of that fighting phrase: “Brawl a boxer, box a brawler.” I’ve seen this shift many times against my arguments.
I do think we are paired as boxer vs brawler. That was what I trying to say when listing out some of our opposing polarities—you are codifying me in your statement above as well—no harm, just part of trying to understand someone. I don’t feel that you are degenerate and I don’t think you (yet) believe that I am either. I don’t sense that you are trying to assimilate everyone as boxers. But I do think that not being a boxer would forfeit my scrappy end of the ‘wrestle’ or ‘debate’ side and leave us to the ‘pen pal’ aspect strictly.
This is not a small aspect: while I have not been charitable with argumentation, I believe that I have been charitable with the effect you’ve had on my own work and charitable with the credit I give you for stirring up my inventive mind and stimulating me to materialize it. This will last beyond an argument.
For my part: I am not as interested in some of the topics we’re touching on: stuff like emotion/reason (I have spent almost no time thinking about my arguments there, I am going off half-cocked and I do appreciate/embrace your sayings), what ‘the good’ is (I am trying to figure out what the thrust of our discussion even is, man I can’t even begin to sort that out) and even T42T—I still think they are all very worthy topics, but I don’t think I’m your foil on those. I agree with you that I should be required to defend my ethics—but I also don’t have a list on hand like you do—and it’s changing too much for me to even know how to nail it down. I like the part which explores the texture of our online avatars, but even there—I think I need to sit in the presence of them longer before trying to mouth off about them.
I am going to try to make this quick and to the point—which isn’t “you can’t make me sad” but that “momentary sadness doesn’t register as much when there are more permanent sorrow in place” something like that.
But what’s so bad about this sorrow anyway? A woman crossed the street yesterday, waving to me, so I stood and waited for her. She said she knew someone—a name I recognized. She was pleasant and warm to talk to, so we talked. She said that her son had been murdered many years ago. If you just listened to her for five minutes, you would have thought she was insane. Very pleasant and insane. In a good way, a very good way. A whirlwind of details about trajectories and cover-ups. But if you listened for an hour, you could finally she her—and her sorrow. It wasn’t disgusting or repulsive—but familiar and natural. Just a sorrow—as plain as a pleasantness.
I wanted to show her something in the yard, so I motioned for her to cross the gutter—which is quite wide and was rushing with water—it’s more of a canal than a gutter. But her legs were short and she said, “Oh I don’t know.” I held out my hand and she made a move to try to cross. I realized that she was wearing flip-flops and trying to avoid some spiky weeds. I held out both hands—I probably shouldn’t have tried to persuade her—I don’t know, I began to pull her across and she kind of panicked and made a squeal! She stumbled over—she made it—and we laughed out of relief and I felt stubborn, but it was good to move abruptly from sorrow to laughter like that. Like we had come up for air. We are still in the ocean but we are in the air too.
And I wouldn’t like it if you held back some criticism. I should love to be rebuked! When you are in the freezing ocean, it is probably the best time to hear that you have made a grammatical mistake. What a helpful distraction that could be! And you may never forget to make it again.
And children, when they are rebuked—so often they simply drop their head down and say slowly, ‘Ohhh kay…’ For me, this embodies such an ideal—first, to acknowledge that criticism DOES sting, direct criticism truly can, possibly always does, it makes us drop our heads to hear—and, secondly, to simply ‘ack’ the criticism with no further commentary or defense. Perhaps to go without defense would be too submissive—on the other hand, can we endure any criticism as adults? Any?
I probably am doing my own sidestepping and defensiveness of criticism in this letter. I do know I am better to just drop my head and say slowly, ‘Ohhh kay…’
All of this context to say: I realize you aren’t making fun of me at all here, and I appreciate that very much.
Yes, but if we can find a way to truly make fun of each other—wouldn’t that be such a grand achievement?
The shadow over our eyes is a serious problem: I believe it costs us the ability to be cognitively and emotionally vulnerable (even to ourselves). We don’t really get to know each other when we are engaged in good opsec (that’s kind of the point). The public/private adversarial tension does seem contradictory, but I hope to find a middle way; surely there is a linear logical framework from which geometric social cooperation can arise (I must hope).
Continued here:
You can always doubt, and you can only ever improve your Bayesian odds. The inductive step in trust is a leap of faith in Humanity, in The Other, sir. Building trust and real relationships is exactly why I reveal myself to you and everyone else. I want people to see how I conduct myself and my relationships across the board.
And then:
With diamond balls, I really aim to be practically transparent in my practice of saying what I mean and meaning what I say directly because my integrity is at stake.
And also:
We are each cameras, in a sense. I think of this wiki as an external, reifying camera of my internal camera states. I do hope to wield both wisely. I do not think I morally own either of them all the way down except insofar as I am constituted by (exist as an extension or instantiation of) The Moral Law.
If I were to try to identify this central ‘claim’ you are making and to ‘steel’ it: You feel that true and real relationships demand radical transparency. More than that, you see it as a virtue—embodying bravery, integrity and honesty. You see it as a direct solution to prevailing mistrust and misunderstanding in the world. You model this behavior for others.
To you, h0p3, this has a blissful and fortuitous collaboration with modern surveillance. You aren’t saying, “What do I have to hide?” It seems that you are saying, “You can’t make me hide.” And I do not think you do not see it as the ‘correct’ choice—you seem to acknowledge that it is a trade-off—but that you are willing to pay the price. But you believe you have sorted it out: you do believe that the reward will always be greater than the price.
Am I in the ballpark? I don’t really know how to do this!
To this, I have no response. I can only hang my head and say slowly, “Ok Mister H…”
I felt no need to respond to that claim after the letter—I found it well-reasoned! I did wonder how much of it is grounded in the tech ideals of ‘open source’ and ‘gratis’/‘libre’—I’ve had other tech friends dabble in transparency (sharing bank account info publicly, cataloging life activity publicly.) I stand by what I said:
The remarkable thing about your wiki is that you have turned your camera on. In fact, your wiki is defiantly personal—I think it goes beyond a mere camera. Your history. Your conversations. Your letter to your parents. Your thoughts about people—about me. A person can turn on a camera and never say these things. You are on to something. I have no desire to talk you out of it.
I realize now that saying nothing is a failure. You need an ‘ack’. Even if it is a repetition.
I think there is something unanswered here, though: Do you have any adaptations to ‘Gentle ClearNet Doxxing’ after the events of the last month? I have wondered if you were going to write more about this—maybe I missed it. To stand by a rule too doggedly is to be—well—dogmatic. Or has the rule functioned properly? (On the other hand, I might also aspire to be dogmatic about FOSS - just for myself and not for anyone else.) Feel free to just link me to the correct answers that I cannot seem to locate.
Ok, that is the end of this letter. I ran across the “business card” page on your wiki while researching “transparency” and loved it.
-kicks
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Seamonkey is still alive?
I saw that on Wikipedia, but thought it was probably old and didn’t pursue it. But, hey, sure enough! This isn’t bad at all—it loads my site (seemingly perfectly) and allows me to straight-up edit the whole thing. I wonder if it would be difficult to merge this into Beaker somehow… (This plainly uses contentEditable—which makes me realize that I’m quite wrong—there are some lingering read-write features latent in Chrome, Firefox and so on.)
I’ll research what Jekyll and Hugo are, I’ve seen them mentioned.
I wouldn’t go too far into either of these. I previously used Jekyll, but it got too slow for me to regenerate all my HTML. Hugo is faster, but configuration is just too difficult. There is nothing yet as simple as Wordpress. I’ve ended up writing my own because Indieweb features had to be mixed in pretty tightly.
I think the most promising things right now are TiddlyWiki and Beaker. I think that, as Beaker continues to develop, we will see something as solid as Wordpress come out. But until then, I’d stay where you are comfortable writing.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Thinking harder about the surprising return of static HTML.
Static website and blog generators continue to be a very solid and surprising undercurrent out there. What could be more kitschy on the Web than hand-rolled HTML? It must be the hipsters; must be the fusty graybeards. Oh, it is—but we’re also talking about the most ubiquitous file format in the world here.
Popular staticgens sit atop the millions of repositories on Github: Jekyll (#71 with 35.5k stars—above Bitcoin), Next.js (#98 with 29.3k stars, just above Rust), Hugo (#118 with 28.9k stars). This part of the software world has its own focused directories[1] and there is constant innovation—such as this week’s Vapid[2] beta and the recent Cabal[3].
And I keep seeing comments like this:
I recently completed a pretty fun little website for the U.S. freight rail industry using Hugo […] It will soon replace an aging version of the site that was built with Sitecore CMS, .NET, and SQL Server.[4]
Yes, it’s gotten to the point that some out there are creating read-only web APIs (kind of like websites used by machines to communicate between each other)—yes, you heard that right![5]
Clearly there are some obvious practical benefits to static websites, which are listed time and again:

Fast.
Web servers can put up static HTML with lightning speed. Thus you can endure
a sudden viral rash of readers, no problem.
Cheap.
While static HTML might require more disk space than an equivalent dynamic
site—although this is arguable, since there is less software to install
along with it—it requires fewer CPU and memory resources. You can put your
site up on Amazon S3 for pennies. Or even Neocities or Github Pages for free.
Security.
With no server-side code running, this closes the attack vector for things
like SQL injection attacks.
Of course, everything is a tradeoff—and I’m sure you are conjuring up an argument that one simply couldn’t write an Uber competitor in static HTML. But even THAT has become possible! The recent release of the Beaker Browser has seen the appearance of a Twitter clone (called Fritter[6]), which is written ENTIRELY IN DUN-DUN STATIC JS AND H.T.M.L!!
Many think the Beaker Browser is all about the ‘decentralized Web’. Yeah, uh, in part. Sure, there are many that want this ‘d-web’—I imagine there is some crossover with the groups that want grassroots, localized mesh networks—for political reasons, speech reasons, maybe Mozilla wants a new buzzword, maybe out of idealism or (justified!) paranoia. And maybe it’s for real.
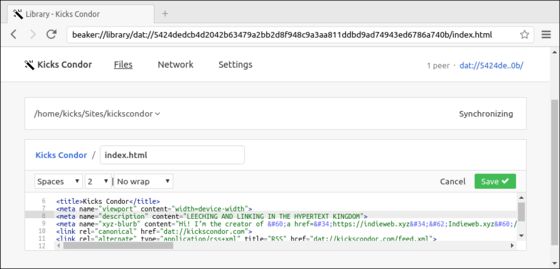
No, my friends, Beaker marks a return of the possibility of a read-write Web. (I believe this idea took a step back in 2004 when Netscape took Composer out of its browser—which at that time was a ‘suite’ you could use to write HTML as well as read it.) Pictured above, I am editing the source code of my site right from the browser—but this is miniscule compared to what Beaker can do[7]. (Including Beaker’s dead-simple “Make an editable copy”—a button that appears in the address bar of any ‘dat’ website you visit.)
(And, yes, Twitter has given you read-write 140 chars. Facebook gave a read-write width of 476 pixels across—along with a vague restriction to height. And Reddit gave you a read-write social pastebin in gray-on-white-with-a-little-blue[8]. Beaker looks to me like read-write full stop.)
Now look—I couldn’t care less how you choose to write your mobile amateur Karaoke platform[9], what languages or what spicy styles. But for personal people of the Web—the bloggers, the hobbyists, the newbs still out there, the NETIZENS BAAAHAHAHAHHAAA!—yeah, no srsly, let’s be srs, I think there are even more compelling reason for you.
Broken software is a massive problem. Wordpress can go down—an upgrade can botch it, a plugin can get hacked, a plugin can run slow, it can get overloaded. Will your Ghost installation still run in ten years? Twenty years?
Dynamic sites seem to need a ‘stack’ of software and stacks do fall over. And restacking—reinstalling software on a new server can be time-consuming. One day that software simply won’t work. And, while ‘staticgens’ can break as well, it’s not quite a ‘stack’.
And, really, it may not matter at that point: the ‘staticgens’ do leave you with the static HTML.
The more interesting question is: how long will the web platform live on for? How long will HTML and JavaScript stay on? They have shown remarkable resilience and backward compatibility. I spend a lot of time surfing the Old Web and it’s most often Flash that is broken—while even some of the oldest, most convuluted stuff is exactly as it was intended.
Static HTML is truly portable and can be perfectly preserved in the vault. Often we now think of it simply as a transitory snapshot between screen states. Stop to think of its value as a rich document format—perhaps you might begin to think of its broken links as a glaring weakness—but those are only the absolute ones, the many more relative links continue to function no matter where it goes!
And, if there were more static HTML sites out there, isn’t it possible that we would find less of the broken absolutes?
Furthermore, since static HTML is so perfectly amenable to the decentralized Web—isn’t it possible that those absolute links could become UNBREAKABLE out there??
A friend recently discovered a Russian tortoise—it was initially taken to the Wildlife Service out of suspicion that it was an endangered Desert tortoise. But I think its four toes were the giveaway. (This turtle is surprisingly speedy and energetic might I add. I often couldn’t see it directly, but I observed the rustling of the ivy as it crawled a hundred yards over the space of—what seemed like—minutes.)
This friend remarked that the tortoise may outlive him. A common lifespan for the Russian is fifty years—but could go to even 100! (Yes, this is unlikely, but hyperbole is great fun in casual mode.)
This brought on a quote I recently read from Gabriel Blackwell:
In a story called “Web Mind #3,” computer scientist Rudy Rucker writes, “To some extent, an author’s collected works comprise an attempt to model his or her mind.” Those writings are like a “personal encyclopedia,” he says; they need structure as much as they need preservation. He thus invented the “lifebox,” a device that “uses hypertext links to hook together everything you tell it.” No writing required. “The lifebox is almost like a simulation of you,” Rucker says, in that “your eventual audience can interact with your stories, interrupting and asking questions.”
— p113, Madeleine E
An aside to regular readers: Hell—this sounds like philosopher.life! And this has very much been a theme in our conversations, with this line bubbling up from the recent Hyperconversations letter:
I do not consider myself my wiki, but I think it represents me strongly. Further, I think my wiki and I are highly integrated. I think it’s an evolving external representation of the internal (think Kantian epistemology) representations of myself to which I attend. It’s a model of a model, and it’s guaranteed to be flawed, imho (perhaps I cannot answer the question for you because I consider it equivalent to resolving the fundamental question of philosophy).
God, I’ve done a bang-up job here. I don’t think I can find a better argument for static HTML than: it might actually be serializing YOU! 😘
I am tempted to end there, except that I didn’t come here to write some passionate screed that ultimately comes off as HTML dogmatism. I don’t care to say that static HTML is the ultimate solution, that it’s where things are heading and that it is the very brick of Xanadu.
I think where I stand is this: I want my personal thoughts and writings to land in static HTML. And, if I’m using some variant (such as Markdown or TiddlyWiki), I still need to always keep a copy in said format. And I hope that tools will improve in working with static HTML.
And I think I also tilt more toward ‘static’ when a new thing comes along. Take ActivityPub: I am not likely to advocate it until it is useful to static HTML. If it seems to take personal users away from ‘static’ into some other infostorage—what for? I like that Webmention.io has brought dynamism to static—I use the service for receiving comments on static essays like these.
To me, it recalls the robustness principle:
Be conservative in what you do, be liberal in what you accept from others.
In turn, recalling the software talk Functional Core, Imperative Shell—its idea that the inner workings of a construct must be sound and impervious; the exterior can be interchangable armor, disposable and adapted over time. (To bring Magic: the Gathering fully into this—this is our ‘prison deck’.)
Static within; dynamic without. Yin and yang. (But I call Yin!)
Certainly there is an ‘awesome’. But also custom directories, such as staticgen.com and ssg. Beyond that, there are loads of ‘10 best staticgens’ articles on the webdev blogs. ↩︎
A tool that builds a dashboard from static HTML pages. (Think of it: HTML is the database schema??) Anyway: vapid.com. ↩︎
A chat platform built on static files. I do consider this to be in the neighborhood—it can die and still exist as a static archive. See the repo. ↩︎
Build a JSON API with Hugo’s Custom Output Formats, April 2018. ↩︎
If you’re in Beaker: dat://fritter.hashbase.io. ↩︎
The DatArchive API, which any website can leverage if it runs inside of Beaker, allows you to edit any website that you own FROM that same website. A very rudimentary example would be dead-lite. ↩︎
The “gray on white with a little blue” phenomenon is covered in further detail at Things We Left in the Old Web. ↩︎
My apologies—I am pretty glued to this right now. Finally there is a whole radio station devoted to the musical stylings of off-key ten-year-olds and very earnest, nasally Sinatras. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
While Tumblr is a type of blog, I think it is sufficiently different to categorize differently—microblogging, tumblelogging. Simply because it generally eschews writing. And that appeals to people.
So, question for you: are you satisfied with a blog for your approach? It seems that you post links, essays and announcements generally. However, these three things are not equal. And to see your essays roll off the front page while links take their place—well, I can see myself wanting a directory of those.
Yes, you have an ‘article’ post type that shows me those essays. But even that list is not comprised of equals. I wonder if a wiki might suit these.
I also wonder if there is a new way to structure all of these thoughts that might do justice to what you are doing and assist the reader in navigating what you are doing. A way of mixing and matching the ‘blog’, the ‘wiki’ and the ‘directory’.
To me, the great failing of blogs is that it is difficult to find the beginning and the end—and I don’t think they facilitate the ‘memory’ of a discussion. A blog post is a thought balloon floating alone. You and I can follow it pretty well, because we are juggling some memories to do it—but someone who stumbles across this post will not realize what is really going on.
Anyway, this is a great post—I’ve been pretty stumped about how to preserve the wee ‘web page’ and this is a thread we’ll need to continue over time.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.
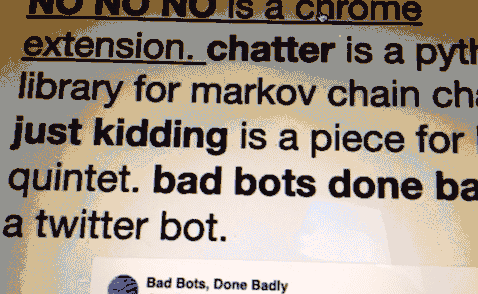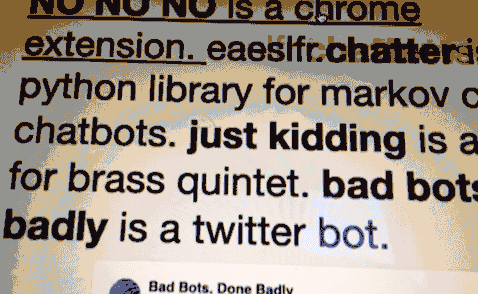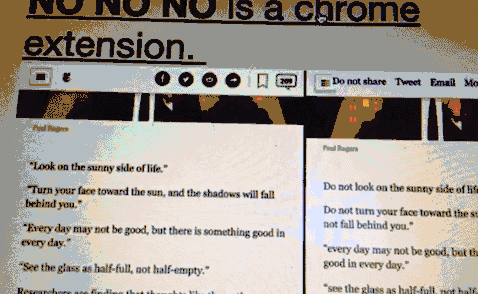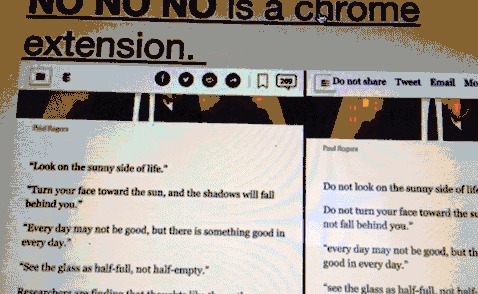

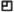






{kind=link}
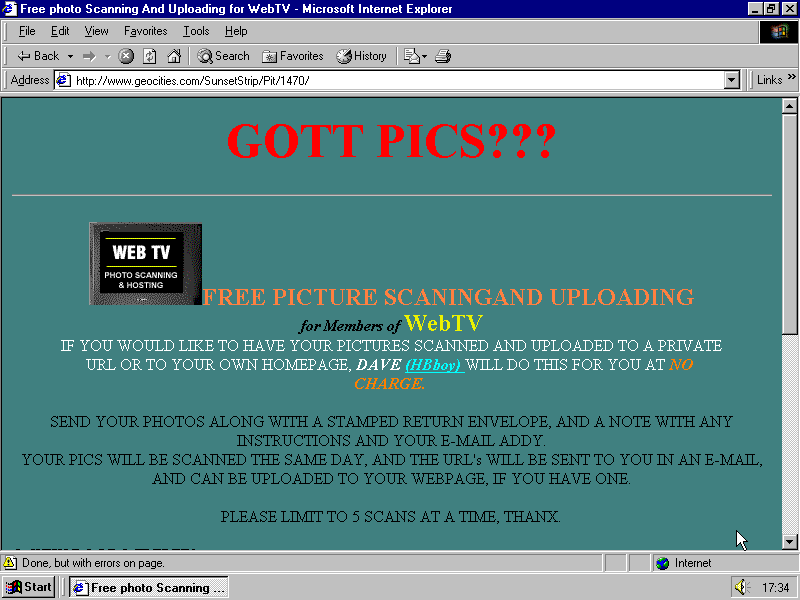{kind=link}
Reply: Losing Sites Not a Biggie
A loss for civilization? Well, yeah, if you put it that way—civilization is going to roll on, regardless. I suppose you could say my effort is misplaced: perhaps better to work on helping our civilization survive, to live on, rather than trying to look to the past.
But, put another way: do I want to preserve a civilization that doesn’t embody any of the ideas that I care about? You’re probably right with your last line there—maybe I consider myself one who has ‘absorbed’ the ideas of my time and wants to ‘move on’ with those ideas in different ways. I can probably do this just fine without ready access to the source material—but I am glad that I was able to show Dont Look Back (1967) to a friend recently, rather than needing to just recount my recollection of it.
Definitely don’t want to save everything. Just some essential bits. And I shouldn’t try to be noble about it—just seems fun.
(And hey—kind of you to write up your thoughts, NK.)