Okkk - notes from the second Clubhouse I attended with S. Joy Mountford.
(This is the second transcript I’ve taken of a chat with Joy. See the first
at Notes from Clubhouse w/ Joy Mountford. This took place on March
11th, 2021 at 6 PM Pacific.)
HOPE I’M ACCURATE HERE. IT’S KIND OF A BLUR AND I’M READING IN THE LINES.
Specifically discussing the Human Interface Group in the 90s.
We take for granted all the space and computing we have today. At the time, she
joined Apple, she started on a Macintosh SE. It was a $2,000 computer with two
800k floppy drives, 1 meg of RAM. And they were trying to do Quicktime with
pictures the size of postage stamps.
In those days, they couldn’t do illustrative or animated story-telling - and we
also take for granted that story-telling is a part of design work.
She had a connection with NYU ITP - and thought that they would bring a few
students in to gain exposure to computing. Dan O’Sullivan was one of the
interns. He had a camera pointed at a Coke can for like a month. Another person
was taking a picture of water droplets over and over.
She thought, “What are we doing? This is going nowhere.” She was told, “Leave
everyone alone. Just be patient. Something is happening.”
Lol. “Trust me, trust me. Something will happen.”
They’d been filming thousands of pictures into a giant circular movie.
People gasped in shock at the view all around the scene.
People were standing next to a machine with freon to cool it down - presumably
while it rendered.
The summers were full of interns experimenting and it sounds like Joy would
write up job descriptions for them that would provide them with a cover while
they
She described John Lassiter’s “Pencil Test” short - and the release to coincide
with Quicktime.
Hypercard. Teachers were excited about it bc they could pick off images and
build presentations. It become easier to make content. The game Myst.
The idea of going up to the top of the Golden Gate Bridge. It was a Mac Plus.
Had a harddisk attached as well. Was bigger than the elevator to go to the top.
So it was hoisted up next to the elevator. There was no ground up there - just
cables.
Dan O’Sullivan had to go up. Last minute, he mentions he is afraid of heights.
Again - thousands of pictures stitched together into an interactive scene,
above the Golden Gate Bridge. They began to give beautiful interiors the
treatment - palaces in Russia and museums.
Presenting to Russia, their first demo of the VR image had no reaction. No
clapping, no response. They were devastated.
It turned out that they didn’t believe it was real! Afterward, they had to
impress upon one of the faculty that the demo was real by putting his hand on
the mouse and illustrating that the room in Pavlov’s Palace could be navigated.
A day in the life of Australia - with 30 different countries represented among
the workers attending. This was a series of photographic books - and Joy loved
that the series showed photographers taking the pictures and some
behind-the-scenes stuff. She felt this was important bc “if you’re going to tell
a story outside of reader’s worlds, you should show the connecting story that
bridges to their world - to draw them in.”
Americans in the 90’s were less impressed by demonstrations than other cultures
because they were exposed to it so frequently. Once we are exposed to an
innovation, our imagination catches up to it and other things become less of a
stretch.
Reminiscing on “background printing”. Before PCs could multitask, you had to
wait for documents to print.
Re: developing guidelines for developers, to ensure that Apple products were
consistent. There was no “police force” at Apple, it was designers writing
well-written, simple-to-follow guidelines to ensure that everyone was on the
same page.
“It wasn’t as glamorous as going to Russia, but it was just as important.”
She developed color designs on a monochrome screen, during the transition to
color! Flipping down color foils over the black-and-white screen.
Starting without color monitors. She asked for a color monitor. “Don’t be
ridiculous, you can’t have one of those.”
Some people did not want Hypercard to be produced. Bill Atkinson worked offsite.
It didn’t fit into the culture at Apple. Like asking people in the UK to switch
the side of the road they drive on - people just didn’t see the reason to put on
a new paradigm.
“It was a totally different way of computing. And people got confused. No shit!”
People needed to see it in a new light - but they saw it as a different
model that offered no benefit. “You don’t play Call of Duty in the same way that
you listen to audiobooks.” (LOL!)
Don Norman walks by - first card is an index card with a fish and a telephone
number. “A fish doesn’t have a telephone number.” “Don, it’s a graphic, not a
real fish.”
These creative tools opened computing to women, who had been isolated from the
male-dominated world of programming. Anyone who looked different at the time was
sent to Joy because she cultivated a team with a wide variety of talent. But it
wasn’t just an appearance thing - she discovered that most of the people she was
drawn to had a background in music.
They had to spent a lot of time in the office because most of the computers
couldn’t be transported home easily. “Luggables”: computers like the Powerbook
that were somewhat transportable but not easily. They still had to use pen and
paper quite a lot with no Internet to keep their home and office work in sync.
Education was not a lucrative thing to pursue, never has been. Apple had to
compete with IBM. There was no competition in the “entertainment” front. And
games were just for children.
Mechanical Universe (from JLP) was a foundational work to teach Physics. But
it was an uphill battle to get to those shifts.
Re: “productivity”. Work was developing plans, producing spreadsheets.
Visualizing those things was quite controversial. It seemed extraneous to
spend time designing the view of a project. Now it’s taken for granted
that you can design post-its as “productivity”. (This feels like a jab at Kanban
boards. XD)
She’s bagging on icons again. But hey - what could be more iconic? (Esp those
original slanty Mac icons.)
Mention of a female mathematician who had long hair - and all the male workers
assumed she was a designer. “She’s a mathematician - don’t go asking her to make
you icons.”
Story of people cutting their fingers installing graphic cards in the computers.
Dripping blood would short the boards! The execs had no idea the difficulty
people were having until they did studies and filmed videos of people doing the
installations.
With the new color monitors, people didn’t understand that the screens were
still black. (When powered off and during early boot stages and stuff.)
So they would return the computers bc the monitors weren’t “color”!
Lol. Going off on “A.I.” again. The word “intellegent” and “deep” being bandied
about. “Why do people not know what Eliza is? How many lines of code was it? And
when was it written?”
“Ivan Sutherland will say: I’ve done nothing.”
While talking about how many great works from the past have been ignored and
not followed. “Newness is very overprojected and underdelivered.”
Interesting story about getting people to open up creatively by having them cut
up magazine images and Xerox their collages. People were shocked at what they
were capable of.
“I listen to music today - and I hate it! But I learn new things by listening
to it.”
“We don’t sit and watch enough - we react. But it can be practiced: What is
that person thinking? What would happen if a ball fell on them. Practice
observing.” She mentions a Welsh four-year-old who discovered a large dinosaur
footprint while the father was on his phone, standing by her.




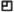











































 Ok - didn’t spot that. Thanks, krisu!
Ok - didn’t spot that. Thanks, krisu!


−☆")





































Reply: Hallstyles
Aha - since you’ve got Webmentions up, let’s do this!
Hey Jacob! I’m familiar with your website - I covered your linkroll in Directory Uprising.
It’s really comforting to see you interested in projects like directories and whostyles that aren’t necessarily protocols - which the Indieweb can get very focused on. Whostyles are definitely a tough one to turn into a protocol - since CSS evolves over time and it’s tough to know how to restrict the styling. (But it’s also important bc perhaps you don’t want to load a bunch of whostyles that blow up your site.)
Your introduction of
all: revertis exciting - didn’t know about that!So this is exactly what I do as well - just manually create the whostyles and apply them once I get into a longer dialogue with someone. This gives me (and hopefully you now) plenty of time to mess with whostyles in the field.
This is another thing I think about as well - and I guess I was going to take it on a case-by-case basis. If h0p3 has a new style, I might make a new ‘h0p3_2’ style for him - or might just update the old stuff if it makes sense.
Ok - as far as your proposals, they look good! My original plan was pretty shaky - so am glad to see improvements. Just feeling a lot of gratitude that you took the time and have energy to put into it.
I guess, as a bit of additional response, I should also mention that I’ve thought about doing this as a JSON format rather than as CSS.
Here’s a look at the JSON format we’ve been using for Multiverse box styles.
For fonts, we could keep an expanded list of font names that are supported - or at least a kind of registry - just like browsers already understand Verdana, Arial, Courier, etc.
So perhaps this paired with a font registry format would do the trick. I don’t have a strong preference tho - and am just throwing this out there.