#static
I use three main tags on this blog:
-
hypertext: linking, the Web, the future of it all.
-
garage: art and creation, tinkering, zines and books, kind of a junk drawer - sorry!
-
elementary: schooling for young kids.


#static
I use three main tags on this blog:
hypertext: linking, the Web, the future of it all.
garage: art and creation, tinkering, zines and books, kind of a junk drawer - sorry!
elementary: schooling for young kids.

Uhhh—ANSI graphics inspired cocktail menu?? This looks like a warez NFO.
This Brooklyn (pun?) bar—well, there’s not much to say, just go look: the olde BBS style boxes-and-lines art. This is actually really nice and clean, totally usable in its own way.
On top of this, tho—this is signed ‘jgs’. Are we talking Joan G. Stark??? (Aka Spunk. Also covered here.) I’ve gotta track her down.
Couple other related somewhat-campy genius sites:
But if you’re just in the mood for more ASCII, here’s a little town to visit.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
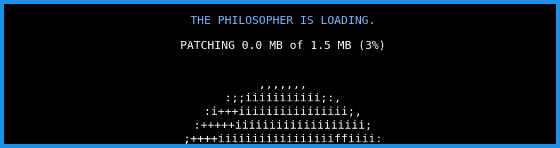
A prototype for the time being.
I’m sorry to be very ‘projecty’ today—I will get back to linking and surfing straightway. But, first, I need to share a prototype that I’ve been working on.
Our friend h0p3[1] has now filled his personal, public TiddlyWiki to the brim—a whopping 21 MEGAbyte file full of, oh, words. Phrases. Dark-triadic memetic, for instance. And I’m not eager for him to abandon this wiki to another system—and I’m not sure he can.
So, I’ve fashioned a doorway.
This is not a permanent mirror yet. Please don’t link to it.

Yes, there is also an archive page. I took these from his Github repo, which appears to go all the way back to the beginning.
Ok, yes, so it does have one other feature: it works with the browser cache. This means that if you load snapshot #623 and then load #624, it will not reload the entire wiki all over again—just the changes. This is because they are both based on the same snapshot (which is #618, to be precise.) So—if you are reading over the course of a month, you should only load the snapshot once.
Snapshots are taken once the changes go beyond 2 MB—though this can be tuned, of course.
Shrunk to 11% of its original size. This is done through the use of judicious diffs (or deltas). The code is in my TiddlyWiki-loader repository.
I picked up this project last week and kind of got sucked into it. I tried a number of approaches—both in snapshotting the thing and in loading the HTML.
I ended up with an IFRAME in the end. It was just so much faster to push a 21 MB string through IFRAME’s srcdoc property than to use stuff like innerHTML or parseHTML or all the other strategies.
Also: document.write (and document.open and document.close) seems immensely slow and unreliable. Perhaps I was doing it wrong? (You can look through the commit log on Github to find my old work.)
I originally thought I’d settled on splitting the wiki up into ~200 pieces that would be updated with changes each time the wiki gets synchronized. I got a fair bit into the algorithm here (and, again, this can be seen in the commit log—the kicksplit.py script.)
But two-hundred chunks of 21 MB is still 10k per chunk. And usually a single day of edits would result in twenty chunks being updated. This meant a single snapshot would be two megs. In a few days, we’re up to eight megs.
Once I went back to diffs and saw that a single day usually only comprised 20-50k of changes (and that this stayed consistent over the entire life of h0p3’s wiki,) I was convinced. The use of diffs also made it very simple to add an archives page.
In addition, this will help with TiddlyWikis that are shared on the Dat network[2]. Right now, if you have a Dat with a TiddlyWiki in it, it will grow in size just like the 6 gig folder I talked about in the last box. If you use this script, you can be down to a reasonable size. (I also believe I can get this to work directly from TiddlyWiki from inside of Beaker.)
And, so, yeah, here is a dat link you can enjoy: dat://38c211…a3/
I think that’s all that I’ll discuss here, for further technical details (and how to actually use it), see the README. I just want to offer help to my friends out there that are doing this kind of work and encourage anyone else who might be worried that hosting a public TiddlyWiki might drain too much bandwidth.
philosopher.life, dontchakno? I’m not going to type it in for ya. ↩︎
The network used by the Beaker Browser, which is one of my tultywits. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Thinking harder about the surprising return of static HTML.
Static website and blog generators continue to be a very solid and surprising undercurrent out there. What could be more kitschy on the Web than hand-rolled HTML? It must be the hipsters; must be the fusty graybeards. Oh, it is—but we’re also talking about the most ubiquitous file format in the world here.
Popular staticgens sit atop the millions of repositories on Github: Jekyll (#71 with 35.5k stars—above Bitcoin), Next.js (#98 with 29.3k stars, just above Rust), Hugo (#118 with 28.9k stars). This part of the software world has its own focused directories[1] and there is constant innovation—such as this week’s Vapid[2] beta and the recent Cabal[3].
And I keep seeing comments like this:
I recently completed a pretty fun little website for the U.S. freight rail industry using Hugo […] It will soon replace an aging version of the site that was built with Sitecore CMS, .NET, and SQL Server.[4]
Yes, it’s gotten to the point that some out there are creating read-only web APIs (kind of like websites used by machines to communicate between each other)—yes, you heard that right![5]
Clearly there are some obvious practical benefits to static websites, which are listed time and again:

Fast.
Web servers can put up static HTML with lightning speed. Thus you can endure
a sudden viral rash of readers, no problem.
Cheap.
While static HTML might require more disk space than an equivalent dynamic
site—although this is arguable, since there is less software to install
along with it—it requires fewer CPU and memory resources. You can put your
site up on Amazon S3 for pennies. Or even Neocities or Github Pages for free.
Security.
With no server-side code running, this closes the attack vector for things
like SQL injection attacks.
Of course, everything is a tradeoff—and I’m sure you are conjuring up an argument that one simply couldn’t write an Uber competitor in static HTML. But even THAT has become possible! The recent release of the Beaker Browser has seen the appearance of a Twitter clone (called Fritter[6]), which is written ENTIRELY IN DUN-DUN STATIC JS AND H.T.M.L!!
Many think the Beaker Browser is all about the ‘decentralized Web’. Yeah, uh, in part. Sure, there are many that want this ‘d-web’—I imagine there is some crossover with the groups that want grassroots, localized mesh networks—for political reasons, speech reasons, maybe Mozilla wants a new buzzword, maybe out of idealism or (justified!) paranoia. And maybe it’s for real.
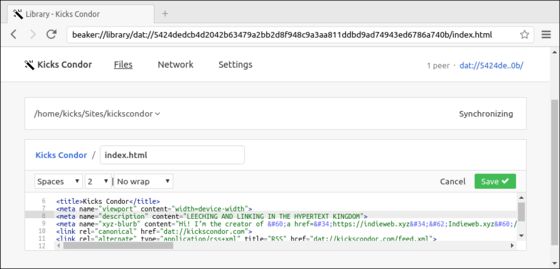
No, my friends, Beaker marks a return of the possibility of a read-write Web. (I believe this idea took a step back in 2004 when Netscape took Composer out of its browser—which at that time was a ‘suite’ you could use to write HTML as well as read it.) Pictured above, I am editing the source code of my site right from the browser—but this is miniscule compared to what Beaker can do[7]. (Including Beaker’s dead-simple “Make an editable copy”—a button that appears in the address bar of any ‘dat’ website you visit.)
(And, yes, Twitter has given you read-write 140 chars. Facebook gave a read-write width of 476 pixels across—along with a vague restriction to height. And Reddit gave you a read-write social pastebin in gray-on-white-with-a-little-blue[8]. Beaker looks to me like read-write full stop.)
Now look—I couldn’t care less how you choose to write your mobile amateur Karaoke platform[9], what languages or what spicy styles. But for personal people of the Web—the bloggers, the hobbyists, the newbs still out there, the NETIZENS BAAAHAHAHAHHAAA!—yeah, no srsly, let’s be srs, I think there are even more compelling reason for you.
Broken software is a massive problem. Wordpress can go down—an upgrade can botch it, a plugin can get hacked, a plugin can run slow, it can get overloaded. Will your Ghost installation still run in ten years? Twenty years?
Dynamic sites seem to need a ‘stack’ of software and stacks do fall over. And restacking—reinstalling software on a new server can be time-consuming. One day that software simply won’t work. And, while ‘staticgens’ can break as well, it’s not quite a ‘stack’.
And, really, it may not matter at that point: the ‘staticgens’ do leave you with the static HTML.
The more interesting question is: how long will the web platform live on for? How long will HTML and JavaScript stay on? They have shown remarkable resilience and backward compatibility. I spend a lot of time surfing the Old Web and it’s most often Flash that is broken—while even some of the oldest, most convuluted stuff is exactly as it was intended.
Static HTML is truly portable and can be perfectly preserved in the vault. Often we now think of it simply as a transitory snapshot between screen states. Stop to think of its value as a rich document format—perhaps you might begin to think of its broken links as a glaring weakness—but those are only the absolute ones, the many more relative links continue to function no matter where it goes!
And, if there were more static HTML sites out there, isn’t it possible that we would find less of the broken absolutes?
Furthermore, since static HTML is so perfectly amenable to the decentralized Web—isn’t it possible that those absolute links could become UNBREAKABLE out there??
A friend recently discovered a Russian tortoise—it was initially taken to the Wildlife Service out of suspicion that it was an endangered Desert tortoise. But I think its four toes were the giveaway. (This turtle is surprisingly speedy and energetic might I add. I often couldn’t see it directly, but I observed the rustling of the ivy as it crawled a hundred yards over the space of—what seemed like—minutes.)
This friend remarked that the tortoise may outlive him. A common lifespan for the Russian is fifty years—but could go to even 100! (Yes, this is unlikely, but hyperbole is great fun in casual mode.)
This brought on a quote I recently read from Gabriel Blackwell:
In a story called “Web Mind #3,” computer scientist Rudy Rucker writes, “To some extent, an author’s collected works comprise an attempt to model his or her mind.” Those writings are like a “personal encyclopedia,” he says; they need structure as much as they need preservation. He thus invented the “lifebox,” a device that “uses hypertext links to hook together everything you tell it.” No writing required. “The lifebox is almost like a simulation of you,” Rucker says, in that “your eventual audience can interact with your stories, interrupting and asking questions.”
— p113, Madeleine E
An aside to regular readers: Hell—this sounds like philosopher.life! And this has very much been a theme in our conversations, with this line bubbling up from the recent Hyperconversations letter:
I do not consider myself my wiki, but I think it represents me strongly. Further, I think my wiki and I are highly integrated. I think it’s an evolving external representation of the internal (think Kantian epistemology) representations of myself to which I attend. It’s a model of a model, and it’s guaranteed to be flawed, imho (perhaps I cannot answer the question for you because I consider it equivalent to resolving the fundamental question of philosophy).
God, I’ve done a bang-up job here. I don’t think I can find a better argument for static HTML than: it might actually be serializing YOU! 😘
I am tempted to end there, except that I didn’t come here to write some passionate screed that ultimately comes off as HTML dogmatism. I don’t care to say that static HTML is the ultimate solution, that it’s where things are heading and that it is the very brick of Xanadu.
I think where I stand is this: I want my personal thoughts and writings to land in static HTML. And, if I’m using some variant (such as Markdown or TiddlyWiki), I still need to always keep a copy in said format. And I hope that tools will improve in working with static HTML.
And I think I also tilt more toward ‘static’ when a new thing comes along. Take ActivityPub: I am not likely to advocate it until it is useful to static HTML. If it seems to take personal users away from ‘static’ into some other infostorage—what for? I like that Webmention.io has brought dynamism to static—I use the service for receiving comments on static essays like these.
To me, it recalls the robustness principle:
Be conservative in what you do, be liberal in what you accept from others.
In turn, recalling the software talk Functional Core, Imperative Shell—its idea that the inner workings of a construct must be sound and impervious; the exterior can be interchangable armor, disposable and adapted over time. (To bring Magic: the Gathering fully into this—this is our ‘prison deck’.)
Static within; dynamic without. Yin and yang. (But I call Yin!)
Certainly there is an ‘awesome’. But also custom directories, such as staticgen.com and ssg. Beyond that, there are loads of ‘10 best staticgens’ articles on the webdev blogs. ↩︎
A tool that builds a dashboard from static HTML pages. (Think of it: HTML is the database schema??) Anyway: vapid.com. ↩︎
A chat platform built on static files. I do consider this to be in the neighborhood—it can die and still exist as a static archive. See the repo. ↩︎
Build a JSON API with Hugo’s Custom Output Formats, April 2018. ↩︎
If you’re in Beaker: dat://fritter.hashbase.io. ↩︎
The DatArchive API, which any website can leverage if it runs inside of Beaker, allows you to edit any website that you own FROM that same website. A very rudimentary example would be dead-lite. ↩︎
The “gray on white with a little blue” phenomenon is covered in further detail at Things We Left in the Old Web. ↩︎
My apologies—I am pretty glued to this right now. Finally there is a whole radio station devoted to the musical stylings of off-key ten-year-olds and very earnest, nasally Sinatras. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
In my Href Hunt, I mentioned this intriguing article. Now it has appeared, a beckoning ghost single as it were. (via Peter.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.