#catalog
I use three main tags on this blog:
-
hypertext: linking, the Web, the future of it all.
-
garage: art and creation, tinkering, zines and books, kind of a junk drawer - sorry!
-
elementary: schooling for young kids.


#catalog
I use three main tags on this blog:
hypertext: linking, the Web, the future of it all.
garage: art and creation, tinkering, zines and books, kind of a junk drawer - sorry!
elementary: schooling for young kids.

@glitchyowl and I have a new project coming up - based on ‘whostyling’, scrapchats and Hypertext 2020.
I’m basically a Bilbo, content to stay at this corner of Bag End, being a layabout, munching wiki squares and playing all of Soundcloud chronologically in the background. (They were right about this ‘cozy web’ thing!)
Now glitchyowl has snatched my coat collar and dragged me into the woods on adventures. My pipe is still spinning in the air.
This is the tale of purple desert designs, silent HTML livestreams, MacPaint toolbars, Mario Kart-inspired JavaScript and disgustingly gaudy drop shadows.
We’re starting to draw the curtain on Multiverse - our combination of a new ‘blog’/‘wiki’ aesthetic, paired with some Indieweb sprinkles.
Also - we’re doing this diary at Futureland, which is really great. If you’re looking for a (somewhat minimalist) hideaway to blog at - but with much more style that the pastebins and a nice community - give it a go.
Of course there’s not the autonomy of a self-hosted customized TiddlyWiki or Neocities site - but it’s a community. Think of it as a replacement for the old message boards.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Let’s see what you think about this big pile of colorful squares.
I think we can all agree that this is where we should be headed. I try not to say should - this is the one time. A big directory of people. I’m a big directory freak. But it hadn’t even occured to me to make a social network that is just a directory. Special fish.
I should probably just let you go explore. There is a way to make the site play music that I saw on Twitter a few weeks ago, but I can’t be bothered to look it up right now.
Here are some leads:
These are only the beginning - this reminds me of the tilde resurgence some years back, but more among the art crowd than the technology one.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A trail of poignancy by @vinhtruong3 winding around Japan, from Sweden to Iran.
Just a cool list that I saw by way of Toby Shorin. The mood here recalls Sibylle Baier’s “Colour Green”. Not sure the advantage to using Arena over a YouTube playlist. I was hoping for some commentary on the songs perhaps. I absolutely love the Andrei Petrov song here “Dance of Recallings”. It’s from a soundtrack and the film sounds great as well.[1]
Some of these songs are quite popular, but don’t think I’d heard any of them before. Expect harps and harpsichord. The rest of the Masahiko Satoh album is here. (Don’t know if I should be doing this - just trying to live up to the LEECHING side of things around here.)
See, this is another great example of what a directory can do. This is just a link list for tracks. But it pokes holes in my world and lets all this other stuff leak in that I was oblivious to.
Recalls to mind Rebecca Blood:
Even the man who turns first to the Sports section of the paper version of his hometown newspaper is exposed, however briefly, to the front news page; and an interesting headline in the Living section may catch his eye when he puts down the rest of the paper.
p. 12, The Weblog Handbook (2002)
Recommendation engines are likely too fixated on salience - how do they possibly widen their view and attempt to bring in material with such a low signal (in terms of broadcast strength) as to be indistinguishable from spam? Making playlists like this is the vital work we must continue to do.
Another quick quote, sorry to ramble.
As children get older, they yearn to understand what lies beyond the apparent; they want to know about what they can see in front of them but also what they cannot see.
— p. 6, “Children’s Need to Know”, Susan Engel
I think this description of curiosity nails it. The playlist of unknown videos is another version of seeing what I cannot see. I see people there that hadn’t existed ever before for me.[2]
I love Russian film from the 70’s and 80’s. Recently watched the miniseries for The Idiot from that era. Please feel free to recommend any. ↩︎
Sorry, I keep going. Look. I really appreciate Kurt Cobain for using his fame to spread around new knowledge of unknowns - like he was a big part of Os Mutantes becoming known in the U.S. - he did some hole-poking here and there. Unlike Paul Simon was very tight-lipped about his South African influences like Tau Ea Lesotho and Mahotella Queens. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Fraidycat 1.0.7 is out (in the browser and on desktop), major performance improvements.
My appreciation to all of you out there who have been helping with Fraidycat - this last week has been very busy. There are now releases for Mac, Windows and Linux. These don’t sync between computers yet - but I have spent quite a lot of time polishing them up, to prepare for that. The web extension has been running kind of heavy, so I have now made some major improvements to its performance.
If you use Fraidycat in Firefox, the update is already available. I don’t think the Chrome extension will make it through their store until the end of the week.
I haven’t spent much time trying to spread the word on Fraidycat just yet. I am still clawing along until I can reach a quality that I am happy with. I am close. I think I just want to improve the appearance a bit over the next week and see if I can offer something a little less bland.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A new (but old-school) forum that’s my current hangout with other web directory nerds.
Don’t know if it’s just me, but I’m seeing a definite resurgence in directories. Like fingers.today (previously crocodile.is) - a home page / blog that is almost like viewing an unsecured open directory. Along similar lines, beautiful-company.com - I think Sphygmus dropped this link - click on the circle in the upper left. I’ve also mentioned Edwin Wenink’s site - but specifically check out the etc section.
So some of us in the burgeoning directory world - such as Brad Enslen of Indieseek and Joe Jenett of i.webthings - have been trying to get a community going, to talk about how to linkhunt in 2019 and to try to provide resources to people who want to start sly niche directories.
So yeah - Brad put up this basic forum - seems good. I’ve been on for a week or two and the discussion has been great so far. It has an RSS feed for new posts. I guess we could do this kind of thing with Indieweb.xyz, but I don’t know - maybe we don’t necessary want to clutter up our blogs with all of the messages related to this topic or maybe you don’t have an Indieweb endpoint to communicate through. (Come on by, say hi here.)
Although I will be trying to clean up and summarize some of the discoveries we make there - because this blog does cover directories about 30% of the time.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
 I did this too. A directory is a long game - I think you can safely roll-up
changes every 3-6 months. Cool that you got some submissions!
I did this too. A directory is a long game - I think you can safely roll-up
changes every 3-6 months. Cool that you got some submissions!
I think what we need more than a forum - is an easy way for people to make little directories. I mean even just link lists would be a start.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Fraidycat 1.0.4 is out today in the Firefox and Chrome stores.
Fraidycat 1.0.4 is out - and things are rolling. Much appreciation to all of those who are pitching in ideas on the issues page. Particularly Bauke and Joshua C. Newton - who brought up bugs that I was able to fix in this release. (And apologies about all the noise on this project - I’m excited about it right now and, believe me, I have a variety of things planned over the next month that will take us away from Fraidycat.)
The new version is already approved in the Firefox Add-ons area. The Chrome (and Vivaldi/Brave) extension is still at 1.0.3, but should update automatically very soon. I’ve also started offering a plain zip that you can install manually using these instructions. Auto-updates will not be available - but you will also not be dependent on the official ‘stores’.
This video is also mirrored at archive.org.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
What are blogs for? A trip to the beginning. The halcyon days of dot-com idealism and sheer shit-talking.
Here are my notes on the book We’ve Got Blog: How Weblogs Are Changing Our Culture—a worn-out name, but a pretty decent compilation of blog posts from the early days of the phenomenon, mostly 1999-2002.
The articles in this collection are early reflections on the weblog phenomenon. Mature reflections do not exist: the weblog community coalesced only three years ago. Not even the pioneers—some of whom contributed to this anthology—know where weblogs are going, or what place they will eventually fill on the World Wide Web.
— p. xii, Rebecca Blood
The word ‘weblog’ was coined in 1997 - but I think 1999 was officially the first big year for blogging, with both LiveJournal and Blogger appearing. Somehow, wanting to reach back to that era now that 20 years has passed - to attempt to uncover what went so wrong between then and now - I checked out this book from the library on an impulse. It seems to capture the spirit of that age in such a remarkable way - like that jar of deer meat I recently found in my brother-in-law’s basement labelled: '97. (“Oh, it’s still good,” he said.)
And considering Rebecca’s point above: 20 years later, do ‘mature’ reflections now exist? Is it all over and we’re far beyond reflecting? Has the blog just been a tulpa for some ancient essence that we’ll never capture?
Time to reflect.
For the first fifty pages of this, I felt nothing but self-loathing. Blogging suddenly seemed like the most disgusting thing to do - to aimlessly, carelessly write endlessly about my tastes and interests. While I quite like Rebecca Blood’s analysis in the early chapters, this quote chilled me:
As [the blogger] enunciates his opinions daily, this new awareness of his inner life may develop into a trust in his own perspective. His own reactions - to a poem, to other people, and, yes, to the media - will carry more weight with him. Accustomed to expressing his thoughts on his website, he will be able to more fully articulate his opinions to himself and others. He will become impatient with waiting to see what others think before he decides, and will begin to act in accordance with his inner voice instead. Ideally, he will become less reflexive and more reflective, and find his own opinions and ideas worthy of serious consideration.
— p. 14, Rebecca Blood, “Weblogs: A History and Perspective”
Perhaps Rebecca could really use the confidence boost - and that seems entirely wholesome - but I personally do not need to take myself more seriously. I can definitely appreciate improving my articulation - yes definitely, definitely - but becoming more ‘impatient’ and more opinionated - yet somehow more ‘reflective’? More weighty? I don’t want this to happen… (I think I’d like to remain aware that I’m a perfectly worthless dipshit.)
Any idea that these days of blogging were somehow more idyllic, pleasant or enviable quickly goes out the window in this book. The shit-talking is near-epic! Names are named—denounced and disgraced as ruining the form—mostly deriding “A-list” bloggers, but also decrying “the unbearable incestuousness of blogging.” Seems like the confirmation I’ve needed that mastering hypertext is going to be a formidable challenge for us - one that they were only just beginning to embark on and, therefore, were well over their heads in.
However, so far I’ve found a surprising amount to glom on to. These early bloggers definitely had a whiff of what was to come (partly because many had recently left the experience of Usenet) and I think I’m coming away hugely crystallized. Unexpected!!
The juiciest quote, for me, so far is this one:
‘Accept that the Web ultimately overwhelms all attempts to order it, as for now it seems we must, and you accept that the delicate thread of a personal point of view is often as not your most reliable guide through the chaos. The brittle logic of the hierarchical index has its indispensable uses, of course, as has the crude brute strength of the search engine. But when their limits are reached (and they always are), only the discriminating force of sensibility will do - and the more richly expressed the sensibility, the better.’
— “Portrait of the Blogger as a Young Man” by Julian Dibbell (2000)
This might be a little self-affirming, because it seems to vindicate the web directory (e.g. my l’il href.cool) but what it really seems to be describing is the blog as our premiere discovery mechanism.[1] This must have been a common view at the time, considering this earlier quote:
[…] the weblog movement will begin to realize its true power, a more widely distributed version of what the Open Directory and other collaborative web directories have promised but only minimally delivered.
— p. 40, Brad L. Graham, “Why I Weblog”
In hindsight, this feels like hyperbole - the finished product of a blog seems (to me) less navigable than a directory, although both are usually stale by then. But I think this has played out, to some degree, especially if I think of how useful a good music blog can be when attempting to discover new music. (Though I think a good music podcast or YouTube review can be equally good.)
Hmm. A medium really is only as good as the artist makes of it. It’s not that hypertext is tapping into us. We’re pushing it wherever we want, right?
We are being pummeled by a deluge of data and unless we create time and spaces in which to reflect, we will be left with only our reactions. I strongly believe in the power of weblogs to transform both writers and readers from “audience” to “public” and from “consumer” to “creator.”
— p. 16, Rebecca Blood, “Weblogs: A History and Perspective”
I want to draw a comparison here between this quote and (apologies) Fortnite Battle Royale. Putting aside everything else about Fortnite, it tacked on an interesting innovation: the ability to build structures (in a Minecraft-inspired fashion) with a traditional (third-person) shooter.
Most people seemed to scoff at this blend—as if it were some kind of mere monstrosity of buzzwords. No, this ability to build boxes around yourself or staircases to scale mountains added a much-needed defensive strategy to shooter games, aside from stuff like holing-up or strafing. What’s more: the building strategy can also be seen as ‘shooting’ defenses—you are adding to the environment—it is a constructive, perhaps aggressive, kind of defense.[2]
That’s what seems to resonate with bloggers: not the publication of a first-person journal but the chain of interaction it often ignites.
— p. 170, JD Lasica, “Blogging as a Form of Journalism”
This chain of interaction can manifest as a scorching backdraft. And that is not usually what you are trying to ignite. We like to think that we are kicking off a fantastic, fulfilling discussion that moves the world forward—but the chain is well outside of our control.
(My initial thoughts to ‘controlling’ such a thing is… defensive in the Fortnite sense. Many hypertext writers now build layers around their writing. Nadia Eghbal has direct interaction through Twitter, indirect interaction through polished essays and a newsletter—but also, concealed interaction through an unadvertised notes page that is not easily syndicated or followed. Similarly, representing the public-self modelers—h0p3 has a home page entry point that is carefully curated and groomed, but which is several layers up from a complete chaos of link dumps, raw drafts and random introspections—all of which you can only sort through by learning his curious conventions. You are on his turf. These layers run a spectrum of accessibility—there is always a learning curve before you hit the bottom. You start with a doorway before entering a maze.)
I do think what this has left me with so far is two very clear impressions:
So, while certain writers in this book seemed to look at the blog as a fully-realized literature format - and perhaps it can be that to some - for me, I see it as a conduit between writings and creations - a place where some of my own words fester and pile up, as a kind of byproduct.
Lastly, there’s no question that we are far from a mature view of hypertext. I feel that much of the last two decades has been spent just trying to emotionally process what our open exposure on the Internet means. These bloggers lived during an early expansion when the population was much smaller. The extreme growth (along with stuff like constant mobile connections and the Snowden discoveries) has transformed the Internet into a very public, chaotic place.
Developing a blog/wiki/etc demands writing, editing, publishing and even relationship chops. I’m not even touching the journalism, entrepreneurial and community-building aspects that this book focuses on at times. Trying to do this in a disciplined way is difficult in the changing landscape - partly because so much of our discussion necessarily revolves around examining that landscape.
p. 5. “[so-and-so] grouped a bunch of webloggers into high school cliques and called me a jock” the shit-talking begins, this is comfortable, nothing has changed.
p. 5. “Dave decided I must be ‘brain-damaged’ because I used frames.” first
thought: this is worthy of publication? second thought: oh, wait, these are
raw blog posts republished. third thought: 
Tracked down the Dave Winer post myself, to ensure ‘brain-damaged’ was the actual wording. (It was.) Quote just below it:
Dad says I shouldn’t criticize other people on my site. He’s right, in theory. But in practice, what I don’t like is just as much a part of my personality as what I do like.
— Kate Adams
(Personal aside: I once criticized the cover of a Philip K. Dick book publicly on the Internet. The only response my post receive was from the illustrator that had designed the cover. She basically said: “Thanks, that hurt.” You might think she had no business replying to my post and should have just taken the criticism. But she didn’t like my criticism - which is “just as much a part of her personality” as anything else, I suppose.)
p. 9. Good Rebecca Blood quote: “These weblogs provide a valuable filtering function for their readers. The Web has been, in effect, pre-surfed for them.”
p. 11. There seems to be a recurring theme that Blogger made blogging “too easy” by just having a single textbox to post in. Didn’t realize it was that much of a progenitor to Twitter.
p. 12. Filters as their own thing: “I really wish there were another term to describe the filter-style weblog, one that would easily distinguish it from the blog.”
(No indication of the tools available to the ‘filter’ blog are given - except that it has access to other filter blogs. Also, there are about five different blog types alluded to - none of them matter now.)
p. 18. The author seems to say that communities, in order to survive, must stay small - and credits The WELL with the best approach. I don’t know The WELL - but it’s still here today. Wonder if it is considered intact…
p. 20. The term ‘webpools’ is used here several times. There are many, many outdated terms and awkward language choices in these essays. These are really cool to me because the language was in such flux - and it reminds me of how repulsive the word ‘blog’ was at first. (I invent crappy words, too - guilty.)
p. 27. Having a good ‘link checker’ is mentioned. Interesting that this technology is nowhere to be seen now. (Href.cool has a simple, dumb one I made - but it’s proven essential.)
p. 31. Some discussion about crediting sources. The discussion is basically “this is a virtuous thing to do” vs. “it clutters up the blog”. This misses the point (imho) - the point is to aid discovering related blogs.
p. 32. This is so funny: “But what about a weblog for the homemaker?”
p. 32. “Wouldn’t it be great if all the neurosurgeons in the world had one place to go for up-to-date information about the numerous changes in their field?” No. Hard no.
p. 35. The need for one’s own domain name. I used to think this wasn’t very important. Starting to come around.
p. 37. “fram” - friend spam. This was nostalgic - ahh right, basically, e-mail forwards were the Facebook of that era. Again, recurring theme of: people need to become better, more disciplined independent writers and publishers. That is what the Web asks of us.
p. 43. omgz, a spoof of “we didn’t start the fire” in the middle of the book. “Wetlog, BrainLog, NeoFlux, and Stuffed Dog…” this is amaaazing.
p. 49. beebo.org?? wtf, this is the second time this has come up. “a blog best-seller list”? The captures on Internet Archive do not explain this well enough for me.
p. 51. It’s becoming clear that Blogger was the poster child of its time. Strangely, people don’t really trace the lineage of Twitter or Tumblr back to it - nor does it come up in the Friendster, Myspace, Facebook dynasty. It’s just kind of this useful website that appeared and is still here. Strangely, Google has managed to keep it low-key, ad-less, customizable - seems like a completely ignored utility. There even seems to be a “New Blogger” dashboard for mobile. I wonder what keeps this thing going?
p. 52. Fears about blogging becoming “too easy” - leading to “blogorrhea”. Yeah, that panned out.
p. 54. The Bicycle story. This seems like some kind of a precious take on memes. Or, alternatively, a satire on a template blog post. The self-loathing returns.
p. 59. Damn, this is serious shit-talking!! (Like on the level of Bernhard’s The Woodcutters.) I need to talk about this in more detail later.
p. 68. Blogs as “exteriorized psychology”. Sure. But no. Hard no.
p. 70. Where did Jorn Barger go? Seems like perception that he was antisemitic turned against him? Nah, it’s got to just be burn out or something. Everyone should retreat from the pulpit at some point. (Actually, not sure why I’m asking where he is - most of these blogs are vacated. I think people didn’t want out of blogging what it ended up giving them. There was definitely something of a gold rush.)
p. 76. This Julian Dibbell has some good stuff. “Does it even count as irony that Barger’s rigorously unfiltered perspective is perhaps as good a filter as can be found for the welter of the Web?” This is a good question! And it really confuses the topic of what makes a good algorithm or a good editor. The discussion kind of stops at: it’s a sensibility.
p. 78. Blogger was a one-man business in 2001 after initially having a team. It really squeaked by. This is cool. It actually survived.
p. 82. “I do think there was a blog concept. Then there were a couple blog concepts. And now we’re getting closer to a blog concept again.” Lol. I think we’re back to a couple blog concepts again.
p. 87. Comment about 2001’s “p2p hype” drowning out interest in blogs. It’s interesting that blockchain took that space for awhile. And it’s interesting that some p2p+blog projects have a niche community now. It’s also interesting that those were seen as competing at the time - I can see how people would think that, but those were clearly two different crowds.
p. 89-98. No real interest in this chapter (on the Kaycee Nicole Hoax) - although veracity of information continues to be a big topic. Was a topic in the radio and newspaper eras, too.
p. 103. “[Blogs are] nothing new, they’re not changing the world with their content, they’re not going to make anyone huge amounts of money, but they are a form of self-expression and community which others enjoy reading.” (Finally, some tempered enthusiasm that’s grounded in reality. No one in this book even considers that blogs might have been a fad - which is a reasonable appraisal given that blogs have almost vanished within the past ten years.)
p. 112-115. An actual essay on link-hunting! It’s rather thin, but it’s a good start. Most of the sources listed in this article are gone now. (Except mailing lists - though they aren’t nearly as prevalent.)
p. 124. “linkslut” (Sick, this is me.)
p. 131. “… most popular weblogs function to serve up the piddle and crap the authors either don’t have time for, don’t believe worth taking any further, or perhaps are testing the waters for.” (So: people know they are writing for free and withhold their best work. Really makes me grateful for insanely high-quality essayists out there like Nadia or Toby.)
p. 138. Kottke is a serious target in this book. He is quoted here, talking about his laptop bag. The writer then basically says, “See, this is the epitome of decadent navel-gazing.”
p. 141. This Blogma 2001 stuff hasn’t aged well. The satire is just thinly veiled bile. Which is not a problem. It’s just that the target of this piece (“A-list” bloggers) is not interesting. Maybe it’s too easy. (Like a satire on modern influencers - who cares.)
p. 144. In a section on blogging tips, called “Anonymous Is Okay.” ‘If you are being
anonymous give some hints about you from time to time. “I am a fat boy!”’ 
p. 152. This has really gone downhill in the last few chapters. I’m now in an essay on how to get noticed. “Also, when sending email, try to be funny” - oh boy. And yet, this is exactly what you expect in a book titled We’ve Got Blog from 2002. (This essay does highlight that self-promotion was very awkward even then.)
p. 155. “Once in a while remind yourself that you are not only as good as your last update.” (Based.)
p. 164. Referring to a time in the late 90s: “Then reality set in and those individual voices became lost in the ether as a million businesses lumbered onto the cyberspace stage, newspapers clumsily grasped at viable online business models, and a handful of giant corporations made the Web safe for snoozing.” (Had to do a double-take on this one! Were they talking about 2011?)
p. 166. Reference to Paul Andrews’ “Who Are Your Gatekeepers?” Sounds worth reading.
p. 166. “Where the weblog changes the nature of ‘news’ is in the migration of information from the personal to the public.” (Premonitions of Snowden. Regardless of whether you think he was successful, in this respect he certainly was.)
p. 167. The rest of the essays in this book are by amateurs, so they look at editors at entirely superfluous. This section is written by journalists, so they seem to see it just as a tradeoff. Yeah, for sure. (As a reader, it certainly seems valuable to evaluate online writing on a spectrum of heavily-edited and fact-checked vs. off-the-cuff - depending on what you are getting out of it.)
p. 170. “One of the most interesting things about blogs is how often they’ve made me change my mind about issues. There’s something about the medium that lets people share opinions in a less judgemental way than when you interact with people in the real world.” (Eh? This seems spurious. The medium is still just the written word. I think what you’re trying to articulate is that you never quite know what you’re going to end up reading online - so it’s possible to be exposed to arguments you haven’t encountered. Hence all the talk about people being accidentally radicalized politically.)
p. 170. “That’s what seems to resonate with bloggers: not the publication of a first-person journal but the chain of interaction it often ignites.” (Yes. Hard yes. This explains the migration to social media. Quicker, faster, immedate sparks of interaction.) (It also occured to me at this point that ‘likes’ and such are analagous to ‘hit counters’ from this age.)
p. 171. The editorial process produces writing that is “limp, lifeless, sterile, and homogenized”; blogs produce words that are “impressionistic, telegraphic, raw, honest, individualistic, highly opinionated and passionate, often striking an emotional chord.” (I really don’t like that this paints a picture that writing just got better all of the sudden because of blogs.)
p. 192-193. During an essay which completely demolishes the war blogs of the time, Tim Cavanaugh quotes a full page-and-a-half of shameless gladhanding. ("…the consistently correct Moira Breen." “Mark Steyn—this guy is so good!” “…Natalija Radic really hit them where it hurts.”) (It goes on and on. This seems similar to current questions of ‘virtual signaling’. Which I don’t have a problem with generally. Really: what should a personal signal? I think the problem here is that the concept of a war blogger is gross. So perhaps it is the incompatibility we see between a person and their signal.)
p. 195. “For all the bitching they log about the mainstream media, none of the bloggers are actually cruising the streets of Peshawar or Aden or Mogadishu. Thus, they’re wholly dependent upon that very same mainstream media.” (Well, the mainstream will always exist in some way - as a baseline of culture, as a central point of reference, like Magnetic North. Therefore, we’re dependent on it. And we move ourselves around it by defining our various loves and hatreds of it. And, in this case, I think it should still be safely used as a resource. Also, ‘it’ is actually a massive, pluralistic, infinite, incongruous organism.)
p. 228. ICQ as “I seek you.” Durrrr. I never caught this! Wowwww. 
Definitely in the way Joe Jennett or Eli Mellen does it—and also h0p3’s link logs. I think tumblelogs and Delicious innovated in this department. ↩︎
Many shooters allow you to project or throw force field areas. So this concept has been around, to some degree. I don’t know the lineage—I’m not a gamer. ↩︎
A few days after writing this, Nadia posted “Reimagining the PhD”, which casts her last five years as a kind of self-styled doctorate - which will now concluded with her publication of a book on her field of study. ‘Rolling up’ a blog into a formalized work is parallel. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Promised I’d do this after getting Fraidycat out there. This regular feature is back: me hunting in the brambles, coming back up with 22 newly discovered blogs from a variety of sources, mainly 8 threads and blogrolls out there. Raw dump. Good quality.
Promised I’d do this after getting Fraidycat out there. This regular feature is back: me hunting in the brambles, coming back up with 22 newly discovered blogs from a variety of sources, mainly 8 threads and blogrolls out there. Raw dump. Good quality.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘Accept that the Web ultimately overwhelms all attempts to order it, as for now it seems we must, and you accept that the delicate thread of a personal point of view is often as not your most reliable guide through the chaos. The brittle logic of the hierarchical index has its indispensable uses, of course, as has the crude brute strength of the search engine. But when their limits are reached (and they always are), only the discriminating force of sensibility will do - and the more richly expressed the sensibility, the better.’
— “Portrait of the Blogger as a Young Man” by Julian Dibbell (2000)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Master list of essential links—seems pretty dead-on. Href.cool picks up where this left off.
This is GREG RUTTER’S DEFINITIVE LIST OF THE 99 THINGS YOU SHOULD HAVE ALREADY EXPERIENCED ON THE INTERNET UNLESS YOU’RE A LOSER OR OLD OR SOMETHING—a tiny directory, just a single page, a dump of links, mostly YouTube videos really. An additional 99 links continue at youshouldhavealsoseenthis.com—which fills in some missing pieces (‘i kiss you’, ze frank, etc.) It’s missing some things (‘hello my future girlfriend’, Real Ultimate Power) but perhaps those things haven’t aged well and this isn’t necessarily designed to be historical.
I wonder to what degree YouTube is synonymous with Internet culture out there. I can definitely see it—especially since ‘trololol’ and ‘double rainbow’ were pretty monumental for me—but some watershed stuff (like maybe when Cards Against Humanity gave away an island or the heyday of Chat Roulette) just can’t be captured in video like they existed on the network at the time.
Anyway—inspiration to anyone working on a directory. No need to overbuild. A raw link dump is just fine.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

A most pathetic surveillance tool.
I have been dumping time into Fraidycat—the tool I use to monitor the Web (blogs, Twitter, YouTube, Soundcloud, what have you)—in an effort to really increase my ability to stay up on reading you all. I’m going to be releasing Fraidycat on Nov 4th—but you shouldn’t feel any obligation to use it, because it’s geared toward my own purposes, but I hope it might inspire someone out there to design even better ‘post-feed’[1] tools for reading the Web.
Just a heads up, though. It sucks. Here’s why:

The reason it sucks is because I am trying to make it an independent tool—it shouldn’t rely on a central website at all. (It also sucks because I suck, duh!)
The fortunate thing, though, about right now—is that everything else sucks, too! We traded all these glorious personal websites in for a handful of shitty networks that everyone hates. So using Fraidycat is actually a nice breath of somewhat non-shitty air, because you can follow people on all of those networks without needing to immerse yourself in their awfulness.
Here is what it looks like today:
So, yes, it does reward recency. But not as much as most platforms do. No one can just spam your feed. Yeah, they can bump themselves up to the top of the list, but that’s it. And, if I need to bump someone down manually, I can move them to the ‘daily’ or ‘weekly’ areas.
Imagine not needing to open all of these different networks. I tire of needing to open all of these separate apps: Marco Polo, Twitter, Instagram. My dream is that people can use the platforms they want and I don’t have to have accounts for them all—I can just follow from afar. Gah, one day.
And, actually, the worst part is that all of these sites are tough to crack into. For most blogs, I use RSS. No problem—works great. Wish I didn’t have to poll periodically—wish I could use Websockets (or Dat’s ‘live’ feature)—but not bad at all.
For Soundcloud and Twitter, I have to scrape the HTML. I’m even trying to get Facebook (m.facebook.com) scraping working for public pages. But this is going to be a tough road—keeping these scrapers functional. It sucks!
I wish there was more pressure on these sites to offer some kind of API or syndication. But it’s just abyssmal—it’s a kind of Dark Ages out there for this kind of thing. But I think that tools like this can help apply pressure on sites. I mean imagine if everyone started using ‘reader-like’ tools—this would further development down the RSS road.
I should say that I think we can do better than RSS. Or maybe just—we need more extensions. A few I’d like to see:
I will get back to my other projects (indieweb.xyz, my href hunts) once this is released. I really appreciate Jason McIntosh’s recent post about Bumpyskies, partly because I just like to read about personal projects—and it’s difficult to write about them because self-promotion has become quite shameful—however, I don’t know how we get out of the current era of corpypastas without personal software that makes an attempt at progress.
As in ‘news feed’ not ‘RSS feed’. Part of the idea here is to move past the cluttered news feed (which is itself just a permutation of the e-mail inbox) where you have to look through ALL the posts for EVERYONE one-by-one. As if they were all personal messages to you requiring your immediate attention. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Gabby Lord’s tiny directory—a perfect example of what (I feel) the Web needs!
Often when designers make home pages, they throw out a bunch of cool CSS tricks and aesthetic trimming and I celebrate that—but often there’s not much there in the way of interesting hypertext stuff. In this case, Gabby Lord’s OMGLORD has a nice minimalist design that frames a solid personal directory of links. There’s clearly been a lot of work done here—probably 200 links with nice descriptions and her own set of categories—stuff like ‘type foundries’ and ‘women in design’. I had a lot of fun coming up with categories for href.cool and I think she’s got a great organization here—also, starring her most recommended links is sweet.
I also think her City Maps category is reaaaally cool! She links to Google Maps that she’s personally annotated with sights, parks, coffee shops. These are directories within the directory. In addition, it’s a really nice way to build a directory of real-life stuff.
If you have any distaste for algorithmic recommendation engines or the commercialization of the Internet, I urge you to make a tiny directory! Gabby’s directory is just her favorite cool links—it’s not influenced by advertiser money or link popularity—except that perhaps Gabby discovered some of these through those kinds of avenues—these links have proved worthwhile to her over time. You may feel some resistance sifting through her pages, because why am I looking through a personal page when I could reading a slick major publication or wielding a powerful search engine but you will find things here directly, person-to-person, with no ulterior motives between you and these links.
It’s great, right?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘…unlike things being adjacent to each other.’
Great comments. Even without algorithms, this can be trouble—on subreddits, posts can be flagged ‘offtopic’—so overboard moderation is a problem. (Of course, Reddit is where one goes to fully ‘engage’. No /s—it’s fine to do that. Problem is: people may not know where to go to get outside of ‘engage’ mode.)
One thought I’ll add re: getting outside of my own interests—I think if we had better tools for keeping tabs on our interests, we could more easily move outside them. (Like: if my ‘reader’/‘news feed’ makes it difficult to track 100 people, then I can’t very well track 1,000 people.)
And directories are sweet here—they are little libraries. Sure, they can cover your interests. But they can be used to map the strange elven lands that you happen to sally in.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
If you want to make yourself a tiny directory, it can be this easy…
So this is one of the closest things I’ve seen to my href.cool directory—a big page of bookmarks, assorted ‘interesting’ reads all listed together under some ad-hoc categories (biographies, celebrity, war). And, perhaps more importantly, little blurbs for each one that are really well-done, in that they convey a lot of ‘feeling’/‘synopsis’—I actually enjoy just reading the whole page, to get a sense of this person and what’s out there in topics that may not appear to interest me on the surface.
I think I want to make the argument that building a directory like this is a more, I don’t know, ‘worthwhile’ effort than just leaking out links here and there as you find them. This is a great thing for ‘hypertext’ or a ‘website’ to aspire to be.
A few thoughts:
The page says ‘March 17, 2016’—does this mean the page hasn’t been updated since then? This must be wrong—there’s a link with ‘2017’ in the title.
There’s a bullet point in the ‘sex’/‘gender’ topic that just says: ‘Economics of sex’ with no links. Wonder what’s up there? A placeholder?
Reading this has made me realize that I think I need domain names displayed next to the link. It would be nice to know where the link goes before you hover it. (And mobile doesn’t have this option.)
I also really like this person’s 1,000,000 words project. 1,000 essays of 1,000 words. This one functions like a mini-directory as well, actually—like a mind map or… well, there are links in there as well. It’s sort of like if you could browse a portion of h0p3’s wiki as a linear, chronological conversation.
I hope you’re getting some ideas now.
UPDATE: Hold up, wait, wait—this is rich: visakanv.com/blog/communities/. A kind of hybrid ‘directory’/‘blogpost’ strictly on moderating and building communities.
It is my experience that, if you create a safe space for a minority group, sparing them the stress of having to explain themselves to clueless outsiders, the level of criticism, argument, discourse, etc inside the group INCREASES. People challenge and spar with each other.
Sweet take. I also just think we have someone here who is really good at collecting. Taking note.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Href huntin’ by Andreas Zwinkau
A few days ago, there was a thread on the link-sharing site Lobste.rs entitled: “What are your favorite personal websites around the internet?” So this was a great thread for href hunting. In fact, commenter ‘qznc’ dropped a link to /r/SpartanWeb—a subreddit collecting custom personal websites. qnzc is Andreas Zwinkau.
Andreas’ term “Spartan Web” indicates websites that are:
Interestingly, I’ve seen a bunch of recent articles praising HTML and attempting to foment a return to HTML. Writing HTML in HTML—someone who started a new blog without any type of an ‘engine’ or static site generator—it’s all just custom HTML. Words and Buttons Online, a directory-style personal page.
One thing I’d love to see is some static Indieweb HTML (in other words: microformats) where you can copy and paste pages to add blog entries. Then an index page where you can add a link to that page and JavaScript can optionally add in date/time/author details from the link. It could also use Webmention.io to load comments over JavaScript.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, thank you—I am with you on this as well. It sounds like we might be in agreement that there is much innovation to do in the spectrum of ‘feeds’/‘filters’. I think I also agree that needing access to the full post contents is useful—otherwise we end up with titles dominating and our filter weighs toward attractive headlines.
Re: ‘heat maps’—I’m reluctant to give any thought to the popularity of a writing. Yet, there’s no doubt that it’s important. If people are congregating, it’s worth knowing what the fuss is about. (I found your wonderful essay through Indienews—and this is a case where checking there has made it all worth it.) But I don’t want the zeitgeist jerking me around all day—think of it as a literal “ghost of The Now” pushing me around—I just want to peek at it usually and then move on to reading those things that are being overlooked.
I’m not saying you are wrong to prize that higher for yourself—I think perhaps the most innovative thing that can be done is to provide a variety of views on this filter—maybe RSS readers have just been too narrow by making themselves simple ‘inbox’ clones. We are trying to wrangle a lot of data here; we might need something quite configurable to do this task. (Which is contrary to my own reader—which I have been designing to be extremely naive.)
This is getting away from the juiciest part of your article, though: that there are serious human skills to build up. Reading and filtering. (I like your tag: ‘infostrats’.) But your mention of ‘heat maps’, for instance, reveals that our tools can improve with respect to enhancing our ‘infostrats’. Thank you for the further thoughts, Ton!
UPDATE: Okay, after looking through your archives, I can see that this reply was hasty. It’s amusing to me that you actually cover much of this in your discussions about ‘small tech’. Your essays over the years are a formidable work. I find myself very much in agreement as I read!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Cripes! I think this is the best essay I’ve read on how to read the Web. I agree with all of it.
I am definitely going to read this article several times before properly responding to it. But this is insanely rich stuff. I completely agree with and recognize the entire filtering strategy as my own. Feeling some kinship there.
As for the feed reader, it’s even worse: my own prototype (Fraidycat) is very close to what you describe. I assign feeds ‘importance’ levels that are much like ‘social distance’—I’m trying to decide if that term nails it for me. I’m not sure yet! It’s a good one, though.
I think the one area where I am not sure is still having to deal with a ‘news feed’-type stream of posts in each of those folders—is that your ideal way of reading? I feel like it focuses too much on recency. I’ve been enjoying just seeing a pulse of recent activity and then needing to visit their site to actually take it in (and perhaps explore further).
I definitely feel like the ‘social distance’ thing has helped crystallize why I put certain people into different ‘importances’—and it’s not just because they are actually more ‘important’ (like: to the universe). Anyway, brilliant!!!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Extraordinarily simple, useful, sweet.
I’ve linked to Phil Gyford last year in the post Timeline of Things Phil’s Done, which I am happy to link to again, because I recently worked on a timeline of a friend’s life and used this as a starting point. Timelines are a rich, underused visual catalog for hypertext.
Phil has just added a blogroll to the same website. This seems uneventful, except that:
The design of the ‘writing’ section is fantastic—while completely minimal and faintly ‘brutalist’—am I close? If you are starting on a new blog, look at Phil’s. I’m all about aesthetics and colors—but it’s usually a far second place to organization.
And I must ask: do you have a blogroll? Google would prefer you not to. But it’s the smallest, most atomic tiny directory—akin to ‘little libraries’ you see on the roadside.
Every single one of these links works! This is a watershed moment in 2019.
Find someone new to read today. You might find a friend. You might read something that really changes you. The world might seem a little more alive again.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Dozens of new links, many from Imperica’s ‘web curios’ roundup.
Just as things had a big effect on me last month, such is the discovery of Imperica—particularly its ‘web curios’ posts, which are MASSIVE link roundups like you’ve never seen before. These are exhaustive and tremendously exciting. So, having now read back through the last several months of Imperica, let’s look at the effect on href.cool…
Added to Bodies/Inanimate:
A new category, Bodies/Primitive:
In Games/Dialogue:
In Games/Imagined:
A new one for Real/Paced:
I’ve expanded the Web/Wiki page, by adding a note on h0p3’s Wiki, listing the various wikis branching out from his family.
To Stories/Paneled, an obvious link I neglected to add:
To Stories/Folkmeme:
An obvious omission from Stories/Poems:
Brilliant addition to Tapes/Classic:
AND OF COURSE (to Visuals/Zines):
Forgot this one in Web/Participate:
Also add a link to spoon.nagoya under the Real/Person topic. And a link to Neave.TV, alongside the unlisted YouTube video links.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘We’re the kind of haphazard store that’s run by a shopkeeper/hoarder who won’t necessarily sell you something if he doesn’t want to…’
Continuing the recent theme of Roundups, I couldn’t resist checking in with things magazine, which has been a rich source of wonderful linkdumps for nearly two decades. There is also a popular Tumblr attached and a print journal that predates the blog.
I make many efforts to contact folks doing good work, but often can’t get a reply. My blog is as underground as they get and I wonder if my e-mails or DMs ever go anywhere. I was so glad to have this conversation with J—and I still have many questions, so I hope our chats continue.
kicks: You’ve all been on the web since 2000. In a way, this isn’t that special—blogging exploded around this time. But you kept going. What keeps you blogging nineteen years later?
j: It’s a habit, as much as anything else (although the site is currently on one of its temporary hiatuses). One of the original motivations for things was as a store of interesting links that I could refer back to, relating to my interests and those of contributors to what was once a print magazine.
But our link style is quite obtuse and it doesn’t really work as a searchable archive. So it’s more of a collection of moods—both mine and the culture at large.
kicks: Ok, wait, go back—hiatus? Not sure what to make of that! Your post today, for example, is a mean one. A rich trove of links. That had to take some hunting. Overall, I feel like your writings this year have been quite regular.
j: Yes, today’s post was a bit of a surprise. I’ve been building up a collection of stuff these past few days. I had meant to stay away for longer. Maybe our conversation inspired me.
kicks: You recently (briefly) mentioned the disappearance of what was once a whole ‘blogosphere’, saying, “our own blogroll is home to many an abandoned project…”
Even the blogroll itself has disappeared out there. Why do you think that is? Perhaps because they became difficult to keep up? Perhaps there’s a sense that linking isn’t worth doing any more unless it’s as a ‘like’ or a ‘friend’?
j: There was definitely a circularity to early blogging, links that were shared and directions travelled together. One by one people have fallen by the wayside. I guess it’s all there in the Wayback Machine, but occasionally I find a ‘traditional’ style link blog that transcends the awful ‘like and subscribe’ ethos of today’s internet.
kicks: Mmm, ‘circularity’—yes, when you say this, I’m reminded of how certain links would dominate all the blogs simultaneously—like when The Grey Album came out. But I think ‘circularity’ applies also in describing the currents that were flowing between these blogs.
It was just easier to get caught up in hopping from blog to blog and finding dozens of fascinating links in a given day. And not just the links—the blogs themselves were often the most fascinating finds. (One blog I was really into at the time was Sharpeworld—a lot of transporting, campy videos and links.)
Actually, let’s do this—if you were to envision a new future for blogging, a kind of renaissance—what blogs (new or defunct) do you wish were at the heart of this?
j: I loved Sharpeworld too. And Haddock.org, diskant.net, ilike.org.uk, a.wholelottanothing.org, textism.com, slower.net, plasticbag.org and many more.
I don’t necessarily think there needs to be a new future for blogging though. The heyday has passed, that’s all. Most forms of creative expression in most mediums still exist somewhere for someone. They just have to adapt to a quieter world. I check our traffic most days, out of habit—it’s not terribly impressive by any standards and is on a long-term downward trend…
kicks: It seems like things has kept an eye on communities like MeFi, Delicious and Tumblr over the years. Reading through your blog, I was reminded of those years when mp3 blogs were exciting. These communities always seemed like little underground holes or out-of-the-way clubs. Even Tumblr and Blogspot felt that way, because blogs have a lot of individuality. Any new communities springing up that excite you?
j: Not so much Delicious, because I always felt a bit late to that party, but I’ve long loved MeFi (although that’s feeling a little rusty these days as well). Tumblr I have a lot of affection for, although I still haven’t really forgiven it for killing off fffffound. Communities have become necessarily more niche—a forum here, a forum there—but there’s nothing I’d consider sticking my head up above the parapet for.
kicks: You usually cover art—which still has an enormous presence on Tumblr and Twitter and such—but are ‘net.art’ type works dead? Perhaps this isn’t in your wheelhouse—are there still artists that work with hypertext or is that just the domain of designers now?
j: ‘Net.art’ was a diversion and still exists, but it feels like the interesting hypertext/digital work is coming out of graphic design these days, not fine art. Art has moved on, whereas the applied arts have a much greater sense and understanding of the power of nostalgia.
kicks: Do you mean like stuff you might find at CSS Design Awards? (Like, I think of Erik Bernacchi’s site or Lynn Fisher’s 2017 site.) I think I have a theory about this.
Which is: I think it’s so much tougher to be subversive with HTML now. Much of the original hypertext art messed with HTML frames and pop-up windows. I remember some of these sites spawning lots of little pop-up windows and orchestrating them. That would just never be possible today. Even autoplay and MIDI is restricted now.
j: In terms of art I take your point about it being tough to be subversive on the web—everyone’s online experiences are very tram-lined these days and any deviation from expected standards of usability are massively frowned upon—they’re either seen as offensive or even potentially dangerous so even the slightest hint of a browser or data hijack are right out the window. The stakes are much higher, I guess. Whatever, art moved on a while ago. The internet is a vessel but no longer a medium.
One of the ongoing motivations for things is the idea of mental as well as literal links, that sense of disparate things being related somehow, or a path leading somewhere. That was the big dream of hypertext, which was supposed to be a literary as well as an informational device.
The only place that still really works are sites like Wikipedia or TVTropes, where you still get that sense of burrowing down through layers and layers of information. I like this because it mirrors thought processes, and the way in which you have to mentally rewind to get back to where you started from. It drives me mad when publications add self-referential hyperlinks that simply send you around a closed loop.
Must check out TiddlyWiki…
kicks: things Magazine as a ‘personal store’ and a ‘habit’—these reasons for continuing have nothing to do with an audience. This is a very common theme among those that I find still hypertexting.
There is a growing number of TiddlyWiki users—like h0p3 at philosopher.life and Phil at youneedastereo.com, my friend sphygm.us—and it takes real work to sift through what they’re doing. They are dumping raw notes and drafts on the Web. In some way, I think this is related to the ‘obtuse’ linking style you use—dense, really requiring something of the reader.
Now that you are many years into your habit, how do you personally use this ‘store’?
j: Sadly it doesn’t really work like that. I never mastered the art of tagging stuff so the tools on the site are of limited use. There’s an archive page I built a decade ago when I knew how to do that sort of thing but it would be great to have some kind of random access button the front page. Right now, we’re the kind of haphazard store that’s run by a shopkeeper/hoarder who won’t necessarily sell you something if he doesn’t want to…
kicks: This is an amusing reply to me—I’m of two minds about seeing things as ‘haphazard’. It’s deceptive—the blog layout itself is quite the opposite—neat and crisp (and this is true of your Tumblr, too) and even a lot of the visuals that you snip are geometric. One’s perception immediately connects it with a museum or card catalog.
Yet, I see what you’re saying. You often will spill twenty different links in a paragraph, sometimes with very little assistance as to what is beneath that link. And I’ve seen posts where you dump a pile of random Tumblrs with short cryptic titles in a long run-on sentence. You switch topics mid-paragraph. A paragraph will go from a cohesive thought into a kind of, yes, ‘haphazard’ link poem.
To many of these TiddlyWiki users, the wiki acts as a model of themselves—not a straight download, of course, but a pretty thorough map of their thinking and personality. things is not this, perhaps more like a construct of Borges—where you have the external appearance of a literate, orderly castle which is much closer to a labyrinth of madness within. So, if this is my picture of things—how does this compare with your initial intentions for it? How does it compare with where you think it might end up as?
j: ‘Link Poem’ is a good description of what we do. things was always a work in progress, both as a magazine and then as a website. It has calcified slightly from its early days when we’d also post longer pieces by other people (they’re all buried there somewhere)—maybe that will one day return. There were never any intentions, save perhaps to boost the profile of the magazine and help sell copies (that didn’t work). Long term, I just don’t know.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Sorry to linkdump again—this is good!
I generally link, but now I am going to leech. He already posted this to /en/linking, but this list of assorted links that Joe has added to his pointers is just a blast. (I’m tempted to comment no further, since it’s fun to just explore the list without any direction.)
Nevertheless, I have to point out:
The XXIIVV Wiki: I’ve wandered into the XXIIVV Webring previously. But this wiki of projects is damned impressive—both for its ambitions and for its actual hypertext.
Cosmic Voyage: A small text-only community for story building. This has captured the spirit of dial-up bulletin boards in a way that I haven’t seen in decades. I’ve seen this here and there—glad to see it thrive.
Chris Burnett: Fly gradients. The now page is the best I’ve seen. I like that it becomes a timeline. For the first time, I understand this phenomenon.
Tales Through Photos: I just love the mood of this. No big deal. A site like this will never go viral. It’s just too light, just ‘I saw a Downey Woodpecker’.
Bloganueva: Web dev at the National WWII Museum. Brilliant colors. @marsh on micro.blog.
The Web just keeps getting bigger. Can’t believe the encouraging work I find each week. Get in here, all you folks out there.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Eleven new additions, mostly to ‘Crimes’.
My recent re-discovery of Things Magazine (probably from one of you, don’t recall now) and my own readings on crime-related topics have yielded some links that need to be permanently hung onto.
A new category, Bodies/Food:
Added to Crimes/Simple:
Added to Crimes/Impossible:
Spring-heeled Jack
Article 5m
The impossible leaping skill of this urban legend (ripped from the penny
dreadfuls of the Victorian age) had such a technological flare. Ah, the idea
that an inventor-cobbler with a gas-powered dental retainer could inspire
demonic fear. His attacks lasted a century! (Also at
Wikipedia.)
The Garfield Phones Beach
Mystery Article 1m
Who was sending plastic Garfield telephones up the Iroise coast for 35 years?
To Crimes/Lies:
How Golf Explains
Trump
Article 1m
Well, for a 72-year-old, he’d be a six. Six or seven. So he’s good. He’s a good player. He’s among our best presidents ever to play golf. But he wants the world to think he’s fantastic.
I think the best lies are the ones we all get to be in on.
Added to Tapes/Classic:
Added to Visuals/Film:
"Please Help Me Find the Very Best Strange, Trippy Short Films and
Videos"
Directory 5m
MeFi thread. Turns out to be a good intro to animated shorts and music vids.
(Via Things.)
IT CAME FROM… Blog 5m
Interviews and fantasies re: sci-fi and horror films of yore. What can I say?
It’s like candy floss. (Via Things.)
In Web/Meta:
And a new one for Web/Participate:
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The blurred lines between encyclopedia and directory.
I don’t want to sensationalize this discussion or make it sound like a fight: Wikipedia is considering deleting links from about 5,000 different articles which point the reader to the Curlie directory—which is the current incarnation of DMOZ, spiritual successor to Yahoo!'s original directory. The issue is very interesting to me because, while the Curlie template is up for deletion because the directory is considered out-of-date, the argument has essentially moved toward the nature of large directories.
Although link directories are not as important as they were in the past, DMOZ (currently hosted by Curlie) is still recognized as the most important one. Ironically enough, the best contender to link directories today is probably the External links sections of our Wikipedia articles. And we don’t want to turn them into directories.
This is very interesting—because regardless of what Wikipedia intends itself to be, it often acts very much like a directory. (Or else what the hell is this?) I would argue that Wikipedia is a flat-out better directory than Curlie, because it is editorialized. In a way, this seems like it would be a bad thing for a directory—we like to think that a neutral classification of links is the ideal—but I think the intense effort to shape the descriptions and associations between links is motivating to the editors that have to keep the directory fresh and useful.
And, plainly, I just think a Curlie-style directory is too dry! Compare Curlie’s Board Games/Abstract category with Board Game Geek’s Abstract page. The generic directory page just comes off as… generic. And, honestly, Wikipedia’s List of abstract strategy games might be even better!
I’m starting to think that general directories went away (and expert pages) because the niche communities are just better. I can see why they were useful at the dawn of the Web.
Curlie, which has been added as a template to articles, is a depository allowing the liberal addition of spam links, so I would go further and add it to the list of banned sources.
I think DMOZ/Curlie has already had its chance to prove itself. I see that there is still potential there—and perhaps its editors can revitalize it—but I think it’s time to take stock of where salient links are living in 2019 and how to push this stuff into the future. (I am not advocating that href.cool or indieseek.xyz are the future—these are just experiments—but hopefully our efforts to reframe the web directory will bear some fruit over the next few years. I don’t see tiny personal directories as winning some war over mindshare or somesuch—I just think they could help us track sites that don’t fit into niche mostly-topical communities and have been lost in the move away from these large open-ended directories.)
I’ve also been wondering if we need a mailing list or a forum or something for parties interested in linking/directories who can’t seem to get on the Indieweb.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A new dump of personal website links, discovered in the last month.
Don’t know if personal websites are catching on again or if it’s all about finding the right vein—I am getting more and more impressed with what I find, what people are up to. I’m also finding more and more that are already all hooked up to the IndieWeb.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Well, I disagree. (Though I think your record of things is correct!) Certainly if you look at this as a bot war then Google’s actions make sense: we need our bots to outsmart the ‘bots’ (human bots even!) that are writing blogs.
But look at it another way: you have lots of humans writing - and it’s all of varying quality. Why not let the humans decide what’s good? The early Web was curated by humans, who kept directories, Smart.com ‘expert’ pages, websites and blogrolls that tried to show where quality could be found. Google’s bot war (and the idea that Google is the sole authority on quality) eliminated these valuable resources as collateral damage.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
There is a nice discussion about the Web happening on HN today: news.ycombinator.com/item?id=19604135 Specifically concerning Google’s ‘forgetting’ of it.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Times like this, it sure pays to have your depth of knowing what’s out there—YOUNG-HAE CHANG HEAVY INDUSTRIES is definitely a classic. One that you’ve now introduced me to. I finally took the time to browse it. What an inventive take on a blog. (Or on poetry?) Since 1997. My humblest thanks, Joe.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Mystery.miami?  As Kottke has said: it’s too bad beyonce.horse is taken.
As Kottke has said: it’s too bad beyonce.horse is taken.
There’s a style of site I really dig and I find things often and send them to pinboard, but I don’t really use pinboard in actuality because it has more than just those cool sites.
Yeah, this was a big reason I started href.cool. Pinboard is so awesome. But whenever I start to follow a user, they inevitably start archiving their tweets—go to /popular/ and note that ‘twitter’ and ‘ifttt’ are tags full of noise.
Far be it from me to tell people not to use Pinboard to archive. If you do use a Pinboard, just tag everything in your ‘directory’ with a unique tag. Like ‘mystery.menu’, for instance. Then, people can watch your directory using https://pinboard.in/u:kevinkovacs/t:mystery.menu.
I really appreciate your encouragement. If you would have told me one year ago that I would be building a little Yahoo!-style directory, I would have laughed extremely hard and checked the date to see how far into the month we actually were. Yahoo!'s directory was adorable and doomed—but here we are. I think it’s pretty cool for personal use and I’m surprised that you see it too!
I would love to see more directories spring up—and I would look through yours from top to bottom. I wouldn’t have the restraint to stop myself—it feels like an untapped medium.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
You’re always asking me to clear up my terms—and I never do—but I’ll ask anyway: what do you mean by ‘power’? And what do you mean by ‘decentralizing power’? Because my first stab is that you’re talking about getting us back to local governments, tribes or something. The term ‘power’ gets bandied about—it’s the person with the money to hire, the person who radios the tanks when to roll in and when to back out, it’s the person with the megaphone.
I’m not really keyed in on ‘power’—I don’t see it as a kind of natural element. Seems more like it gets used to say: this, this is evil.
How to decentralize power? In a world of billions? Answering these questions is way beyond me. My wavelength is watching ‘humanity’—are we holding on to the transcendent ‘divinity’/‘shittiness’ of being human? Can we see this humanity in each other and at least allow the recognition of another human being to dawn on our faces?
I like to think of it as an ‘antimisanthrophic’ effort to at least establish a baseline sympathy or pity or some kind of comfort with our other peoples. Being a person is rough—we have no idea what’s going on here. Is this the real life? Is this just fantasy? (Perhaps I don’t take ‘power’ seriously enough. If none of us did—would it still be ‘power’?)
I will continue to argue for radical decentralization and worldclass p2p filtering. That is the only out, and the window may be closing. It can’t just be done by hand. We go down if the masses do.
Gah, I’m not convinced that technology has any answers! We can’t make some elaborate mousetrap that will enforce the life we want to live.
Of course, I’m not sure humans have any answers either! But I will say that talking to you and your family is the best technology I’ve encountered in a decade. Sure, I’m reliant on a sturdy free-enough technology that gets our words passed around. And those words are our plain humanity on the wire.
I am worried about some perhaps difficult to justify originality+authenticity moves, but the underground is not more real to me conceptually (though it can be more valid or valuable in the dialectic). I only care about “making it your own” insofar as it is justified to the particulars of your context. The Beautiful is not the overriding reason, but insofar as all other obligations are met, it is the last deciding force. The necessity of preserving freespeech and decentralizing power (including memetic distribution) comes long before The Beautiful though.
You’re not being cryptic—I just think sometimes your compression level is turned up on thoughts like these. I also have to add that I DO appreciate pop culture—I actually think it’s one of the most promising religions or symbolic systems we’ve ever developed. (And it’s REALLY tempting to demonize it, because it’s backup by capitalism—though I think that most people can appreciate the value of the engine—most people seem to agree that artists should be paid.)
Anyway, I don’t think mainstream culture is necessarily any less original or authentic than the underground. I just think that mainstream culture has become imbalanced—it has really captivated everyone this time, and fewer people seem to know how to escape it—which is the purpose of an ‘underground’, to me, and, of course, this is all just my perception.
I think—I think what happened was that, in the previous decade, the Internet gave the underground a tremendous breath of air. You basically had a network that was all underground—and I don’t just mean some kind of hip, stylized underground—I mean that, before the corporations figured out how to milk it, you would search for ‘donuts’ and be at someone’s uncle’s website.
There was no hunting around for rare vinyl or out-of-print Borges novels any more—the whole ‘underground’ world had doorways now. The underground became the mainstream culture and, yeah, we lost an actual underground. And I think there was a kind of crisis of overwhelm that mainstream culture had become so wide—like, “we need robots to sift through all of this.” There was a time when Twitter first came out that people were joking that it was just a bunch of people posting updates that they’re shitting right now. And now we just post those updates, no shame.
What, you want I should call you a selfish nihilist, a brainwashed individualist, an all-too-convenient emotivist, a shallow aesthete, a vapid internalist, a dark-triadic relativist, a deflecting anti-realist, a gas-lighting interlocutor, an actual waste of potential, and a gutless, wallowing, purposely purposeless sissy who hatlessly lacks the integrity to take the existential risk of committing themselves to an identity: i.e., the shadow of my enemy?
The part that actually got me here is the ‘shallow aesthete’ because it’s dead on—I think that I am on the prowl for this guy, but he’s out all the time, spray painting little soap bubbles on people’s suitcases.
I don’t think the point of a personal website is so much to design something pretty and ‘authentic’ (wtf?) or even ‘cool’. I think of it just as having a ‘home’—which seems eminently human to me—as opposed to ‘mechanical’ or ‘hive-minded’, such as being another tweet, lost in the feed.
While I hope for technologies like Dat (and have always loved peer-to-peer since the days of Freenet and Gnutella), the technology is so far from being adequate as to seem impossible at times. So, I’m quite happy getting anyone I can back into personal websites and wikis. Lately I’ve been thinking that ensuring a myriad of ISPs is a lot more important than peer-to-peer.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘You need a human behind it.’
I was trying to explain how blogs could possibly still be relevant to a very young friend—and I was not convincing him.
At some point, though, it clicked—and he cried out, “SHACKLESHOTGUN!” And thereby I was introduced to the extensively researched and annotated link roundups on destinyroundup.com. I’m not a Destiny player—forgive my ignorance—still, I instantly could see that this crafty researcher’s work was intrepid and gifted. And then: wow, she made some time to talk to me!
kicks: Among gamers, Reddit has become a major hub for detailed discussion. I can see your round-ups existing on Reddit—why post them to a blog instead? Especially because Reddit subs are usually hostile to re-posting of blog posts.
shackleshotgun: My roundups existing (solely) on Reddit would go against one of the reasons the site was created in the first place. One purpose of it is being a tool for those who don’t like using Reddit, Twitter, or the official Bungie forums, something for people who want to see all info in one place. People don’t have time nor energy to rummage through three different social medias with awful user experience practices to see if an issue has been addressed by the developers.
Some people either can’t access the sites or don’t want to visit those sites, they just want to have a one stop shop.
Furthermore, info on Reddit and Twitter gets lost very easily because at their foundation those sites are very shoddily structured. Search bar doesn’t work on Twitter majority of the time (it omits results for unknown reasons), and on Reddit the search feature doesn’t look through comments (which is where majority of info is posted by the community managers and developers). Things on my site are archived, and not only that, they site focuses on one thing. You don’t need to dig through a lot of irrelevant info to find out if the developers have said something about a bug.
In order to retain my enjoyment of video games, I stay away from gaming communities. Reddit is quite the offender when it comes to toxicity and harbors content that doesn’t improve my day in the slightest so I don’t post at all on there for that very reason. I follow a very small circle of gaming people on Twitter, and that’s enough for me. People are free to link to my site on Reddit, though.[1]
kicks: Oh, for sure—those constant mobs in uproar.
But tell me—I wonder if you miss having access to Reddit comments on your posts. I would think that with your round-ups, most people would be very appreciative. Though perhaps some change to the game that week could spark tremendous arguments.
It looks like you prefer attaching a Twitter conversation to your posts. Was it a deliberate decision to have a blog without comments?
shackleshotgun: I don’t miss Reddit comments on my roundups because I never had them (as far as I know). If people have feedback for the site they are free to reach out to me either via DMs or email or mentioning me on Twitter.
It was a very deliberate choice to not have a comment section on the site. I didn’t see having a comment section as a productive thing for my site, and moderating it would be too time consuming. I don’t want people to stop visiting the site because of the comment section. Twitter makes for the best “comment section” because there the commenters can tag the developers/community managers with their thoughts on what was said.
kicks: Krikey. Comments as a liability! I have been lucky so far to have such good participation in my comments—but you clearly offer a perfectly useful read without them. I wonder if Twitter-just-for-comments is just a good way to treat Twitter in general.
The research you do on your round-ups is quite extensive—you must have fifty links you’re citing each week. Do you collect all of this on your own? Or do you take submissions through Twitter, Discord, Reddit and so on?
shackleshotgun: I do it all on my own. I have a system and a list of people to check in on each day. Once in a while people send me things I missed. I work very quickly so each summary takes max 30 mins out of my day. Having people submit things through avenues you’ve mentioned would take too long and make it a lot more arduous than it needs to be.
kicks: In a way, you operate kind of like a bot that is filtering through everything (from what I understand, you also try to snatch news out of podcast interviews) to distill it down to a summary. Our society has become accustomed to an algorithm doing this kind of job for us. However, your posts are written to be succinct and are very well-organized and laid out—with you writing and curating the heap of information.
shackleshotgun: I know that there have been some attempts to write bots for this kind of thing, but the developers often tweet/comment about things not related to the game. If you want to have a stream of info with only relevant things, you need a human behind it to filter it out.
kicks: This is a theme I keep seeing more and more. Humans as researchers and librarians on the Web, rather than just leaning back to let the bots passively feed us. I hope you enjoy doing the work—it might not be for everyone.
Did you have writing or research skills going into this project? Or did you just develop them as you went?
shackleshotgun: I didn’t have any related skills going into it. I studied programming and computer science for most of my life but had to go separate ways with that. When I started doing the roundups I was a Twitch streamer so I had a tiny audience on Twitter, and retweets from that audience helped lift the whole thing off. It’s been a fun learning experience.
kicks: Is it difficult for players out there to discover what you’re up to? In fact—any idea how most people find your blog?
shackleshotgun: Most people find me either via retweets of my summaries on Twitter, or YouTubers who have used my site for their videos shouting me out, or numerous podcasts I’ve been on.[2]
kicks: You started in a Google Doc—but moved to the blog last year. Was it difficult (technically) for you to start the blog? (Like: to get the design right, the layout and the organization.)
shackleshotgun: It was a relief to start the website, to be honest. By the time I started the website the google doc was a nightmare to use due to its size. There were some struggles with the site that are still ongoing.
Two big things that come to mind are the issues that come with any site that’s about archiving big quantities of information, and the design. Things are getting constantly patched in the game, which means info on the site becomes old, which in turn leads to a lot of issues in regards to organization. As for the design, I prefer usability and user experience over looks, but at the same time I want the site to look good and I still haven’t found that perfect mix between good design and great user experience.
So to summarize, starting it was very simple. Maintaining it is the actual challenge.
See more in her community focus. ↩︎
Some of her audio interviews can be found on DCP #95 or destinytruthcast #66. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A loss for civilization? Well, yeah, if you put it that way—civilization is going to roll on, regardless. I suppose you could say my effort is misplaced: perhaps better to work on helping our civilization survive, to live on, rather than trying to look to the past.
But, put another way: do I want to preserve a civilization that doesn’t embody any of the ideas that I care about? You’re probably right with your last line there—maybe I consider myself one who has ‘absorbed’ the ideas of my time and wants to ‘move on’ with those ideas in different ways. I can probably do this just fine without ready access to the source material—but I am glad that I was able to show Dont Look Back (1967) to a friend recently, rather than needing to just recount my recollection of it.
Definitely don’t want to save everything. Just some essential bits. And I shouldn’t try to be noble about it—just seems fun.
(And hey—kind of you to write up your thoughts, NK.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Averting our gaze from mainstream culture—cAN It bE DoNE?
Hahah, wow—it’s funny because I find this article to be a similar kind of frustrating read. A good read—perhaps like the Times article was for her—but very frustrating. I wonder: is acceptance by mainstream culture really seen as the ultimate, final, crucial reward?
(Particularly now that we live in an age where it’s clear that the previous generation of cultural winners—be it Jimi Hendrix or Harper Lee—is rapidly fading away, to be replaced by YouTubers, video game streamers, YA writers, reality stars. Isn’t the mainstream culture going to be very ruthless in its war for canonization?)
I mean I love the author’s ultimate point: here, I won’t summarize it, let’s just get into it.
We need a mass realization that pulls us out of this flooding culture. That is: the acknowledgment by powerful organizations that we do in fact engage more with original stories—it’s a fact, look it up—that lasting conversations do not come out of Twitter trends, and that diversity means diversity—more that is different, not more of the same differences. As one curator told the Times in the piece about older black artists getting their due, “There has been a whole parallel universe that existed that people had not tapped into.” Tap into it.
As h0p3 would say: preach it! Tap into it.
But the author spends the entire piece looking away from the underground—scrutinizing the fucking New York Times to show us the way, looking at the top 20 shows on Netflix, stats on buying habits on Amazon. If the concern is that our culture is spending all of their time on Netflix, Amazon and the Times—well, so is this article.
So when we go to ‘tap into it’—what is it? Where is this ‘parallel universe’ we’re looking for? Where does this culture go to look for it? Is it on Amazon and Twitter somewhere? Are we supposed to continue using Netflix and Google—but somehow spend our time on the back alleys of those services?
Is this a request to leave alone the front page of the New York Times and start with the back page? (So much simpler to turn to the back page of the corporeal printed Times than to do so online.)
Clearly, the article decries the entire makeup of these systems:
Per CJR, these algorithms are “taste-reflectors,” meaning they don’t affect taste the way critics do but simply reinforce your palate; there is little discovery here.
And how much discovery can there be, really, with the same critics occupying the same space?
Yesss! So go outside those neatly ordered corporate-approved spaces, yeah?
Let’s return to that final tap into it! paragraph. The phrase I want to look at is here: “the acknowledgement by powerful organizations.” Wait—so the tap into it! is meant… for them??
Are you asking the powerful organizations to—go outside themselves? Why? So they can continue to show us what’s legitimate? Because they are the authorities on what shit is actually cool?
I mean, yes, I’m not dense—the ‘powerful organizations’ are a massive pipeline of fame and currency—and this stuff can be gasoline to an artist. (Lord knows I want Boots Riley to keep it up—dammit, give the man what he needs!) But all of us out here, all us commoners, put together—we’re pure fuel, too. There was a time when it seemed that those very organizations were at the mercy of the buying public, earlier in this century when the entire system shook in fear of ‘disruption’.
And so, it feels like the article is just asking the mainstream to open a little wider, to give out a few more awards here and there, in lip service to the world of underappreciated, wonderful, unknown artists. (Black artists, in her case—but also in mine, because I want my mind blown by cool shit as much as any of you.) And, yeah, okay, maybe the ‘corpypastas’ might just throw us a bone.
However, I love the ‘parallel universe’ she refers to—that’s our unruly, unpredictable Web—an extension of the underground scenes, of the avant-garde, the mixtape traders, the world of the only critics that matter: our little group of friends. Those mixtapes blow up out here first. Out in our parallel universe: all of you out on your little blogs and wikis that I tap into each day. This world exists. It’s here, even if it faces its own doom on some days, in the face of resurgent mainstream culture.
Fuck the NYT, fuck Netflix—I’m reading you folks.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Sweet—well taken! I am not into the celebrity news or mainstream papes. But it still looks like 30% of this is lesser known goodshit. The whole layout and vibe is quality. Again, thankyou!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This month I’m digging into weekly link roundups.
E-mail newsletters (tinyletter, substack), along with weekly link summaries on Patreon, and podcasts or YouTube intros focused on ‘community news’—these are very popular types of tiny directories that I have been overlooking. Watching people like h0p3, Eli Mellen and Joe Jennett dump these kinds of periodic link collections, I’m convinced that they are a crucial support system for blog/wiki writers (Hypertexting).
Some things I’ve observed while hunting around for link roundups:
Some communities are really good at this kind of thing. For example, see the weekly ‘heavy metal preview’ put out by Not Part Of Your Scene. People want to find new songs, bands want their news songs to be heard, and the blogs want to sift through it all and find the gems—this just cuts right to it.
The best roundups take the time to organize, add some helpful commentary and just make it all look nice and readable. Eli’s got a good thing or Stephanie Walter’s ‘pixels of the week’. I will cover this more extensively going forward. (Another interesting one: No Time To Play, takes the form of short essays on gaming.)
The e-mail newsletter software out there is doing a pretty good job. Take The Go Gazelle, which uses Revue to publish its newsletter. It looks good—and I really appreciate that it embeds Tweets. (Relevant: ‘Tantek liked a post on Twitter’.)
Roundups lend themselves to group collaboration. Look at mega-roundups like the one done by Eidolon Classics on their Patreon. Would love to see this kind of weekly superpost on the topics I care about.
These are also incredibly common on micro.blog—is there a roundup of the roundups?
Some interesting ‘forks’/‘variants’ of the roundup:
My Week in Objects: just pictures of… a bag, a pencil box. (via @joelhamill)
Gwern’s Newsletter: Very detailed monthly round-up. The drafts for the newsletter are also fleshed out in public. (Linked from Guzey, which h0p3 pointed out.)
I have more work to do, discovering innovations out there. But I have some good interviews coming up on the topic and will be doing another Let Me Link to You on the topic.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The fact that links like cosmic.voyage and quariety.com are buried in this dump is just proof that you’re on fire lately, Eli. The round-ups are brilliant, the digital abysstapes are fascinating—just want to encourage you to keep it all on.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Could we use RSS for more?
I’m wondering lately if there’s a better way to do ‘readers’. Like you say, once you are monitoring 100s of sites, it’s disgusting to log in each day and see 100s of unread posts. I’m wondering if there’s something that could give me an overview of all the activity that’s going on out there, so I can then decide what to read. No ‘unread’ counts, no notifications. And, rather than having a big feed of recent activity, have a list of all the ‘bloggers’/‘writers’ so I can see who’s active—maybe with a little graph of how much is going on with them, maybe a list of recent post titles or something…
Makes me think of the Peach social network, where the ‘inbox’ was names of people who had updated—you could then go in and view their stuff. It was never presented as a big newsfeed or a big inbox of individual posts.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Idea: gang up to cache classic websites.
This is just a zygotic bit of a thought that I’ve been having. A group that would band together to share classic websites (likely on the ‘dat’ network), perhaps as if they were abandonware or out-of-print books. Many of the early net.art sites have been kept up because they have university support; many other sites disappear and simply don’t function on The Internet Archive.
(To illustrate how even a major art piece can go down, Pharrell’s 24 Hours of Happy interactive music video—yeah. that link is broken. You can see kind of see it on YouTube, but… the hypertext enthusiast in me wants to see it live on in its original form.)
Some sites that I really need to reconstruct:
Room of 1,000 Snakes. This game hasn’t been playable for a year or two now. I promised a friend I would work on this. (This is an issue with Unity Web Player going defunct.)
The Woodcutter. Careful, redirects. This site was a huge deal for me when I was younger. When I started href.cool, it was fine—and had been fine for like fifteen years!—and then it suddenly broke. I think it can be reconstructed from The Internet Archive.
Fly Guy. Moved to the App Store??
SARDINE MAGOZINE. Charlie is gone now—so I’ve already started doing this.
SMASH TV. This suddenly disappeared recently, but I think it’s been restored to YouTube now—I need my copies.
Sites I need to back up; feels like their day is nigh:
1080plus. I’ve already been through losing this once.
Bear Stearns Bravo. Yeah, I think so. (This Is My Milwaukee could be recreated too.)
“Like a Rolling Stone.” Similar story to “24 Hours of Happy”—this kind of disappears for months at a time, but seems to work as of March 2019.
Frog Fractions. This one is probably too adored to disappear—still.
Everything in my Real/Person category. These personal pages can easily float away suddenly.
Of course, I’d love to get the point where I have a cached copy of everything at href.cool—there are several Tumblrs in there and Blogspots. I’m not as worried with those, because The Internet Archive does a fine job of keeping them relatively intact. But if a YouTube channel disappears, it’s gone to us.
Along similar lines, I have been trying to message the creators of the Byte app—not the hyped Vine 2, but the original Byte that was basically like an underground vaporwave social network from 2014-2016. I want to secure a dump of the public Bytes from that era. It was sick.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I don’t know Inoreader—what is keeping you from paying for it? Is it not worth paying for? I also wonder what you are looking for in a reader. I mean if it reads RSS—what else is there? (I don’t understand using a reader and am looking for some enlightenment. Don’t think you’ve written about this yet—is there something you’re looking for beyond basic notification that a new post/comment has materialized? To me, they seem like e-mail clients—not much to it.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.


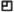

































{kind=link}
Reply: Nine Years of Link Rot
Always glad to hear your perspective on this. I am working on my own archival system for href.cool - I’ve already lost thewoodcutter.com and humdrum.life. (Been going for one year.)
My approach right now is to verify all of the links weekly by comparing last week’s title tag on that page to this week’s title tag. I’ve had to tweak this a bit - for PDF links or for pages that have dynamically generated titles - I can opt to use ‘content-length’ header or a meta tag. (Of course, the old title can be spoofed, so I’m going to improve my algorithm over time.)
I wish I had a way of seeding sites with you. I imagine we have some crossover on interests and would also love to contribute bandwidth - as would some of your other readers I’m sure.