#linking
I use three main tags on this blog:
-
hypertext: linking, the Web, the future of it all.
-
garage: art and creation, tinkering, zines and books, kind of a junk drawer - sorry!
-
elementary: schooling for young kids.


#linking
I use three main tags on this blog:
hypertext: linking, the Web, the future of it all.
garage: art and creation, tinkering, zines and books, kind of a junk drawer - sorry!
elementary: schooling for young kids.

The zine is back for season two.
God, it’s weird writing on this blog - it doesn’t feel the same. Something has happened to it. I can’t seem to get this post to get through. (I also keep getting e-mail that’s like, “Why can’t I connect to kickscondor.com any more?” But I just fixed it!)
Meanwhile, I’m trying to get word out on Whimsy.Space Volume II, Episode II: Thinking Machines // Fever Dreams.
You dive deep into the crevice and consult the chuds living deep underground. You find a small cave system, filled with chuds. You tell them what happened, and they say that you should be able to escape back home
This remarkable ZineOS continues to be a wondrous source of esoteric Notepad text files. The Spongebob mashup is good. (Also love this one.) This issue also seems to have some AI Dungeon transcripts.
The “Snow” story appears to be a dream of the author’s.
The neighbor lady said she was very disappointed that had I disappeared, because she had been a little bored waiting for me. She had used a piping bag and royal icing to make full-sized furniture and a ropes course while I was gone. I climbed up on the ropes for a little bit, but then they collapsed into a daybed. She had a bunch of other big sculptures and installations. There was a little stuffed animal in the corner, and the neighbor lady said I could eat it. However, when I took a bite out of one of the legs and started to chew it up, I realized that it was super sad to eat this very cute little stuffed animal and so I spit out the leg and apologized. I could tell she hadn’t really wanted me to eat it, even though she was the one to suggested it. I offered to fix it by stitching the leg back on, but she said that she would be happy to do it because she liked that sort of thing. She looked for a needle and I helped her.
I love Whimsy.space because it envisions the zine as a small Hypercard-like application. So while the most common format is a small booklet, I imagine there are endless other shells for the zine concept - a linked series of videos, perhaps even a handful of audio files, an e-commerce store as a zine, a hacked website as a zine, a map or diagram that can be zoomed into, and so on.
Oh and - see also Danielx on Whimsy.Space - an interview from two years ago.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Fraidycat 1.0.7 is out (in the browser and on desktop), major performance improvements.
My appreciation to all of you out there who have been helping with Fraidycat - this last week has been very busy. There are now releases for Mac, Windows and Linux. These don’t sync between computers yet - but I have spent quite a lot of time polishing them up, to prepare for that. The web extension has been running kind of heavy, so I have now made some major improvements to its performance.
If you use Fraidycat in Firefox, the update is already available. I don’t think the Chrome extension will make it through their store until the end of the week.
I haven’t spent much time trying to spread the word on Fraidycat just yet. I am still clawing along until I can reach a quality that I am happy with. I am close. I think I just want to improve the appearance a bit over the next week and see if I can offer something a little less bland.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Fraidycat 1.0.4 is out today in the Firefox and Chrome stores.
Fraidycat 1.0.4 is out - and things are rolling. Much appreciation to all of those who are pitching in ideas on the issues page. Particularly Bauke and Joshua C. Newton - who brought up bugs that I was able to fix in this release. (And apologies about all the noise on this project - I’m excited about it right now and, believe me, I have a variety of things planned over the next month that will take us away from Fraidycat.)
The new version is already approved in the Firefox Add-ons area. The Chrome (and Vivaldi/Brave) extension is still at 1.0.3, but should update automatically very soon. I’ve also started offering a plain zip that you can install manually using these instructions. Auto-updates will not be available - but you will also not be dependent on the official ‘stores’.
This video is also mirrored at archive.org.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
What are blogs for? A trip to the beginning. The halcyon days of dot-com idealism and sheer shit-talking.
Here are my notes on the book We’ve Got Blog: How Weblogs Are Changing Our Culture—a worn-out name, but a pretty decent compilation of blog posts from the early days of the phenomenon, mostly 1999-2002.
The articles in this collection are early reflections on the weblog phenomenon. Mature reflections do not exist: the weblog community coalesced only three years ago. Not even the pioneers—some of whom contributed to this anthology—know where weblogs are going, or what place they will eventually fill on the World Wide Web.
— p. xii, Rebecca Blood
The word ‘weblog’ was coined in 1997 - but I think 1999 was officially the first big year for blogging, with both LiveJournal and Blogger appearing. Somehow, wanting to reach back to that era now that 20 years has passed - to attempt to uncover what went so wrong between then and now - I checked out this book from the library on an impulse. It seems to capture the spirit of that age in such a remarkable way - like that jar of deer meat I recently found in my brother-in-law’s basement labelled: '97. (“Oh, it’s still good,” he said.)
And considering Rebecca’s point above: 20 years later, do ‘mature’ reflections now exist? Is it all over and we’re far beyond reflecting? Has the blog just been a tulpa for some ancient essence that we’ll never capture?
Time to reflect.
For the first fifty pages of this, I felt nothing but self-loathing. Blogging suddenly seemed like the most disgusting thing to do - to aimlessly, carelessly write endlessly about my tastes and interests. While I quite like Rebecca Blood’s analysis in the early chapters, this quote chilled me:
As [the blogger] enunciates his opinions daily, this new awareness of his inner life may develop into a trust in his own perspective. His own reactions - to a poem, to other people, and, yes, to the media - will carry more weight with him. Accustomed to expressing his thoughts on his website, he will be able to more fully articulate his opinions to himself and others. He will become impatient with waiting to see what others think before he decides, and will begin to act in accordance with his inner voice instead. Ideally, he will become less reflexive and more reflective, and find his own opinions and ideas worthy of serious consideration.
— p. 14, Rebecca Blood, “Weblogs: A History and Perspective”
Perhaps Rebecca could really use the confidence boost - and that seems entirely wholesome - but I personally do not need to take myself more seriously. I can definitely appreciate improving my articulation - yes definitely, definitely - but becoming more ‘impatient’ and more opinionated - yet somehow more ‘reflective’? More weighty? I don’t want this to happen… (I think I’d like to remain aware that I’m a perfectly worthless dipshit.)
Any idea that these days of blogging were somehow more idyllic, pleasant or enviable quickly goes out the window in this book. The shit-talking is near-epic! Names are named—denounced and disgraced as ruining the form—mostly deriding “A-list” bloggers, but also decrying “the unbearable incestuousness of blogging.” Seems like the confirmation I’ve needed that mastering hypertext is going to be a formidable challenge for us - one that they were only just beginning to embark on and, therefore, were well over their heads in.
However, so far I’ve found a surprising amount to glom on to. These early bloggers definitely had a whiff of what was to come (partly because many had recently left the experience of Usenet) and I think I’m coming away hugely crystallized. Unexpected!!
The juiciest quote, for me, so far is this one:
‘Accept that the Web ultimately overwhelms all attempts to order it, as for now it seems we must, and you accept that the delicate thread of a personal point of view is often as not your most reliable guide through the chaos. The brittle logic of the hierarchical index has its indispensable uses, of course, as has the crude brute strength of the search engine. But when their limits are reached (and they always are), only the discriminating force of sensibility will do - and the more richly expressed the sensibility, the better.’
— “Portrait of the Blogger as a Young Man” by Julian Dibbell (2000)
This might be a little self-affirming, because it seems to vindicate the web directory (e.g. my l’il href.cool) but what it really seems to be describing is the blog as our premiere discovery mechanism.[1] This must have been a common view at the time, considering this earlier quote:
[…] the weblog movement will begin to realize its true power, a more widely distributed version of what the Open Directory and other collaborative web directories have promised but only minimally delivered.
— p. 40, Brad L. Graham, “Why I Weblog”
In hindsight, this feels like hyperbole - the finished product of a blog seems (to me) less navigable than a directory, although both are usually stale by then. But I think this has played out, to some degree, especially if I think of how useful a good music blog can be when attempting to discover new music. (Though I think a good music podcast or YouTube review can be equally good.)
Hmm. A medium really is only as good as the artist makes of it. It’s not that hypertext is tapping into us. We’re pushing it wherever we want, right?
We are being pummeled by a deluge of data and unless we create time and spaces in which to reflect, we will be left with only our reactions. I strongly believe in the power of weblogs to transform both writers and readers from “audience” to “public” and from “consumer” to “creator.”
— p. 16, Rebecca Blood, “Weblogs: A History and Perspective”
I want to draw a comparison here between this quote and (apologies) Fortnite Battle Royale. Putting aside everything else about Fortnite, it tacked on an interesting innovation: the ability to build structures (in a Minecraft-inspired fashion) with a traditional (third-person) shooter.
Most people seemed to scoff at this blend—as if it were some kind of mere monstrosity of buzzwords. No, this ability to build boxes around yourself or staircases to scale mountains added a much-needed defensive strategy to shooter games, aside from stuff like holing-up or strafing. What’s more: the building strategy can also be seen as ‘shooting’ defenses—you are adding to the environment—it is a constructive, perhaps aggressive, kind of defense.[2]
That’s what seems to resonate with bloggers: not the publication of a first-person journal but the chain of interaction it often ignites.
— p. 170, JD Lasica, “Blogging as a Form of Journalism”
This chain of interaction can manifest as a scorching backdraft. And that is not usually what you are trying to ignite. We like to think that we are kicking off a fantastic, fulfilling discussion that moves the world forward—but the chain is well outside of our control.
(My initial thoughts to ‘controlling’ such a thing is… defensive in the Fortnite sense. Many hypertext writers now build layers around their writing. Nadia Eghbal has direct interaction through Twitter, indirect interaction through polished essays and a newsletter—but also, concealed interaction through an unadvertised notes page that is not easily syndicated or followed. Similarly, representing the public-self modelers—h0p3 has a home page entry point that is carefully curated and groomed, but which is several layers up from a complete chaos of link dumps, raw drafts and random introspections—all of which you can only sort through by learning his curious conventions. You are on his turf. These layers run a spectrum of accessibility—there is always a learning curve before you hit the bottom. You start with a doorway before entering a maze.)
I do think what this has left me with so far is two very clear impressions:
So, while certain writers in this book seemed to look at the blog as a fully-realized literature format - and perhaps it can be that to some - for me, I see it as a conduit between writings and creations - a place where some of my own words fester and pile up, as a kind of byproduct.
Lastly, there’s no question that we are far from a mature view of hypertext. I feel that much of the last two decades has been spent just trying to emotionally process what our open exposure on the Internet means. These bloggers lived during an early expansion when the population was much smaller. The extreme growth (along with stuff like constant mobile connections and the Snowden discoveries) has transformed the Internet into a very public, chaotic place.
Developing a blog/wiki/etc demands writing, editing, publishing and even relationship chops. I’m not even touching the journalism, entrepreneurial and community-building aspects that this book focuses on at times. Trying to do this in a disciplined way is difficult in the changing landscape - partly because so much of our discussion necessarily revolves around examining that landscape.
p. 5. “[so-and-so] grouped a bunch of webloggers into high school cliques and called me a jock” the shit-talking begins, this is comfortable, nothing has changed.
p. 5. “Dave decided I must be ‘brain-damaged’ because I used frames.” first
thought: this is worthy of publication? second thought: oh, wait, these are
raw blog posts republished. third thought: 
Tracked down the Dave Winer post myself, to ensure ‘brain-damaged’ was the actual wording. (It was.) Quote just below it:
Dad says I shouldn’t criticize other people on my site. He’s right, in theory. But in practice, what I don’t like is just as much a part of my personality as what I do like.
— Kate Adams
(Personal aside: I once criticized the cover of a Philip K. Dick book publicly on the Internet. The only response my post receive was from the illustrator that had designed the cover. She basically said: “Thanks, that hurt.” You might think she had no business replying to my post and should have just taken the criticism. But she didn’t like my criticism - which is “just as much a part of her personality” as anything else, I suppose.)
p. 9. Good Rebecca Blood quote: “These weblogs provide a valuable filtering function for their readers. The Web has been, in effect, pre-surfed for them.”
p. 11. There seems to be a recurring theme that Blogger made blogging “too easy” by just having a single textbox to post in. Didn’t realize it was that much of a progenitor to Twitter.
p. 12. Filters as their own thing: “I really wish there were another term to describe the filter-style weblog, one that would easily distinguish it from the blog.”
(No indication of the tools available to the ‘filter’ blog are given - except that it has access to other filter blogs. Also, there are about five different blog types alluded to - none of them matter now.)
p. 18. The author seems to say that communities, in order to survive, must stay small - and credits The WELL with the best approach. I don’t know The WELL - but it’s still here today. Wonder if it is considered intact…
p. 20. The term ‘webpools’ is used here several times. There are many, many outdated terms and awkward language choices in these essays. These are really cool to me because the language was in such flux - and it reminds me of how repulsive the word ‘blog’ was at first. (I invent crappy words, too - guilty.)
p. 27. Having a good ‘link checker’ is mentioned. Interesting that this technology is nowhere to be seen now. (Href.cool has a simple, dumb one I made - but it’s proven essential.)
p. 31. Some discussion about crediting sources. The discussion is basically “this is a virtuous thing to do” vs. “it clutters up the blog”. This misses the point (imho) - the point is to aid discovering related blogs.
p. 32. This is so funny: “But what about a weblog for the homemaker?”
p. 32. “Wouldn’t it be great if all the neurosurgeons in the world had one place to go for up-to-date information about the numerous changes in their field?” No. Hard no.
p. 35. The need for one’s own domain name. I used to think this wasn’t very important. Starting to come around.
p. 37. “fram” - friend spam. This was nostalgic - ahh right, basically, e-mail forwards were the Facebook of that era. Again, recurring theme of: people need to become better, more disciplined independent writers and publishers. That is what the Web asks of us.
p. 43. omgz, a spoof of “we didn’t start the fire” in the middle of the book. “Wetlog, BrainLog, NeoFlux, and Stuffed Dog…” this is amaaazing.
p. 49. beebo.org?? wtf, this is the second time this has come up. “a blog best-seller list”? The captures on Internet Archive do not explain this well enough for me.
p. 51. It’s becoming clear that Blogger was the poster child of its time. Strangely, people don’t really trace the lineage of Twitter or Tumblr back to it - nor does it come up in the Friendster, Myspace, Facebook dynasty. It’s just kind of this useful website that appeared and is still here. Strangely, Google has managed to keep it low-key, ad-less, customizable - seems like a completely ignored utility. There even seems to be a “New Blogger” dashboard for mobile. I wonder what keeps this thing going?
p. 52. Fears about blogging becoming “too easy” - leading to “blogorrhea”. Yeah, that panned out.
p. 54. The Bicycle story. This seems like some kind of a precious take on memes. Or, alternatively, a satire on a template blog post. The self-loathing returns.
p. 59. Damn, this is serious shit-talking!! (Like on the level of Bernhard’s The Woodcutters.) I need to talk about this in more detail later.
p. 68. Blogs as “exteriorized psychology”. Sure. But no. Hard no.
p. 70. Where did Jorn Barger go? Seems like perception that he was antisemitic turned against him? Nah, it’s got to just be burn out or something. Everyone should retreat from the pulpit at some point. (Actually, not sure why I’m asking where he is - most of these blogs are vacated. I think people didn’t want out of blogging what it ended up giving them. There was definitely something of a gold rush.)
p. 76. This Julian Dibbell has some good stuff. “Does it even count as irony that Barger’s rigorously unfiltered perspective is perhaps as good a filter as can be found for the welter of the Web?” This is a good question! And it really confuses the topic of what makes a good algorithm or a good editor. The discussion kind of stops at: it’s a sensibility.
p. 78. Blogger was a one-man business in 2001 after initially having a team. It really squeaked by. This is cool. It actually survived.
p. 82. “I do think there was a blog concept. Then there were a couple blog concepts. And now we’re getting closer to a blog concept again.” Lol. I think we’re back to a couple blog concepts again.
p. 87. Comment about 2001’s “p2p hype” drowning out interest in blogs. It’s interesting that blockchain took that space for awhile. And it’s interesting that some p2p+blog projects have a niche community now. It’s also interesting that those were seen as competing at the time - I can see how people would think that, but those were clearly two different crowds.
p. 89-98. No real interest in this chapter (on the Kaycee Nicole Hoax) - although veracity of information continues to be a big topic. Was a topic in the radio and newspaper eras, too.
p. 103. “[Blogs are] nothing new, they’re not changing the world with their content, they’re not going to make anyone huge amounts of money, but they are a form of self-expression and community which others enjoy reading.” (Finally, some tempered enthusiasm that’s grounded in reality. No one in this book even considers that blogs might have been a fad - which is a reasonable appraisal given that blogs have almost vanished within the past ten years.)
p. 112-115. An actual essay on link-hunting! It’s rather thin, but it’s a good start. Most of the sources listed in this article are gone now. (Except mailing lists - though they aren’t nearly as prevalent.)
p. 124. “linkslut” (Sick, this is me.)
p. 131. “… most popular weblogs function to serve up the piddle and crap the authors either don’t have time for, don’t believe worth taking any further, or perhaps are testing the waters for.” (So: people know they are writing for free and withhold their best work. Really makes me grateful for insanely high-quality essayists out there like Nadia or Toby.)
p. 138. Kottke is a serious target in this book. He is quoted here, talking about his laptop bag. The writer then basically says, “See, this is the epitome of decadent navel-gazing.”
p. 141. This Blogma 2001 stuff hasn’t aged well. The satire is just thinly veiled bile. Which is not a problem. It’s just that the target of this piece (“A-list” bloggers) is not interesting. Maybe it’s too easy. (Like a satire on modern influencers - who cares.)
p. 144. In a section on blogging tips, called “Anonymous Is Okay.” ‘If you are being
anonymous give some hints about you from time to time. “I am a fat boy!”’ 
p. 152. This has really gone downhill in the last few chapters. I’m now in an essay on how to get noticed. “Also, when sending email, try to be funny” - oh boy. And yet, this is exactly what you expect in a book titled We’ve Got Blog from 2002. (This essay does highlight that self-promotion was very awkward even then.)
p. 155. “Once in a while remind yourself that you are not only as good as your last update.” (Based.)
p. 164. Referring to a time in the late 90s: “Then reality set in and those individual voices became lost in the ether as a million businesses lumbered onto the cyberspace stage, newspapers clumsily grasped at viable online business models, and a handful of giant corporations made the Web safe for snoozing.” (Had to do a double-take on this one! Were they talking about 2011?)
p. 166. Reference to Paul Andrews’ “Who Are Your Gatekeepers?” Sounds worth reading.
p. 166. “Where the weblog changes the nature of ‘news’ is in the migration of information from the personal to the public.” (Premonitions of Snowden. Regardless of whether you think he was successful, in this respect he certainly was.)
p. 167. The rest of the essays in this book are by amateurs, so they look at editors at entirely superfluous. This section is written by journalists, so they seem to see it just as a tradeoff. Yeah, for sure. (As a reader, it certainly seems valuable to evaluate online writing on a spectrum of heavily-edited and fact-checked vs. off-the-cuff - depending on what you are getting out of it.)
p. 170. “One of the most interesting things about blogs is how often they’ve made me change my mind about issues. There’s something about the medium that lets people share opinions in a less judgemental way than when you interact with people in the real world.” (Eh? This seems spurious. The medium is still just the written word. I think what you’re trying to articulate is that you never quite know what you’re going to end up reading online - so it’s possible to be exposed to arguments you haven’t encountered. Hence all the talk about people being accidentally radicalized politically.)
p. 170. “That’s what seems to resonate with bloggers: not the publication of a first-person journal but the chain of interaction it often ignites.” (Yes. Hard yes. This explains the migration to social media. Quicker, faster, immedate sparks of interaction.) (It also occured to me at this point that ‘likes’ and such are analagous to ‘hit counters’ from this age.)
p. 171. The editorial process produces writing that is “limp, lifeless, sterile, and homogenized”; blogs produce words that are “impressionistic, telegraphic, raw, honest, individualistic, highly opinionated and passionate, often striking an emotional chord.” (I really don’t like that this paints a picture that writing just got better all of the sudden because of blogs.)
p. 192-193. During an essay which completely demolishes the war blogs of the time, Tim Cavanaugh quotes a full page-and-a-half of shameless gladhanding. ("…the consistently correct Moira Breen." “Mark Steyn—this guy is so good!” “…Natalija Radic really hit them where it hurts.”) (It goes on and on. This seems similar to current questions of ‘virtual signaling’. Which I don’t have a problem with generally. Really: what should a personal signal? I think the problem here is that the concept of a war blogger is gross. So perhaps it is the incompatibility we see between a person and their signal.)
p. 195. “For all the bitching they log about the mainstream media, none of the bloggers are actually cruising the streets of Peshawar or Aden or Mogadishu. Thus, they’re wholly dependent upon that very same mainstream media.” (Well, the mainstream will always exist in some way - as a baseline of culture, as a central point of reference, like Magnetic North. Therefore, we’re dependent on it. And we move ourselves around it by defining our various loves and hatreds of it. And, in this case, I think it should still be safely used as a resource. Also, ‘it’ is actually a massive, pluralistic, infinite, incongruous organism.)
p. 228. ICQ as “I seek you.” Durrrr. I never caught this! Wowwww. 
Definitely in the way Joe Jennett or Eli Mellen does it—and also h0p3’s link logs. I think tumblelogs and Delicious innovated in this department. ↩︎
Many shooters allow you to project or throw force field areas. So this concept has been around, to some degree. I don’t know the lineage—I’m not a gamer. ↩︎
A few days after writing this, Nadia posted “Reimagining the PhD”, which casts her last five years as a kind of self-styled doctorate - which will now concluded with her publication of a book on her field of study. ‘Rolling up’ a blog into a formalized work is parallel. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Promised I’d do this after getting Fraidycat out there. This regular feature is back: me hunting in the brambles, coming back up with 22 newly discovered blogs from a variety of sources, mainly 8 threads and blogrolls out there. Raw dump. Good quality.
Promised I’d do this after getting Fraidycat out there. This regular feature is back: me hunting in the brambles, coming back up with 22 newly discovered blogs from a variety of sources, mainly 8 threads and blogrolls out there. Raw dump. Good quality.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘Accept that the Web ultimately overwhelms all attempts to order it, as for now it seems we must, and you accept that the delicate thread of a personal point of view is often as not your most reliable guide through the chaos. The brittle logic of the hierarchical index has its indispensable uses, of course, as has the crude brute strength of the search engine. But when their limits are reached (and they always are), only the discriminating force of sensibility will do - and the more richly expressed the sensibility, the better.’
— “Portrait of the Blogger as a Young Man” by Julian Dibbell (2000)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Gabby Lord’s tiny directory—a perfect example of what (I feel) the Web needs!
Often when designers make home pages, they throw out a bunch of cool CSS tricks and aesthetic trimming and I celebrate that—but often there’s not much there in the way of interesting hypertext stuff. In this case, Gabby Lord’s OMGLORD has a nice minimalist design that frames a solid personal directory of links. There’s clearly been a lot of work done here—probably 200 links with nice descriptions and her own set of categories—stuff like ‘type foundries’ and ‘women in design’. I had a lot of fun coming up with categories for href.cool and I think she’s got a great organization here—also, starring her most recommended links is sweet.
I also think her City Maps category is reaaaally cool! She links to Google Maps that she’s personally annotated with sights, parks, coffee shops. These are directories within the directory. In addition, it’s a really nice way to build a directory of real-life stuff.
If you have any distaste for algorithmic recommendation engines or the commercialization of the Internet, I urge you to make a tiny directory! Gabby’s directory is just her favorite cool links—it’s not influenced by advertiser money or link popularity—except that perhaps Gabby discovered some of these through those kinds of avenues—these links have proved worthwhile to her over time. You may feel some resistance sifting through her pages, because why am I looking through a personal page when I could reading a slick major publication or wielding a powerful search engine but you will find things here directly, person-to-person, with no ulterior motives between you and these links.
It’s great, right?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
CRT blog of odd things—and its connection to philatelicism.
(First, let me mention that I obtained the directions to the Cardhouse ‘website concept’ from a massive linkspill that is seeping out on this thread on Metafilter. It is a long list of blogs that have been running for ~20 years. It’s very helpful if you are curious what ‘classic’ blogs are still alive.)
While this is a very interesting blog on its own, I am particularly interested in a few pages for a few reasons:
History: A long, illustrated self-history of the blog that is almost like a time capsule on a single page. It catalogs the snapshots of the design—it’s surprising that more sites don’t do this. Perhaps because it’s perceived as navel-gazing? I think it reflects the rest of the Web, too, though.
Phoneswarm: A sub-blog covering unusual telephone booths. Also: X Magazine, Macros2000. I like that these temporary projects are littered throughout the site—they are fun to explore on their own, partly because they are done.
The Archive: Seems haphazard, but is actually very well done. A directory—similarly, the links page is the old ‘portal’ style directory. Which seems like it could be revived as well.
A secondary site The Erstwhile Philatelic Society is also really cool. It is best explained by the application for membership.
From the FAQ:
- What is with the vert|ical ba|rs in the mid|dle of words?
The problem with search engines is that they allow people to key on words that have nothing to do with the larger web page. People are coming to pages for the wrong reasons – by splitting up certain words in certain pages, people won’t mistakenly come to these pages. That’s the theory, anyway. Apparently there is a rag-tag effort to get this sort of functionality parameterized for search engines, but I fell asleep halfway through the article.
This is good technology.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
My digichat with @nayafia—an essential writer (imho) of texts, notes and wonderful roundups.
A few months ago, I stumbled across the essay ‘The tyranny of ideas’ and was truly struck by the inquisitive, thought-mashing flow of the writing. It’s just a great piece—I’ve read it several times now and talked about it with pretty much everyone I know. The author, Nadia Eghbal, writes quite a bit about funding open source software[1], but meanders all over, processing modern life on her website.
> Welcome to the digichat with Nadia.
kicks: You have a simple, minimalist blog—very limited styling, an RSS feed, generated with Jekyll—meaning you likely write all your posts in a plain text editor. What appealed to you about a minimalist design?
nadia: Before I started writing, I really liked blogs like Aaron Swartz’s and Paul Graham’s, which were minimally designed. If it’s a blog post, I generally don’t want to do anything that takes away from the text itself. It’s like when you cook a really nice piece of fish or steak or whatever: if the main ingredient is good, you shouldn’t need to season it.
kicks: You are also pretty sparse with your linking, image embedding, all the ‘hypertext’ features of the Web. I take it that your faith in plain text doesn’t extend to these?
nadia: Not sure I understand the q, but yes, I like keeping everything pretty sparse. I do like linking a lot (or at least I feel like I link a lot!) as a way of subtly saying “if you wanna dig into this thing more, you can go down this path over there, but otherwise I’m gonna keep talking”.
kicks: You have a page on your site for somewhat ephemeral thoughts and unpolished shorthand. This page has no feed, so it doesn’t actively broadcast—it could almost be seen as a neat personal touch to your website. However, you are incredibly active in updating this! Much more so than your Twitter account it seems. What motivates you to write there?
nadia: I like being able to publish my messier, half-formed thoughts, but I get turned off by putting those next to a like count. It feels like the more likes you get, the more you start writing things to get likes, whereas the REALLY weird, unpopular stuff probably won’t get many likes at all.
I worry about likes changing how I think and interfering with my ability to wander and explore the edges. (I am truly envious, however, of people who are able to use Twitter as a place to braindump their thoughts! I think I’m just too self-conscious.)
Someone (I think Eugene Wei?) once tweeted that all Twitter accounts eventually sound like fortune cookies. I don’t want to become a fortune cookie. So I like things like newsletters, and my notes page, which are still discoverable and semi-public, but aren’t subject to short feedback loops. I also removed comments on my blog for the same reason, and I never look at my site analytics.
kicks: This is making me seriously reconsider ‘likes’—which I’ve let pass as a kind of low-effort but benign and gracious comment. But now as I look at your ‘notes’ page—not only am I convinced by what you’ve said—I think the absence of all the ‘share’/‘like’ icons really makes that page feel like a running conversation. With ‘like’ counts, I think I’d be distracted wondering which thoughts were the most highly admired—but, come on, what kind of bullshit is that for me to be thinking while looking through your private thought journal?? So maybe it alters reading too in a sick way?[2]
nadia: The problem with likes is it naturally draws your eye towards the most-liked stuff, instead of deciding for yourself what’s most interesting. It almost feels like I’d be taking agency away from the reader by doing that.
(Maybe I’m being a little sanctimonious—e.g. shorter thoughts probably draw ppl’s attention more than bigger paragraphs, there’s no way to totally avoid this problem—but I’d rather not add to it, either.)
I mean I think curation can be useful, e.g. on my homepage I highlight a couple of my favorite blog posts, because I assume they want a bit of guidance at that point. But on a stream-of-consciousness notes page, I’m assuming they’re more in exploratory, serendipity mode. I don’t want to guide them towards anything.
kicks: Ok, now: about the essays. The quality of your writing on your blog is very good, very thought-provoking and unique. Serious time has been invested into each essay. I imagine there is a wealth of publications who would love for you to write for them. Why post these to a personal blog?
nadia: Thanks! I like what Venkatesh Rao has to say about Ribbonfarm, which he thinks of as a wildlife preserve. I like having total freedom on my blog to roam around and write about whatever I want, as much or as little as I want. It’s like the popularity metrics thing: if I start writing for others, I worry it’d start to change what I think and write about.
That said: I do like writing for other publications and blogs occasionally! It’s just a very different experience, and I usually need to have a particular reason for doing it.
kicks: You know, your link to Ribbonfarm there has illustrated what you are saying so well. I’ve never really read that blog—but what better way to find it than in this chance conversation with you? (We’re enjoying ‘sidewalk life’ here—as you term it.)
nadia: Woot! Ribbonfarm is lifechanging, I’m a bit of a fangirl.
kicks: I mean the world is trying so hard to build technology that will have these conversations for us. Especially these ones where we find each other. At the same time, it feels like there is more to talk about than ever. Do you feel this way? Or, I mean—you’ve already written pretty extensively—do you still feel like you’re at the tip of the iceberg?
nadia: I definitely feel like I’m at the tip of the iceberg. There are so many half-written blog posts waiting for me to finish, and at some point I’ve realized I’ll never get to them all. And having meaningful conversations is a really tough thing to scale, too. I’m still trying to figure that one out.
kicks: To what degree do you feel like you need to repeat yourself? Because some important points are worth harping on, right?
nadia: I hate repeating myself. haha. This is maybe one of my biggest weaknesses. Part of why I blog is honestly just to avoid repeating myself; if I’ve talked about an idea with enough people separately, I want to codify it into a post and be done with it. I get really impatient about having the same conversations with multiple people. But to your point, important points do need to be repeated, which helps them spread and sink in. It’s just my least favorite thing.
kicks: Does it ever feel like your blog is out in the middle of nowhere? Or do you feel sufficiently connected to the rest of the network out there?
nadia: Haha yes, I definitely feel that way sometimes, although usually I find it comforting—sort of a “hidden in plain sight” kind of thing. Twitter and newsletter are basically my only ties between my blog and the outside world; that said, I think I’ve gotten a surprising amount of engagement that way.
Fundamentally, I think of my blog more like a portfolio, or a display case. It’s not about juicing up my readership, but connecting with the right people who happen upon it and find something that resonates. I’ve met so many amazing people through writing: I’ve gotten most of my work opportunities that way, and made a lot of friends, too! I’ve thought about whether I should focus more on distribution, but again, I think if I started to worry about that, it would make the whole experience less fun, and I might also start changing what I write about. Maybe it’s naive, but I like the idea of having a public place for my “pure” thoughts, and the only way I can think to do that is by explicitly not caring about who reads it or how it spreads around.
kicks: Well, I think you’re playing a long game here—by not cashing in on the immediate attention and likes of those networks. It’s definitely ‘purifying’ to drain away all those other purposes that could be tweaking your motives.
A home page definitely seems more and more inert—disconnected from society, from live notifications, seemingly deserted. But there’s an advantage to that—it’s like you can actually control the tempo there. It’s like visiting you at your home—down a wooded road—or, maybe more appropriately: your candy store, like the one you mention in “Reclaiming Public Life,” where “one is free to either hang around or dash in and out, no strings attached.”
nadia: I love this imagery of a homepage being like visiting a home down a wooded road.
I am definitely the recluse living in a cabin 
kicks: I wish it was more like a candy store, though—so I could hang out and meet another avid reader or give you a thanks as the door jingles on my way out. What is an adequate ‘social’ sidewalk for your blog—is it your attached Twitter account and email newsletter?
nadia: Yeah, Twitter is probably the “social sidewalk” for my blog. I’m still trying to figure out the newsletter thing. When I send out a newsletter, I get a bunch of responses from subscribers, but it feels inefficient somehow to have multiple 1:1 conversations with different people, when I’m sure others would love to read them. I’d almost even say it feels selfish…like I’m keeping all these ideas to myself! Occasionally I include some of the interesting stuff in the following newsletter, but yeah, I don’t like being the bottleneck keeping everyone apart from each other. I haven’t come up with a better alternative besides Twitter, but not everyone is active there.
I guess that’s why some blogs have comments. I was so anti-comments in the past bc it felt like “the comments section”, as a place, had become so crappy and low-quality. It’d be funny if comments sections made a retro comeback as a place to have deeper, substantive conversations. Or maybe they never went away, but I’m the one who’s coming back around to them. (Are newsletters are just the slow re-invention of blogs?)
kicks: Hahaha! I believe this is the first time I’ve heard a remark in possible favor of comments. Yes, I think it is. It’s possible you’ve unearthed the first truly contrarian thought on the Internet here… Which is especially ironic because we’ve just been deriding ‘likes’ somewhat.
Ok, I’ll stop there. Thank you for all that you are doing, Nadia!
nadia: Thank you for all your delightful and thoughtful observations! Really enjoying your trains of thought.
Oh and the fortune cookie remark is too good! It reminds me of something David Yates recently said to me: that there needs to be a name for that feeling where you click on a link to a sweet domain name and it ends up just being another Mastodon instance. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This writer/game designer’s home page is full of interesting hypertext flourishes.
This link was passed on to me by David Yates a while ago and I’ve finally had some time to explore it further. And it turns out there are quite a few interesting uses of links and layout that could be useful to anyone out there who is designing a TiddlyWiki[1]—for instance, the detailed organization of Adam’s favorite songs and albums page or the multiple views for the archives of the blog (called the ‘calendar’—which has been around since the 1990s.)
One of my favorite little touches is the presence of mouseover boxes throughout the essays in the ‘calendar’. In the small screenshot above, you can see a spoiler rating mouseover shown on the Stranger Things review. But there are footnotes, images, even short videos that will pop up when you hover over certain dotted links. (These remind me of the footnotes and links on philosopher.life—but with more effort put into designing them—they may have unique colors or borders.)
More than anything, this highlights again the range of things you can do with a website that just isn’t possible on social networks or Medium blogs—perhaps only an app of some kind could be customized like this.
The site also brought to mind this quote from the recent ‘Writing HTML in HTML’ article:
But how can I then keep the style and layout of all my posts and pages in sync?
Simple: don’t! It’s more fun that way. Look at this website: if you read any previous blog post, you’ll notice that they have a different stylesheet. This is because they were written at different times. As such, they’re like time capsules.
Like Phil Gyford’s site, the pages throughout Adam’s site often each have unique designs which hearken to the author’s style and sensibilities during the time when they were created. I feel like websites like this have fallen out of favor—but access to these old designs is now full of nostalgia—so perhaps we will see more hand-crafted HTML in the same way that we now see a TON of wonderful Windows 95 ripoffs in web design and gaming.
And, if you are, you should really be checking out the recent ‘outrun’-colored tags and tighter design on sphygm.us. Or the erratic page-filling that is happening on chameleon’s wiki. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
If you want to make yourself a tiny directory, it can be this easy…
So this is one of the closest things I’ve seen to my href.cool directory—a big page of bookmarks, assorted ‘interesting’ reads all listed together under some ad-hoc categories (biographies, celebrity, war). And, perhaps more importantly, little blurbs for each one that are really well-done, in that they convey a lot of ‘feeling’/‘synopsis’—I actually enjoy just reading the whole page, to get a sense of this person and what’s out there in topics that may not appear to interest me on the surface.
I think I want to make the argument that building a directory like this is a more, I don’t know, ‘worthwhile’ effort than just leaking out links here and there as you find them. This is a great thing for ‘hypertext’ or a ‘website’ to aspire to be.
A few thoughts:
The page says ‘March 17, 2016’—does this mean the page hasn’t been updated since then? This must be wrong—there’s a link with ‘2017’ in the title.
There’s a bullet point in the ‘sex’/‘gender’ topic that just says: ‘Economics of sex’ with no links. Wonder what’s up there? A placeholder?
Reading this has made me realize that I think I need domain names displayed next to the link. It would be nice to know where the link goes before you hover it. (And mobile doesn’t have this option.)
I also really like this person’s 1,000,000 words project. 1,000 essays of 1,000 words. This one functions like a mini-directory as well, actually—like a mind map or… well, there are links in there as well. It’s sort of like if you could browse a portion of h0p3’s wiki as a linear, chronological conversation.
I hope you’re getting some ideas now.
UPDATE: Hold up, wait, wait—this is rich: visakanv.com/blog/communities/. A kind of hybrid ‘directory’/‘blogpost’ strictly on moderating and building communities.
It is my experience that, if you create a safe space for a minority group, sparing them the stress of having to explain themselves to clueless outsiders, the level of criticism, argument, discourse, etc inside the group INCREASES. People challenge and spar with each other.
Sweet take. I also just think we have someone here who is really good at collecting. Taking note.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Href huntin’ by Andreas Zwinkau
A few days ago, there was a thread on the link-sharing site Lobste.rs entitled: “What are your favorite personal websites around the internet?” So this was a great thread for href hunting. In fact, commenter ‘qznc’ dropped a link to /r/SpartanWeb—a subreddit collecting custom personal websites. qnzc is Andreas Zwinkau.
Andreas’ term “Spartan Web” indicates websites that are:
Interestingly, I’ve seen a bunch of recent articles praising HTML and attempting to foment a return to HTML. Writing HTML in HTML—someone who started a new blog without any type of an ‘engine’ or static site generator—it’s all just custom HTML. Words and Buttons Online, a directory-style personal page.
One thing I’d love to see is some static Indieweb HTML (in other words: microformats) where you can copy and paste pages to add blog entries. Then an index page where you can add a link to that page and JavaScript can optionally add in date/time/author details from the link. It could also use Webmention.io to load comments over JavaScript.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, thank you—I am with you on this as well. It sounds like we might be in agreement that there is much innovation to do in the spectrum of ‘feeds’/‘filters’. I think I also agree that needing access to the full post contents is useful—otherwise we end up with titles dominating and our filter weighs toward attractive headlines.
Re: ‘heat maps’—I’m reluctant to give any thought to the popularity of a writing. Yet, there’s no doubt that it’s important. If people are congregating, it’s worth knowing what the fuss is about. (I found your wonderful essay through Indienews—and this is a case where checking there has made it all worth it.) But I don’t want the zeitgeist jerking me around all day—think of it as a literal “ghost of The Now” pushing me around—I just want to peek at it usually and then move on to reading those things that are being overlooked.
I’m not saying you are wrong to prize that higher for yourself—I think perhaps the most innovative thing that can be done is to provide a variety of views on this filter—maybe RSS readers have just been too narrow by making themselves simple ‘inbox’ clones. We are trying to wrangle a lot of data here; we might need something quite configurable to do this task. (Which is contrary to my own reader—which I have been designing to be extremely naive.)
This is getting away from the juiciest part of your article, though: that there are serious human skills to build up. Reading and filtering. (I like your tag: ‘infostrats’.) But your mention of ‘heat maps’, for instance, reveals that our tools can improve with respect to enhancing our ‘infostrats’. Thank you for the further thoughts, Ton!
UPDATE: Okay, after looking through your archives, I can see that this reply was hasty. It’s amusing to me that you actually cover much of this in your discussions about ‘small tech’. Your essays over the years are a formidable work. I find myself very much in agreement as I read!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Cripes! I think this is the best essay I’ve read on how to read the Web. I agree with all of it.
I am definitely going to read this article several times before properly responding to it. But this is insanely rich stuff. I completely agree with and recognize the entire filtering strategy as my own. Feeling some kinship there.
As for the feed reader, it’s even worse: my own prototype (Fraidycat) is very close to what you describe. I assign feeds ‘importance’ levels that are much like ‘social distance’—I’m trying to decide if that term nails it for me. I’m not sure yet! It’s a good one, though.
I think the one area where I am not sure is still having to deal with a ‘news feed’-type stream of posts in each of those folders—is that your ideal way of reading? I feel like it focuses too much on recency. I’ve been enjoying just seeing a pulse of recent activity and then needing to visit their site to actually take it in (and perhaps explore further).
I definitely feel like the ‘social distance’ thing has helped crystallize why I put certain people into different ‘importances’—and it’s not just because they are actually more ‘important’ (like: to the universe). Anyway, brilliant!!!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Extraordinarily simple, useful, sweet.
I’ve linked to Phil Gyford last year in the post Timeline of Things Phil’s Done, which I am happy to link to again, because I recently worked on a timeline of a friend’s life and used this as a starting point. Timelines are a rich, underused visual catalog for hypertext.
Phil has just added a blogroll to the same website. This seems uneventful, except that:
The design of the ‘writing’ section is fantastic—while completely minimal and faintly ‘brutalist’—am I close? If you are starting on a new blog, look at Phil’s. I’m all about aesthetics and colors—but it’s usually a far second place to organization.
And I must ask: do you have a blogroll? Google would prefer you not to. But it’s the smallest, most atomic tiny directory—akin to ‘little libraries’ you see on the roadside.
Every single one of these links works! This is a watershed moment in 2019.
Find someone new to read today. You might find a friend. You might read something that really changes you. The world might seem a little more alive again.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Sorry to linkdump again—this is good!
I generally link, but now I am going to leech. He already posted this to /en/linking, but this list of assorted links that Joe has added to his pointers is just a blast. (I’m tempted to comment no further, since it’s fun to just explore the list without any direction.)
Nevertheless, I have to point out:
The XXIIVV Wiki: I’ve wandered into the XXIIVV Webring previously. But this wiki of projects is damned impressive—both for its ambitions and for its actual hypertext.
Cosmic Voyage: A small text-only community for story building. This has captured the spirit of dial-up bulletin boards in a way that I haven’t seen in decades. I’ve seen this here and there—glad to see it thrive.
Chris Burnett: Fly gradients. The now page is the best I’ve seen. I like that it becomes a timeline. For the first time, I understand this phenomenon.
Tales Through Photos: I just love the mood of this. No big deal. A site like this will never go viral. It’s just too light, just ‘I saw a Downey Woodpecker’.
Bloganueva: Web dev at the National WWII Museum. Brilliant colors. @marsh on micro.blog.
The Web just keeps getting bigger. Can’t believe the encouraging work I find each week. Get in here, all you folks out there.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A new dump of personal website links, discovered in the last month.
Don’t know if personal websites are catching on again or if it’s all about finding the right vein—I am getting more and more impressed with what I find, what people are up to. I’m also finding more and more that are already all hooked up to the IndieWeb.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Next week, I’ll be publishing the latest “href hunt”—where I link to those personal www sites and blogs and pages for anyone and anything. Hopefully you! Let Me Link to You!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
There is a nice discussion about the Web happening on HN today: news.ycombinator.com/item?id=19604135 Specifically concerning Google’s ‘forgetting’ of it.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Times like this, it sure pays to have your depth of knowing what’s out there—YOUNG-HAE CHANG HEAVY INDUSTRIES is definitely a classic. One that you’ve now introduced me to. I finally took the time to browse it. What an inventive take on a blog. (Or on poetry?) Since 1997. My humblest thanks, Joe.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Mystery.miami?  As Kottke has said: it’s too bad beyonce.horse is taken.
As Kottke has said: it’s too bad beyonce.horse is taken.
There’s a style of site I really dig and I find things often and send them to pinboard, but I don’t really use pinboard in actuality because it has more than just those cool sites.
Yeah, this was a big reason I started href.cool. Pinboard is so awesome. But whenever I start to follow a user, they inevitably start archiving their tweets—go to /popular/ and note that ‘twitter’ and ‘ifttt’ are tags full of noise.
Far be it from me to tell people not to use Pinboard to archive. If you do use a Pinboard, just tag everything in your ‘directory’ with a unique tag. Like ‘mystery.menu’, for instance. Then, people can watch your directory using https://pinboard.in/u:kevinkovacs/t:mystery.menu.
I really appreciate your encouragement. If you would have told me one year ago that I would be building a little Yahoo!-style directory, I would have laughed extremely hard and checked the date to see how far into the month we actually were. Yahoo!'s directory was adorable and doomed—but here we are. I think it’s pretty cool for personal use and I’m surprised that you see it too!
I would love to see more directories spring up—and I would look through yours from top to bottom. I wouldn’t have the restraint to stop myself—it feels like an untapped medium.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
You’re always asking me to clear up my terms—and I never do—but I’ll ask anyway: what do you mean by ‘power’? And what do you mean by ‘decentralizing power’? Because my first stab is that you’re talking about getting us back to local governments, tribes or something. The term ‘power’ gets bandied about—it’s the person with the money to hire, the person who radios the tanks when to roll in and when to back out, it’s the person with the megaphone.
I’m not really keyed in on ‘power’—I don’t see it as a kind of natural element. Seems more like it gets used to say: this, this is evil.
How to decentralize power? In a world of billions? Answering these questions is way beyond me. My wavelength is watching ‘humanity’—are we holding on to the transcendent ‘divinity’/‘shittiness’ of being human? Can we see this humanity in each other and at least allow the recognition of another human being to dawn on our faces?
I like to think of it as an ‘antimisanthrophic’ effort to at least establish a baseline sympathy or pity or some kind of comfort with our other peoples. Being a person is rough—we have no idea what’s going on here. Is this the real life? Is this just fantasy? (Perhaps I don’t take ‘power’ seriously enough. If none of us did—would it still be ‘power’?)
I will continue to argue for radical decentralization and worldclass p2p filtering. That is the only out, and the window may be closing. It can’t just be done by hand. We go down if the masses do.
Gah, I’m not convinced that technology has any answers! We can’t make some elaborate mousetrap that will enforce the life we want to live.
Of course, I’m not sure humans have any answers either! But I will say that talking to you and your family is the best technology I’ve encountered in a decade. Sure, I’m reliant on a sturdy free-enough technology that gets our words passed around. And those words are our plain humanity on the wire.
I am worried about some perhaps difficult to justify originality+authenticity moves, but the underground is not more real to me conceptually (though it can be more valid or valuable in the dialectic). I only care about “making it your own” insofar as it is justified to the particulars of your context. The Beautiful is not the overriding reason, but insofar as all other obligations are met, it is the last deciding force. The necessity of preserving freespeech and decentralizing power (including memetic distribution) comes long before The Beautiful though.
You’re not being cryptic—I just think sometimes your compression level is turned up on thoughts like these. I also have to add that I DO appreciate pop culture—I actually think it’s one of the most promising religions or symbolic systems we’ve ever developed. (And it’s REALLY tempting to demonize it, because it’s backup by capitalism—though I think that most people can appreciate the value of the engine—most people seem to agree that artists should be paid.)
Anyway, I don’t think mainstream culture is necessarily any less original or authentic than the underground. I just think that mainstream culture has become imbalanced—it has really captivated everyone this time, and fewer people seem to know how to escape it—which is the purpose of an ‘underground’, to me, and, of course, this is all just my perception.
I think—I think what happened was that, in the previous decade, the Internet gave the underground a tremendous breath of air. You basically had a network that was all underground—and I don’t just mean some kind of hip, stylized underground—I mean that, before the corporations figured out how to milk it, you would search for ‘donuts’ and be at someone’s uncle’s website.
There was no hunting around for rare vinyl or out-of-print Borges novels any more—the whole ‘underground’ world had doorways now. The underground became the mainstream culture and, yeah, we lost an actual underground. And I think there was a kind of crisis of overwhelm that mainstream culture had become so wide—like, “we need robots to sift through all of this.” There was a time when Twitter first came out that people were joking that it was just a bunch of people posting updates that they’re shitting right now. And now we just post those updates, no shame.
What, you want I should call you a selfish nihilist, a brainwashed individualist, an all-too-convenient emotivist, a shallow aesthete, a vapid internalist, a dark-triadic relativist, a deflecting anti-realist, a gas-lighting interlocutor, an actual waste of potential, and a gutless, wallowing, purposely purposeless sissy who hatlessly lacks the integrity to take the existential risk of committing themselves to an identity: i.e., the shadow of my enemy?
The part that actually got me here is the ‘shallow aesthete’ because it’s dead on—I think that I am on the prowl for this guy, but he’s out all the time, spray painting little soap bubbles on people’s suitcases.
I don’t think the point of a personal website is so much to design something pretty and ‘authentic’ (wtf?) or even ‘cool’. I think of it just as having a ‘home’—which seems eminently human to me—as opposed to ‘mechanical’ or ‘hive-minded’, such as being another tweet, lost in the feed.
While I hope for technologies like Dat (and have always loved peer-to-peer since the days of Freenet and Gnutella), the technology is so far from being adequate as to seem impossible at times. So, I’m quite happy getting anyone I can back into personal websites and wikis. Lately I’ve been thinking that ensuring a myriad of ISPs is a lot more important than peer-to-peer.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A loss for civilization? Well, yeah, if you put it that way—civilization is going to roll on, regardless. I suppose you could say my effort is misplaced: perhaps better to work on helping our civilization survive, to live on, rather than trying to look to the past.
But, put another way: do I want to preserve a civilization that doesn’t embody any of the ideas that I care about? You’re probably right with your last line there—maybe I consider myself one who has ‘absorbed’ the ideas of my time and wants to ‘move on’ with those ideas in different ways. I can probably do this just fine without ready access to the source material—but I am glad that I was able to show Dont Look Back (1967) to a friend recently, rather than needing to just recount my recollection of it.
Definitely don’t want to save everything. Just some essential bits. And I shouldn’t try to be noble about it—just seems fun.
(And hey—kind of you to write up your thoughts, NK.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Averting our gaze from mainstream culture—cAN It bE DoNE?
Hahah, wow—it’s funny because I find this article to be a similar kind of frustrating read. A good read—perhaps like the Times article was for her—but very frustrating. I wonder: is acceptance by mainstream culture really seen as the ultimate, final, crucial reward?
(Particularly now that we live in an age where it’s clear that the previous generation of cultural winners—be it Jimi Hendrix or Harper Lee—is rapidly fading away, to be replaced by YouTubers, video game streamers, YA writers, reality stars. Isn’t the mainstream culture going to be very ruthless in its war for canonization?)
I mean I love the author’s ultimate point: here, I won’t summarize it, let’s just get into it.
We need a mass realization that pulls us out of this flooding culture. That is: the acknowledgment by powerful organizations that we do in fact engage more with original stories—it’s a fact, look it up—that lasting conversations do not come out of Twitter trends, and that diversity means diversity—more that is different, not more of the same differences. As one curator told the Times in the piece about older black artists getting their due, “There has been a whole parallel universe that existed that people had not tapped into.” Tap into it.
As h0p3 would say: preach it! Tap into it.
But the author spends the entire piece looking away from the underground—scrutinizing the fucking New York Times to show us the way, looking at the top 20 shows on Netflix, stats on buying habits on Amazon. If the concern is that our culture is spending all of their time on Netflix, Amazon and the Times—well, so is this article.
So when we go to ‘tap into it’—what is it? Where is this ‘parallel universe’ we’re looking for? Where does this culture go to look for it? Is it on Amazon and Twitter somewhere? Are we supposed to continue using Netflix and Google—but somehow spend our time on the back alleys of those services?
Is this a request to leave alone the front page of the New York Times and start with the back page? (So much simpler to turn to the back page of the corporeal printed Times than to do so online.)
Clearly, the article decries the entire makeup of these systems:
Per CJR, these algorithms are “taste-reflectors,” meaning they don’t affect taste the way critics do but simply reinforce your palate; there is little discovery here.
And how much discovery can there be, really, with the same critics occupying the same space?
Yesss! So go outside those neatly ordered corporate-approved spaces, yeah?
Let’s return to that final tap into it! paragraph. The phrase I want to look at is here: “the acknowledgement by powerful organizations.” Wait—so the tap into it! is meant… for them??
Are you asking the powerful organizations to—go outside themselves? Why? So they can continue to show us what’s legitimate? Because they are the authorities on what shit is actually cool?
I mean, yes, I’m not dense—the ‘powerful organizations’ are a massive pipeline of fame and currency—and this stuff can be gasoline to an artist. (Lord knows I want Boots Riley to keep it up—dammit, give the man what he needs!) But all of us out here, all us commoners, put together—we’re pure fuel, too. There was a time when it seemed that those very organizations were at the mercy of the buying public, earlier in this century when the entire system shook in fear of ‘disruption’.
And so, it feels like the article is just asking the mainstream to open a little wider, to give out a few more awards here and there, in lip service to the world of underappreciated, wonderful, unknown artists. (Black artists, in her case—but also in mine, because I want my mind blown by cool shit as much as any of you.) And, yeah, okay, maybe the ‘corpypastas’ might just throw us a bone.
However, I love the ‘parallel universe’ she refers to—that’s our unruly, unpredictable Web—an extension of the underground scenes, of the avant-garde, the mixtape traders, the world of the only critics that matter: our little group of friends. Those mixtapes blow up out here first. Out in our parallel universe: all of you out on your little blogs and wikis that I tap into each day. This world exists. It’s here, even if it faces its own doom on some days, in the face of resurgent mainstream culture.
Fuck the NYT, fuck Netflix—I’m reading you folks.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Sweet—well taken! I am not into the celebrity news or mainstream papes. But it still looks like 30% of this is lesser known goodshit. The whole layout and vibe is quality. Again, thankyou!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This month I’m digging into weekly link roundups.
E-mail newsletters (tinyletter, substack), along with weekly link summaries on Patreon, and podcasts or YouTube intros focused on ‘community news’—these are very popular types of tiny directories that I have been overlooking. Watching people like h0p3, Eli Mellen and Joe Jennett dump these kinds of periodic link collections, I’m convinced that they are a crucial support system for blog/wiki writers (Hypertexting).
Some things I’ve observed while hunting around for link roundups:
Some communities are really good at this kind of thing. For example, see the weekly ‘heavy metal preview’ put out by Not Part Of Your Scene. People want to find new songs, bands want their news songs to be heard, and the blogs want to sift through it all and find the gems—this just cuts right to it.
The best roundups take the time to organize, add some helpful commentary and just make it all look nice and readable. Eli’s got a good thing or Stephanie Walter’s ‘pixels of the week’. I will cover this more extensively going forward. (Another interesting one: No Time To Play, takes the form of short essays on gaming.)
The e-mail newsletter software out there is doing a pretty good job. Take The Go Gazelle, which uses Revue to publish its newsletter. It looks good—and I really appreciate that it embeds Tweets. (Relevant: ‘Tantek liked a post on Twitter’.)
Roundups lend themselves to group collaboration. Look at mega-roundups like the one done by Eidolon Classics on their Patreon. Would love to see this kind of weekly superpost on the topics I care about.
These are also incredibly common on micro.blog—is there a roundup of the roundups?
Some interesting ‘forks’/‘variants’ of the roundup:
My Week in Objects: just pictures of… a bag, a pencil box. (via @joelhamill)
Gwern’s Newsletter: Very detailed monthly round-up. The drafts for the newsletter are also fleshed out in public. (Linked from Guzey, which h0p3 pointed out.)
I have more work to do, discovering innovations out there. But I have some good interviews coming up on the topic and will be doing another Let Me Link to You on the topic.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The fact that links like cosmic.voyage and quariety.com are buried in this dump is just proof that you’re on fire lately, Eli. The round-ups are brilliant, the digital abysstapes are fascinating—just want to encourage you to keep it all on.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ooooeeee!
Hoooaaaa! This site is lookin might fine, Eli. Total La Croix vibe. Or maybe the carpet at a laser tag place. The posts are long like elegant grocery receipts.
Don’t know if the world can handle a third National Treasure. Don’t know if it deserves another one. Wouldn’t be surprised if they filmed three sequels but had to shelve them until some future age. People just aren’t into rare coins and the Continental Congress like they could be.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This has been cool to watch—you’ve managed to bring over all your old links, everything looks good—and we can now crosstalk directly on your pointers pages and blog entries. This is great!
It’s funny—I stumbled across the VISUAL OBSERVER link around the same time as you. I think we’re both plundering a lot of the same tags and users on Pinboard. This has made me want to pool our link-finding knowledge, in the hopes of discovering where we’re being redundant and where we might want to venture out further. (I need to make a list of my main discovery avenues.)
To what degree do you grind away, looking for links? Or do you wait for them to come to you?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Some poems, some surrealists, some nicer margins, who cares.
Quite a few new links and poems added today:
The Tragedy of GJ237b, an unusual role-playing game added to Games/Imagined.
Bukowski’s “16-bit Intel 8088 chip” poem added to Stories/Poems. I’m not an enormous Bukowski fan, but this fits so well. I’d like to highlight it, for now. (Also, I really like the beginning of the Michael Longley poem quoted by @vasta today—although, at some point, I hope to rotate out popular poets for the more underground ones.)
“Hope”, another poem. A section on just simple, uplifting kinds of poems.
“The Book of My Enemy Has Been Remaindered”. A section on angry, tear-your-face-off poems.
The House of Mysticum, a surrealist blog—I think this could become a major subgenre of blogging, if it isn’t already. Added to Supernatural/Texts.
Smash TV—a vaporwave miniseries. Added to Tapes/Vaporwave.
Eleven-Minute Painting. I’m not sure why I’m drawn to this—I also found a number of derivative works and listed them under Visuals/Motion.
Reality Carnival. A long-running link log, along the lines of the links that Joe and Brad are collecting. Added to Web/Links.
I’ve also been improving the themes—trying to get them as nice as possible on all the various browsers and devices out there.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I’m getting a lot out of these ruminations you’re doing about links as notifications. For me, I think I’m going to include a ‘cc’ bit of post metadata, much like I already have ‘via’ metadata, to advertise the original source for a bit of hypertext. Cool idea.
The idea of a ‘bcc’ is even more interesting—it isn’t possible to have secret recipients listed in the HTML. They would need to be encrypted or something. E-mail actually removes the ‘Bcc’ header for recipients. I put this in the same category as encrypted private posts—very tricky to fit into the Indieweb and possibly just wrong for it.
So, I think person-tagging encompasses all of the normal e-mail send actions:
Direct reply. The text is meant for that individual to read. It’s important to show the person-tag, because it is important context.
Cc. The text is relevant to the individual and it’s relevant to show the person-tag to all readers.
Bcc. The text is relevant to the individual, but their connect to it is meant to be private.
And there seem to be other connections beyond these:
Mentions. The individual is a subject of the text. While they might be notified of this, it is more important that readers see the connection.
Unlinked mentions…? What if you had an individual who was the subject of the text, but you didn’t want to notify them? You may want to include an unlinked @boffosocko, to refer to someone without summoning them. But—what if you wanted to link readers to the person without notifying them?
Group syndication. All of the above actions could be used for a group URL (such as IndieNews or Indieweb.xyz) as an alias for a group of individuals. This is similar to a mailing list e-mail address.
It feels like there might be much more than this.
I do see the purpose of these “@” and “#” prefixes—as a type of miniature language for simplifying linking. However, there is no distinction between ‘reply’, ‘cc’ and ‘bcc’ with the “@” prefix. (Micro.blog has a problem—or, at least it did a few months ago—if you send a Webmention to a micro.blog username, it prefixes the post with an @-mention, even if you’re only mentioning them in the post. This is confusing, because the post may not be a direct reply, but it ends up looking like it.)
I do think Indieweb blog software could improve on these by letting you type shortcut prefixes for ‘reply’, ‘cc’, ‘mention’, etc. types of person-tagging—and then turning them into just normal links or post metadata, rather than keeping the prefixes in there. (I think Facebook does this.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Oh and yeah—can you pass along this link trove? I do a monthly ‘href hunt’, asking everyone out there for personal URLs—one of the problems is where to go to notify the world of one’s nascent blog or wiki? I can write up your collection—or link your write-up. Anything to help.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Joe Jenett’s link collection—been going strong for decades.
Oh boy, the micro.blog surf club is really coming together: Joe Jenett has said ‘hello’ by dropping a link to this directory of fantastic obscure blogs and things. (I think he and Brad Enslen met through Pinbard? Does that happen??)
Linkport goes back to 2000. But Joe has been collecting links since 1997:
I thought of pulling the plug (on the daily pointers) for the same reasons but decided to keep it going with a combination of new links and repeat links to sites with recent updates, along with working hard to keep it clean of bad links. Yes, it all takes a lot of time but fortunately, I enjoy doing it - it’s in my blood.
Even the oldest links in the directory still seem to work. I bow in humble deference.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I didn’t much care about search when you said this, but using h0p3’s search and your directory and Pinboard—there’s no doubt that it’s useful. It warps you to a place in the collection that’s workable.
I’ve worked out a search index that’s entirely done in JavaScript—it’s the same one I’m now using on my blog. Thanks to TiddlyWiki for helping me realize that this could be a great way forward!
When I publish, it updates the search index. (Right now my blog’s search index is 300k. Raw text of my blog is 1.2 megs. The index is loaded when a search is performed and cached for further searches.) I haven’t decided where to place it in the directory yet.
In 20 years I’ll either be dead or so old I won’t care. My time horizon is a good 10 years, which is forever in Internet time and is part of why I’m doing this now rather than dithering. You are right this is a long term game.
Hah! I laughed when you wrote this and I might as well voice it now. See you in
ten years, brother.
This is all good. The Indieweb folks are taking care of the social aspect, which is blogcentric sorta by definition. We can aid in discovery for the blogs and the non-blog sites. If there is to be an Independent Web X.0 somebody has to help map it.
I think one of my primary questions these days is: will the future be blogcentric? I feel like things are going to change. Although they could get more hyperactive. Thought streaming? Let’s hope not.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Cool—I am working on consolidating my bookmarks into a single directory (much like Brad has done at Indieseek.xyz, but it’s interesting to see you go with the approach of keeping links housed differently based on their purpose. It’s cool and your very thorough explanation is convincing!
I do like when people use Pinboard—and might consider double-posting there—mostly because I love that I can browse pinboard.com/t:toread to find interesting things. I keep looking for a common tag that means: ‘I don’t know what to think about this link.’
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A discussion of portals into a large hypertext.
Ok, this is rich—this point is on fire. We agree, yeah, oh hell yeah we agree. This is what I’m saying every third paragraph about how our technology is underutilized. This is a great example of the ‘social’ overemphasis of the single ‘post’ or ‘link’ or ‘article’ as opposed to the hypertext ‘body’.
(For anyone just joining this conversation, h0p3’s link in the quote above loads about 10 pieces of hypertext that represent his current ‘place’ in this massive [20 megabyte] ‘body’ he’s creating—so the ‘link’ he’s sent doesn’t represent a single ‘article’ or ‘tweet’, which is what we’re trained to think of a ‘link’ representing. And I wonder—beyond h0p3’s twenty megs—how can I ‘link’ to the ten related tabs I might have open so that you can see them together? How can you create your own ‘link’ that puts me into the center of a hypertext perspective you have?)
(In some ways, this reminds me of heavily cross-referenced and footnoted texts like religious scripture—which are hyperlinked in a fashion—and folks have long batched together references to these works through verse-chapter or page citations, and most often through quotes. The amazing feature of the link above is that it isn’t just a set of quotes—it is the definitive source material, connected to the live author. Is it possible that citation could be improved by allowing one to construct a link of views to many definitive hypertexts?)
I won’t even touch Reddit [and it’s spidering onto the rest of the web] without half a dozen tweaks and tools; it’s not worth my time.
I like to say that all our problems are human problems at this point—but I think I am starting to see that every site needs good search, some kind of indexing and a way of positioning it within the whole landscape outside of it. I wonder what tools you find most useful—are they just useful within Reddit or should they be available to you and I somehow?
I grant, however, that some methods are better than others. What counts as finding relevance in our hyperreading in general is some ridiculously hard problem. It’s probably fair to say most people will quickly run out of things they find worth reading on this wiki (if they found anything).
Yeah, I think if we start to get too ‘hyper’ we get lost in the linkage and things get blurry. I mean when it comes down to it, I just want to do some very basic things: meet people, connect thoughts, really dig into a concept, see neat things—and try to route around the armchair arrogance that seems to be plaguing the world.
I don’t plan to read your whole wiki—I plan to use it to research your takes as we correspond and to consult it while I’m studying, to see what other directions I can go. (I wonder if you’ll agree with this:) I think the point isn’t to make your wiki the Penn Station of philosophy—I just think some valuable things will bubble up out of your project that will connect to Penn Station bidirectionally. Just like I might draw from Vigoleis or Dr. Strangelove from time to time—philosopher.life is in there, too.
I’m not sure if I can say that they are manipulating the feed.
Manipulators treat the minds of others as mere means; they do not respect your dignity. Satya Nadella is a manipulator. Does that mean he and cabal of powerful deep state actors have conspired to control every little detail of your mind? No. But, the science of rhetoric, mass manipulation, and our ability as a species to produce increasingly effective apex predators only continues to rise. Power centralizes at any cost, including moral ones.
I guess I try to manipulate the feed, too, so yeah, of course he’s manipulating the feed. Why I’m reluctant to just pin the award on him: I’m not sure he’s actually accomplishing what he claims to be. I love that he’s put all of this work into influencing Hacker News, but his boasting about it could clearly undo all that work—so what kind of master manipulator are we really dealing with here?
The short-term efforts undermine the long-term—his infrastructure is not nearly as sound as it seems.
What are games except for sets of rules we play by to win?
Yeah, man, good questions. I think the trolls are way ahead in this effort—I think they see that they can create games that are honeypots. And I do think that the Internet still holds the power to flip the structure so that it is the powerful who get caught in these games that they think they can play. (Thus, the meme warfare centers.) I think the trouble is that trolls are chaotic and can align anyway they like—evil, neutral and good—are even ‘neutral’ and ‘good’ more likely to turn out to be ‘evil’ than vice versa? On the other hand, chaotics have been the Robin Hoods, the Guy Fawkeses, the Snowdens perhaps. I think we benefit by tapping into that subversive light-heartedness.
As you point out, we are still going to need a standard for when we define something as cooperating. If I respond to your letters with one word answers, I’m offering a token. You cannot escape measuring reality to some very large extent. I think this is part of our plight. Yet, the goal is to not be overly quantitative (where, unfortunately, “overly” is quantitative).
Oh—I like your arguments, answers and agreements on the T42T outlines. I think this also goes in with my thoughts on what I called ‘pluralism’ (but which really just means ‘a multimodal system of thinking’)—just as one needs to both ‘quantify’ and restrain from such a thing, just as one must respond in kind, respond with a token, respond with a tome (and never know precisely if one is doing it ‘right’)—it is always a constant balancing in a battle of extremes and competing ideals. Much like a relationship is a balance between what I am looking for and you are looking for.
So also I look at socialism and capitalism as arrows in my quiver; left and right as sides of myself more than two religions at war. This is overly simplistic—but so is T42T, it is a useful starting place for me. It is not the end, it is the curated entry point. It is the self-made doorway.
(The remainder of your letter—the part that essentially argues for staking a position—I am going to digest and figure out how to respond. I don’t have any problem with what you’re saying in a general sense; it is principled. I, personally, cannot get myself to ratchet down to anything concrete, for some reason. I think part of it is that I really do enjoy human beings—I am hard-staked against misanthropy—and that puts me in a really weird place wrt to modern culture and forming an alliance with a group rather than an individual. But if the mindset is totally bereft, then I am willing to abandon it.)
(As far as the TiddlyWiki loader: I am also waiting for more inspiration there. I think of that prototype as ‘chapter one’—I usually have to batch up ideas and code fragments in order to realize them. But glad it got the conversation going. I am thinking a lot about versioning—for example, can the timestamp also be part of the curated doorway that is the undercurrent of this exchange?)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I am very tied up trying to finish mine, but you’re doing a lot of good writing and I wish I was done so I we could be synced up on this.
I think the other question we need to ask is: how do we make a directory that’s not a directory? Like: is there a new kind of directory that is an evolution of the tried format? And I think the main point of pain is having to enter this giant catalog through a straw.
Just like Google is ‘entered into’ through a few search words—terms that rarely hit the mark and need to be gamed—could the directory widen the straw somehow? This is what is done by providing a hierarchy—but I also wonder if there are other novel forms. Like: say the directory changed day-by-day to suggest common categories or to show where I’ve been editing or to suggest a few categories.
I also wonder if a ‘pinned post’ might be useful: here are a few suggested categories, here’s one I added recently that’s kind of sweet, here are a few links that I’m considering throwing out.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘Constructing a body of hypertext over time—such as with blogs or wikis—with an emphasis on the strengths of linking (within and without the text) and rich formatting.’
‘Constructing a body of hypertext over time—such as with blogs or wikis—with an emphasis on the strengths of linking (within and without the text) and rich formatting.’
A superset of blogging and wiki creation, as well as movements like the Indieweb and, to some degree, federated networks.
Does it include social networks like Twitter and Mastodon? Sure, depends on what you’re doing. If that network is helping you build a body of hypertext, is keeping you sufficiently ‘linked’ and gives you enough of an ability to format the text, then ‘super’—you are hypertexting in your way.
Although:
Ton Zijlstra:
At some point social software morphed into social media, and its original potential and value as informal learning tools was lost in my eyes.
I hope it goes without saying that Twitter is a limited form of hypertexting. It underutilizes the tech—that’s its whole point, right?
You can compartmentalize your various writings, though.
Jennifer Hill:
And you’re probably all sitting there and you’re like, “This girl wants me to delete Facebook, Instagram, Twitter… I got a following! I got a brand!”No, that’s not what I’m saying. You have two selves. You have a career self, who—I’m pretty sure all of us have to use Facebook, Instagram and Twitter for work or Medium or whatever other platform in the world you want to use—and then you have your personal self that knows the things that they’re doing. And what I’m speaking to right know is your personal self. You know, I understand you gotta make money, gotta make that dime…
But the point of the term is not to disqualify a certain technology or to try to channel disgust or disdain into something new—that’s exactly why the term is envisioned as a superset. I am extracting this term from what I am seeing develop on the Web.
A superset is the inversion of a subset. So, rather than dividing a topic into further subtopics—we combine related topics into a new ‘super’ topic. By redrawing the lines of the topic, it is possible to discover new subsets within the superset or to work with folks across the topic as a whole.
In this case, the superset seems superuseful since the division lines between the hypertext niches are almost entirely structural. (This isn’t entirely true: some structures imply, for example, centralization. A feed of interleaved user ‘stuff’ is done most simply by a single network housing that data—at least at first.)
I’m not even sure the subsets actually exist. It is already all hypertext that conforms to a variety of possible structures:

The blog (feed) and the wiki (ad-hoc) might not actually be different—despite that we think of wikis as being multi-writer (the original wikis anyone could edit, without respect to any record of permanent trolling demerits) and using a simplified markup that made linking fluid while writing—a blog can do what a wiki can do and vice versa.
By decoupling the hypertext from the implied structure of a wiki or blog, I can now look at these structures as mere arrangements of my hypertextual body.
I think it’s worth repeating the criteria of ‘hypertexting’ so that it can be either corrected or remain crystal clear.
There is nothing new at all here—in fact, it’s all becoming very old—but the superset distinction allow us to draw attention to the ‘body’ rather than the blog ‘post’ or the wiki ‘page’ and to ask: ‘what are we creating here?’ The body itself is a superset—and ‘hypertexting’ calls into focus what the work as a whole can be from a higher vantage point.
These three attributes imply an effort that goes beyond writing alone. The first creates a body whose length is practically infinite—no reader will likely consume it all. The second indicates that much research (both external and self-research) is required. And the third gives a sense of bottomless innovation to the publishing interface—in fact, as long as the body is able to remain intact, it can be published by anyone exactly as it is intended, as long as the browser remains compatible, which it has done remarkably well so far.
In addition, this gives us the impetus to preserve the browser’s life and compatibility, such that these bodies are kept alive.
Creating a body this large demands the ability to shape the structure. This is the problem: how do I begin to approach your giant monolith of hypertext beyond just reading your two or three latest posts?
What I would like to highlight is the ability of the author to use the ‘body’, its linking and formatting, to shape the structure. To infoshape.[1]
Link directories are clearly a part of this superset. Delicious and Pinboard themselves act as hypertexting swarms that work to connect the bodies. Maybe these connections fill holes in the body—maybe they act as introductions between bodies. They are a way to shape the info and annotate it slightly.
h0p3: I’m actually annoyed when people call my wiki a blog, since it is obviously not that to me. Of course, the fool in me starts wondering what exactly on the web doesn’t count as hypertexting? What doesn’t have a single entry point?
The home page is definitely the curated entry point. But it’s not just that entry point that’s important—the points that go deeper from there are important. h0p3’s home page was initially the most important thing to me. But now it’s the ‘recent changes’ page and the bookmarks I have that indicate where I intend to next explore further. Sometimes he is a blog, sometimes he is a wiki. Sorry, man!
So, (tentatively,) let’s look at three aspects of your hypertext:
To bring this into practice, here are a few interesting ways I’ve seen this play out:
Zylstra.org: This blog builds on itself day to day. In a way, posts become redundant because Ton is very careful to rewrite the same idea in different ways—to be sure it’s understood. I have read articles from 2008 that are only subtly different from others in 2018. But this makes sense—his message hasn’t been received yet. On top of this, he has a small directory for reading through his writings. I found this perfectly useful. You can do this kind of thing by hand, if you need to.
h0p3: I guarantee you’ve never seen a wiki used this way—as a backup for physical letters, as a way of messaging people, of writing drafts in public, of keeping detailed link logs, chat logs—it’s all in there. Links are used liberally throughout everything, so that you can track h0p3’s growing nomenclature.
More than half of hypertexting is the reading behind it—because if you are hypertexting in isolation, then you are missing out on a world of links.
Ton:
I treat blogging as thinking out loud and extending/building on others blogposts as conversation. Conversations that are distributed over multiple websites and over time, distributed conversations.
What you might think of as ‘advanced hypertexting’ simply allows the shaping of the hypertext. Could we go beyond that?
To me, this is a great advantage of the superset. If the platform could see itself less as being a blog or a wiki or a directory, but as a collection of hypertexts that can be shaped, perhaps by hypertexts themselves. (Wikis—and TiddlyWiki in particular—have long had this abililty to make a page that displays the other pages as a blog. And some wikis allow you to include pages in other pages.)
The advanced hypertexting doesn’t end with the wiki—it’s just one way. I think Tumblr was initially on to something—aesthetic and piece layout are important here. Now add the ‘advanced’ hypertexting and what do you have?
(This is an unfinished steno—it could use a survey of the hypertexting field here. And it will be interesting to see where things go over the next six months. I will have to revisit this after I learn more.)
(I think the other missing discussion is how ‘ephemeral’ fragments fit into this. See also: Blogging.)
The other side of this coin is Infostrats—the reading of hypertext. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, wow—yeah I actually did browse ‘The Griddle’ from Kottke’s list he put out. I am really into Cryptics and mazes, so we have a lot of crossover there. And, yeah, tacos, sure sure.
Your nostalgia post REALLY excites me, though. Your writings on these links are great and it seems like you’ve seen a lot of spots on the Web that I haven’t seen yet. Do you happen to have more of your links collected like this elsewhere?
As for your projects and sites, I like a lot of what you are doing and I will include you in my next installment of href hunt—thank you for poking your head out. Let me know if this reply is an okay way to reach you or what you prefer. Take care, David.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.
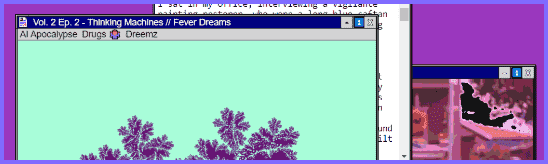






{kind=link}
Reply: Lateral Connections
‘…unlike things being adjacent to each other.’
Great comments. Even without algorithms, this can be trouble—on subreddits, posts can be flagged ‘offtopic’—so overboard moderation is a problem. (Of course, Reddit is where one goes to fully ‘engage’. No /s—it’s fine to do that. Problem is: people may not know where to go to get outside of ‘engage’ mode.)
One thought I’ll add re: getting outside of my own interests—I think if we had better tools for keeping tabs on our interests, we could more easily move outside them. (Like: if my ‘reader’/‘news feed’ makes it difficult to track 100 people, then I can’t very well track 1,000 people.)
And directories are sweet here—they are little libraries. Sure, they can cover your interests. But they can be used to map the strange elven lands that you happen to sally in.