I’m very slow to reason about things, so I often just avoid it. Which means I
end up with a whole lot of things I haven’t reasoned about - until I have to.
(It’s also overwhelming - the amount of things to try to figure out.)
I’m kind of ambivalent about Chesterton, but maybe he was ahead of his time.
Borges liked him, so that’s probably enough. Anyway, I ran across this quote
from him:
There exists in such a case a certain institution or law; let us say, for the
sake of simplicity, a fence or gate erected across a road. The more modern
type of reformer goes gaily up to it and says, “I don’t see the use of this; let
us clear it away.” To which the more intelligent type of reformer will do well
to answer: “If you don’t see the use of it, I certainly won’t let you clear it
away. Go away and think. Then, when you can come back and tell me that you do
see the use of it, I may allow you to destroy it.”
— G. K. Chesterton, The Thing, 1929
This is tough enough to do with a fence. How do you possibly attempt to justify
the purpose of abstract empires like Wall Street, religion, vaccines, capitalism,
socialism, governments, police departments, academia and even stuff I personally
loathe - such as influence-peddling and that ‘recognition’ is considered a good
thing to do to someone?
A way to defeat Chesterton’s Fence is to simply obscure the purpose so deeply
that - while there may be surface purposes, the true purposes are purported to
be too deep to understand - except by a select few. (The term ‘quantitative
easing’ comes to mind.) A fence like that becomes quite invulnerable.
He goes on, elsewhere to further object to passionate, sudden smashing. This is
predictable.
Suppose that a great commotion arises in the street about something, let us
say a lamp-post, which many influential persons desire to pull down. A
grey-clad monk, who is the spirit of the Middle Ages, is approached upon the
matter, and begins to say, in the arid manner of the Schoolmen, “Let us first
of all consider, my brethren, the value of Light. If Light be in itself
good—” At this point he is somewhat excusably knocked down. All the people make a
rush for the lamp-post, the lamp-post is down in ten minutes, and they go
about congratulating each other on their un-mediaeval practicality. But as
things go on they do not work out so easily. Some people have pulled the
lamp-post down because they wanted the electric light; some because they
wanted old iron; some because they wanted darkness, because their deeds were
evil. Some thought it not enough of a lamp-post, some too much; some acted
because they wanted to smash municipal machinery; some because they wanted to
smash something. And there is war in the night, no man knowing whom he
strikes. So, gradually and inevitably, to-day, to-morrow, or the next day,
there comes back the conviction that the monk was right after all, and that
all depends on what is the philosophy of Light. Only what we might have
discussed under the gas-lamp, we now must discuss in the dark.
— G. K. Chesterton, Heretics, 1905
I do like that the monk is ‘excusably knocked down’. I feel the monk’s issue
here is exactly what I described earlier - obscuring his reasoning in
abstractions, in a way that feels like stalling. The pullers-down here may seem
impatient, but hey, we can’t spend our whole lives analyzing a lamp-post.
In a way, all of the various reasons for pulling down the lamp-post are pretty
damning. Couldn’t a variety of reasons be much more compelling than a singular,
unanimous reason?
Besides, isn’t the fence’s destruction inevitable? By fire, rain, vehicle or
animal - isn’t a fence ALWAYS a temporary solution? Hastening its destruction
seems innovative - let’s find out what the consequences are - REAL, not
imaginary - such that we can find a more permanent solution perhaps.
I think that, if people are talking about taking down a fence, then they are
likely free from more pressing concerns. So they likely have the luxury of now
addressing the consequences.
In this way, I feel like the current desire to destroy the police
departments has come about BECAUSE culture and society have improved. We now have
the luxury of this being our concern - and there is an inate feeling percolating
that now could be the time to confront the consequences. (I don’t say ‘luxury’
accusingly - having experienced a lot of grief in my life, I feel that grief too
is a luxury - not everyone has the luxury to dwell on a tragedy after it happens.)
I run out of steam pretty quickly on topics like this. It’s not that I don’t
care - it’s just the futility of trying to tackle a big topic, having only lived
as this one inadequate being. (I lose every debate I get into because I see the
other person’s side too easily - and I just agree with everyone. It’s stupid - I
wish I was principled.)
But I think I see the ‘fence’ differently than Chesterton. We are too attached
to our personal fences. Even the big ones like capitalism and socialism. I feel
that these are just tools for us to use. (And I think humans will ultimately
move well beyond these two concepts.) Both capitalism and socialism have useful
concepts that will stay with us. Even if they are one day only found as choices
in the menu of a SimCity clone.
Life will one day be unrecognizable to us today. The events of the last few
months are proof of that. And I almost feel certain that the least likely
prediction will come true. (And I do wish that Chesterton’s fence was real -
maybe it is - because I confess that it would be cool to visit such a thing.
Even if it would only be kept alive under extremely vigilant care.)












 Apologies to be so slow in reply. And thank you
for your 1999.io resources page - good stuff!
Apologies to be so slow in reply. And thank you
for your 1999.io resources page - good stuff!

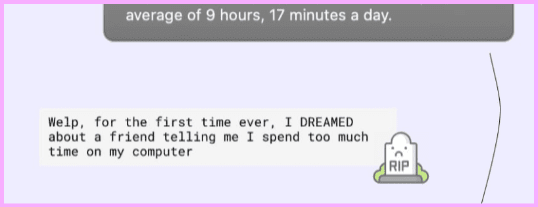










{kind=link}